Beim Training großer Sprachmodelle (LLM) ist der Checkpoint-Mechanismus von entscheidender Bedeutung, da er große Verluste durch Trainingsunterbrechungen effektiv vermeiden kann. Herkömmliche Checkpoint-Systeme weisen jedoch häufig E/A-Engpässe auf und sind ineffizient. Zu diesem Zweck haben Wissenschaftler von ByteDance und der University of Hong Kong ein neues Checkpoint-System namens ByteCheckpoint vorgeschlagen, das die Effizienz des LLM-Trainings erheblich verbessern kann.
In einer digitalen Welt, die von Daten und Algorithmen dominiert wird, ist jeder Schritt des Wachstums der künstlichen Intelligenz untrennbar mit einem Schlüsselelement verbunden – dem Kontrollpunkt. Stellen Sie sich vor, wenn Sie ein umfangreiches Sprachmodell trainieren, das die Gedanken von Menschen verstehen und Fragen fließend beantworten kann, ist dieses Modell äußerst intelligent, aber auch ein großer Fresser und erfordert enorme Rechenressourcen, um es zu füttern. Wenn es während des Trainingsprozesses zu einem plötzlichen Stromausfall oder Hardwarefehler kommt, ist der Verlust enorm. Zu diesem Zeitpunkt ist der Kontrollpunkt wie eine Zeitmaschine, die es ermöglicht, dass alles in den vorherigen sicheren Zustand zurückkehrt und unerledigte Aufgaben fortgesetzt werden.
Allerdings erforderte auch die Zeitmaschine selbst eine sorgfältige Konstruktion. Wissenschaftler von ByteDance und der University of Hong Kong haben uns in der Arbeit „ByteCheckpoint: A Unified Checkpointing System for LLM Development“ ein neues Checkpoint-System vorgestellt – ByteCheckpoint. Es handelt sich nicht nur um ein einfaches Backup-Tool, sondern auch um ein Artefakt, das die Trainingseffizienz großer Sprachmodelle erheblich verbessern kann.
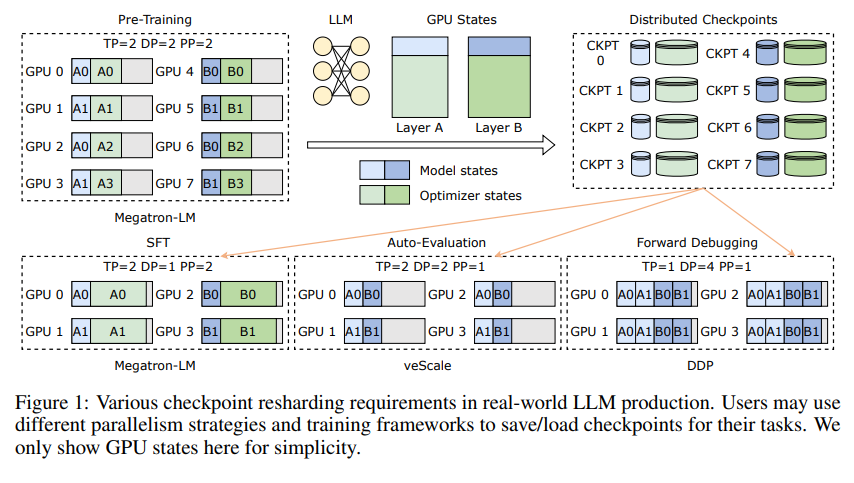
Zunächst müssen wir die Herausforderungen verstehen, denen sich große Sprachmodelle (LLMs) gegenübersehen. Der Grund für die Größe dieser Modelle liegt darin, dass sie riesige Informationsmengen verarbeiten und speichern müssen, was zu Problemen wie hohen Schulungskosten, großem Ressourcenverbrauch und schwacher Fehlertoleranz führt. Tritt eine Fehlfunktion auf, kann dies dazu führen, dass das Training über einen längeren Zeitraum unbefriedigend verläuft.
Das Checkpoint-System ist wie eine Momentaufnahme des Modells und speichert den Status regelmäßig während des Trainingsprozesses, sodass es auch bei einem Fehler schnell auf den neuesten Status zurückgesetzt werden kann und Verluste reduziert werden. Allerdings leiden bestehende Checkpoint-Systeme häufig unter Ineffizienzen aufgrund von I/O-Engpässen (Eingabe/Ausgabe) bei der Verarbeitung großer Modelle.
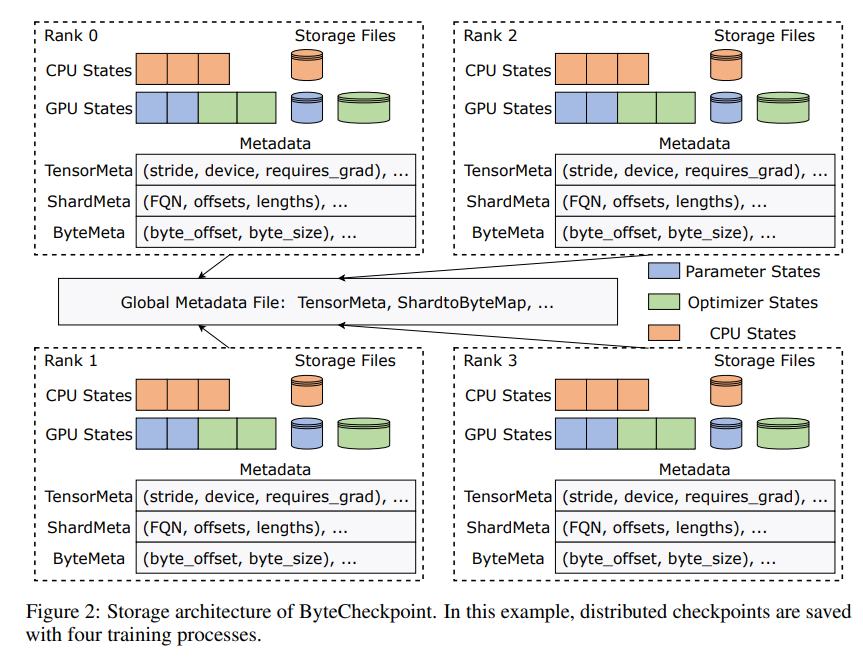
Die Innovation von ByteCheckpoint liegt in der Einführung einer neuartigen Speicherarchitektur, die Daten und Metadaten trennt und Checkpoints unter verschiedenen parallelen Konfigurationen und Trainings-Frameworks flexibler handhabt. Noch besser: Es unterstützt das automatische Online-Resharding von Prüfpunkten, wodurch Prüfpunkte dynamisch angepasst werden können, um sie an unterschiedliche Hardwareumgebungen anzupassen, ohne das Training zu unterbrechen.
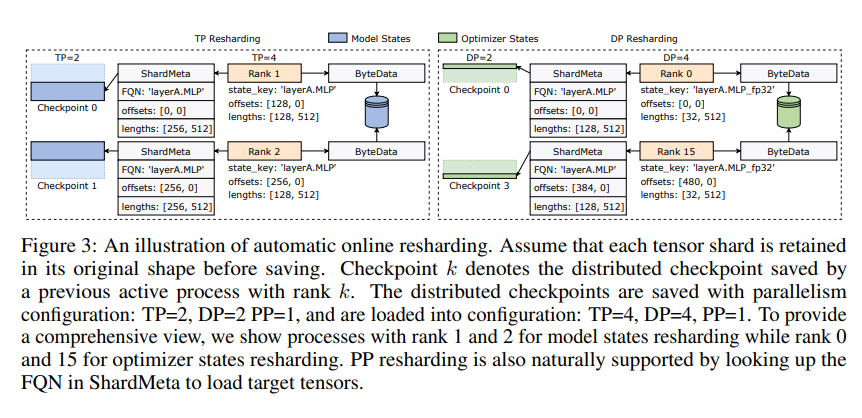
ByteCheckpoint führt außerdem eine Schlüsseltechnologie ein – das asynchrone Tensor-Merging. Dadurch können Tensoren, die auf verschiedenen GPUs ungleichmäßig verteilt sind, effizient verarbeitet werden, wodurch sichergestellt wird, dass die Integrität und Konsistenz des Modells beim erneuten Checkpointing nicht beeinträchtigt wird.
Um die Geschwindigkeit des Speicherns und Ladens von Checkpoints zu verbessern, integriert ByteCheckpoint außerdem eine Reihe von Maßnahmen zur E/A-Leistungsoptimierung, wie z. B. eine ausgefeilte Save/Load-Pipeline, einen Ping-Pong-Speicherpool, Workload-balanciertes Speichern und null-redundantes Laden usw. , was die Wartezeit während des Trainingsprozesses erheblich verkürzt.
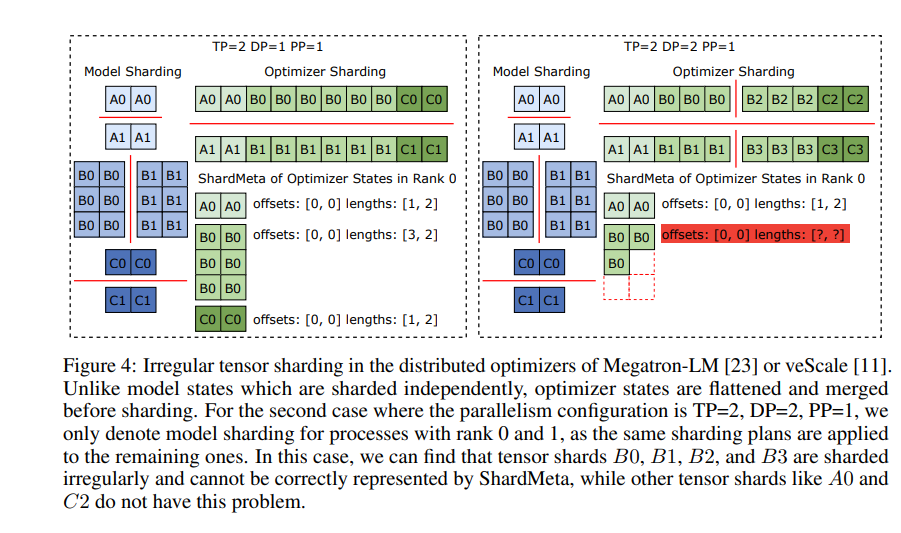
Durch experimentelle Verifizierung werden die Checkpoint-Speicher- und Ladegeschwindigkeiten von ByteCheckpoint im Vergleich zu herkömmlichen Methoden um das Dutzende bzw. sogar Hundertfache erhöht, wodurch die Trainingseffizienz großer Sprachmodelle erheblich verbessert wird.
ByteCheckpoint ist nicht nur ein Checkpoint-System, sondern auch ein leistungsstarker Assistent im Trainingsprozess großer Sprachmodelle. Es ist der Schlüssel zu einem effizienteren und stabileren KI-Training.
Papieradresse: https://arxiv.org/pdf/2407.20143
Der Herausgeber von Downcodes fasst zusammen: Das Aufkommen von ByteCheckpoint löst das Problem der geringen Checkpoint-Effizienz im LLM-Training und bietet starke technische Unterstützung für die KI-Entwicklung. Es lohnt sich, darauf zu achten!