Die große Veröffentlichung der Meta Company! Open Source ist sein neuestes großes Sprachmodell Llama 3.1 405B mit einem Parametervolumen von bis zu 128 Milliarden, und seine Leistung ist bei mehreren Aufgaben mit GPT-4 vergleichbar. Nach einem Jahr sorgfältiger Vorbereitung, von der Projektplanung bis zur abschließenden Überprüfung, werden die Modelle der Llama 3-Serie endlich der Öffentlichkeit präsentiert. Diese Open Source umfasst nicht nur das Modell selbst, sondern auch seine optimierte Datenverarbeitung vor dem Training, die Datenqualitätssicherung nach dem Training und eine effiziente Quantifizierungstechnologie, um den Rechenaufwand zu reduzieren und die Verwendung für Entwickler zu vereinfachen. Der Herausgeber von Downcodes wird die Verbesserungen und Highlights von Llama 3.1 405B ausführlich erläutern.
Gestern Abend kündigte Meta die Open Source seines neuesten großen Sprachmodells Llama3.1 405B an. Diese große Neuigkeit markiert, dass die Modelle der Llama3-Serie nach einem Jahr sorgfältiger Vorbereitung, von der Projektplanung bis zur endgültigen Überprüfung, endlich der Öffentlichkeit vorgestellt wurden.
Llama3.1405B ist ein mehrsprachiges Tool-Nutzungsmodell mit 128 Milliarden Parametern. Nach dem Vortraining mit einer Kontextlänge von 8 KB wird das Modell mit einer Kontextlänge von 128 KB weiter trainiert. Laut Meta ist die Leistung dieses Modells bei mehreren Aufgaben mit der des branchenführenden GPT-4 vergleichbar.
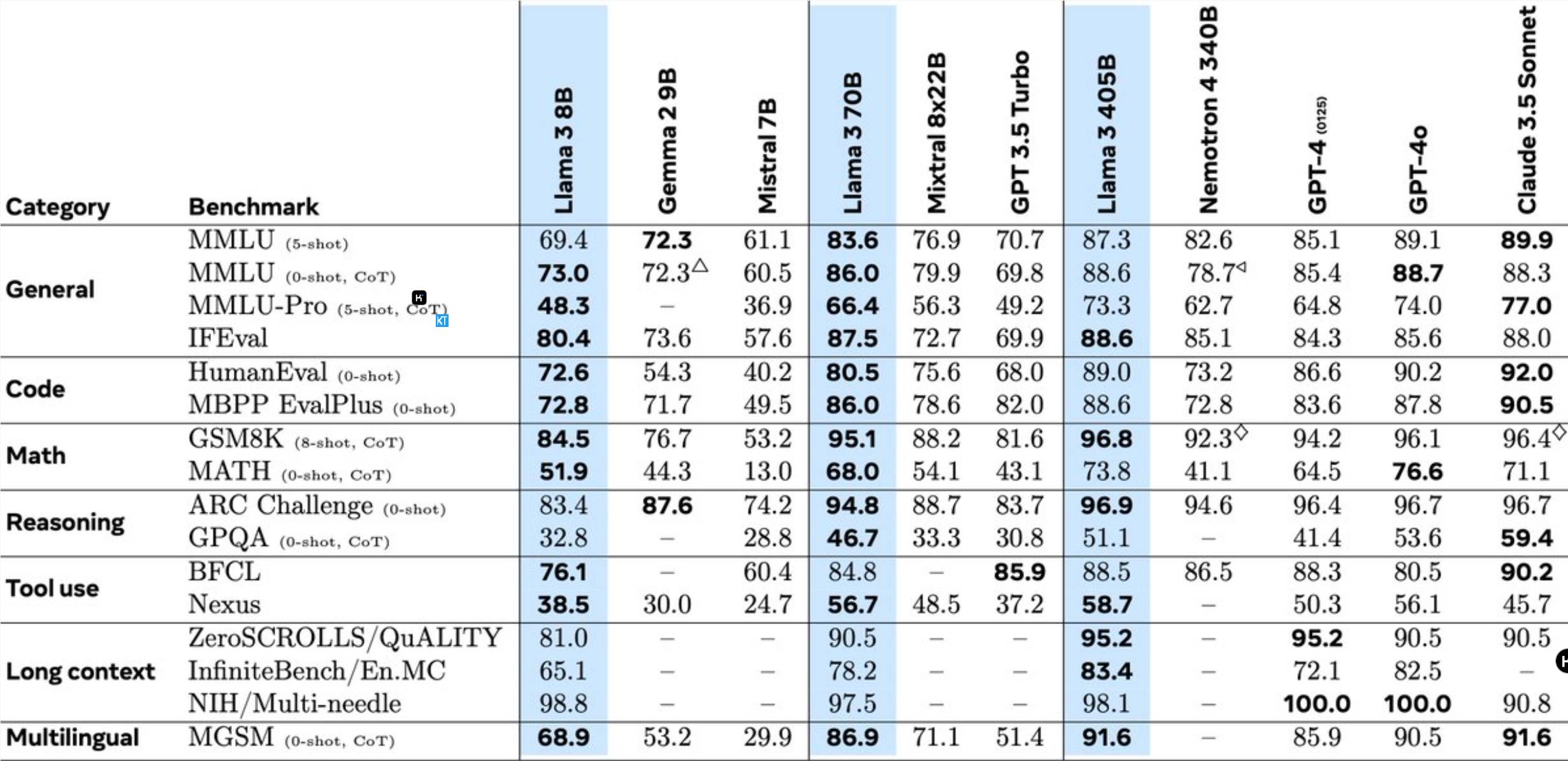
Im Vergleich zum vorherigen Llama-Modell wurde Meta in vielen Aspekten optimiert:
Das Vortraining des 405B-Modells ist eine große Herausforderung und umfasst 15,6 Billionen Token und 3,8x10^25 Gleitkommaoperationen. Zu diesem Zweck optimierte Meta die gesamte Trainingsarchitektur und nutzte mehr als 16.000 H100-GPUs.
Um die Massenproduktionsinferenz des 405B-Modells zu unterstützen, quantisierte Meta es von 16-Bit (BF16) auf 8-Bit (FP8), wodurch der Rechenaufwand erheblich reduziert wurde und ein einzelner Serverknoten die Ausführung des Modells ermöglichen konnte.
Darüber hinaus verwendet Meta das 405B-Modell, um die Post-Training-Qualität der 70B- und 8B-Modelle zu verbessern. In der Post-Training-Phase verfeinerte das Team das Chat-Modell durch mehrere Runden von Ausrichtungsprozessen, einschließlich überwachter Feinabstimmung (Supervised Fine Tuning, SFT), Ablehnungsstichproben und direkter Präferenzoptimierung. Es ist erwähnenswert, dass die meisten SFT-Proben mithilfe synthetischer Daten generiert werden.
Llama3 integriert außerdem Bild-, Video- und Sprachfunktionen und nutzt einen kombinierten Ansatz, um dem Modell die Erkennung von Bildern und Videos zu ermöglichen und die Sprachinteraktion zu unterstützen. Diese Funktionen befinden sich jedoch noch in der Entwicklung und wurden noch nicht offiziell veröffentlicht.
Meta hat außerdem seine Lizenzvereinbarung aktualisiert, um Entwicklern die Nutzung der Ausgabe des Llama-Modells zur Verbesserung anderer Modelle zu ermöglichen.
Forscher von Meta sagten: Es ist äußerst spannend, mit Top-Talenten der Branche an der Spitze der KI zu arbeiten und Forschungsergebnisse offen und transparent zu veröffentlichen. Wir freuen uns auf die Innovation, die Open-Source-Modelle mit sich bringen, und auf das Potenzial für zukünftige Modelle der Llama-Serie!
Diese Open-Source-Initiative wird zweifellos neue Chancen und Herausforderungen für den KI-Bereich mit sich bringen und die Weiterentwicklung der Technologie großer Sprachmodelle fördern.
Die Open Source von Llama 3.1 405B wird die Weiterentwicklung der Technologie großer Sprachmodelle erheblich vorantreiben und mehr Möglichkeiten in den KI-Bereich bringen. Wir freuen uns darauf, dass Entwickler weitere tolle Anwendungen auf Basis dieses Modells erstellen!