Die Verbesserung der Effizienz großer Sprachmodelle war schon immer ein Forschungsschwerpunkt im Bereich der künstlichen Intelligenz. Kürzlich haben Forschungsteams von Aleph Alpha, der Technischen Universität Darmstadt und anderen Institutionen eine neue Methode namens T-FREE entwickelt, die die Betriebseffizienz großer Sprachmodelle deutlich verbessert. Diese Methode reduziert die Anzahl der Einbettungsschichtparameter durch die Verwendung von Zeichentripeln für eine spärliche Aktivierung und modelliert effektiv die morphologische Ähnlichkeit zwischen Wörtern. Sie reduziert den Verbrauch von Rechenressourcen erheblich und stellt gleichzeitig die Modellleistung sicher. Diese bahnbrechende Technologie eröffnet neue Möglichkeiten für die Anwendung großer Sprachmodelle.
Das Forschungsteam hat kürzlich eine aufregende neue Methode namens T-FREE eingeführt, die es ermöglicht, die Betriebseffizienz großer Sprachmodelle in die Höhe zu treiben. Wissenschaftler von Aleph Alpha, der TU Darmstadt, hessian.AI und dem Deutschen Forschungszentrum für Künstliche Intelligenz (DFKI) haben gemeinsam diese erstaunliche Technologie auf den Markt gebracht, deren vollständiger Name „Tagger-freie Sparse-Repräsentation, speichereffiziente Einbettung ist möglich“ lautet.
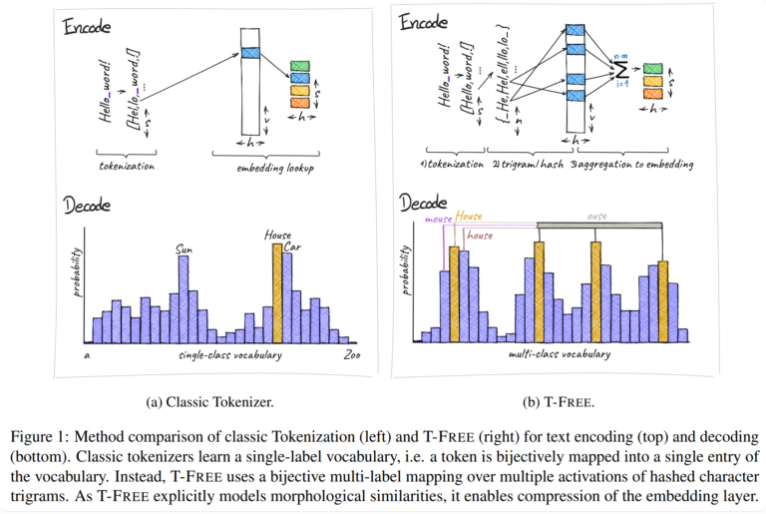
Traditionell verwenden wir Tokenizer, um Text in eine numerische Form umzuwandeln, die Computer verstehen können, aber T-FREE hat einen anderen Weg gewählt. Es verwendet Zeichentripel, die wir „Triples“ nennen, um Wörter durch spärliche Aktivierung direkt in das Modell einzubetten. Durch diesen innovativen Schritt wurde die Anzahl der Parameter in der Einbettungsschicht um erstaunliche 85 % oder mehr reduziert, während die Leistung des Modells bei der Bearbeitung von Aufgaben wie Textklassifizierung und Fragenbeantwortung überhaupt nicht beeinträchtigt wurde.
Ein weiteres Highlight von T-FREE ist, dass es morphologische Ähnlichkeiten zwischen Wörtern sehr geschickt modelliert. Genau wie die Wörter „Haus“, „Häuser“ und „Haushalt“, die uns im täglichen Leben häufig begegnen, kann T-FREE diese ähnlichen Wörter im Modell effektiver darstellen. Die Forscher glauben, dass ähnliche Wörter näher beieinander eingebettet werden sollten, um höhere Komprimierungsraten zu erreichen. Daher reduziert T-FREE nicht nur die Größe der Einbettungsschicht, sondern auch die durchschnittliche Codierungslänge von Text um 56 %.
Erwähnenswert ist auch, dass T-FREE besonders gut beim Transferlernen zwischen verschiedenen Sprachen abschneidet. In einem Experiment verwendeten die Forscher ein Modell mit 3 Milliarden Parametern, das zunächst auf Englisch und dann auf Deutsch trainiert wurde, und stellten fest, dass T-FREE weitaus anpassungsfähiger war als herkömmliche Tagger-basierte Methoden.
Allerdings bleiben die Forscher mit ihren aktuellen Ergebnissen bescheiden. Sie geben zu, dass Experimente bisher auf Modelle mit bis zu 3 Milliarden Parametern beschränkt waren und weitere Auswertungen an größeren Modellen und größeren Datensätzen für die Zukunft geplant sind.
Das Aufkommen der T-FREE-Methode liefert neue Ideen zur Verbesserung der Effizienz großer Sprachmodelle. Ihre Vorteile bei der Reduzierung der Rechenkosten und der Verbesserung der Modellleistung verdienen Aufmerksamkeit. Zukünftige Forschungsrichtungen werden sich auf die Verifizierung größerer Modelle und Datensätze konzentrieren, um den Anwendungsbereich von T-FREE weiter zu erweitern und die weitere Entwicklung der Technologie groß angelegter Sprachmodelle zu fördern. Man geht davon aus, dass T-FREE in naher Zukunft in weiteren Bereichen eine wichtige Rolle spielen wird.