Kunlun Technology gab kürzlich bekannt, dass zwei von ihm entwickelte Belohnungsmodelle, Skywork-Reward-Gemma-2-27B und Skywork-Reward-Llama-3.1-8B, hervorragende Ergebnisse bei RewardBench erzielt haben, wobei das 27B-Modell die Liste anführt. Dies bedeutet, dass Kunlun Wanwei einen großen Durchbruch auf dem Gebiet der künstlichen Intelligenz erzielt hat, insbesondere in der Forschung und Entwicklung von Belohnungsmodellen, und neue technische Unterstützung für das Training großer Sprachmodelle bereitstellt. Belohnungsmodelle sind beim verstärkenden Lernen von entscheidender Bedeutung, da sie das Modelllernen steuern und Inhalte generieren können, die eher den menschlichen Vorlieben entsprechen. Das Modell von Kunlun Wanwei verfügt über einzigartige Vorteile bei der Datenauswahl und dem Modelltraining, wodurch es in Aspekten wie Dialog und Sicherheit gute Leistungen erbringt und insbesondere bei der Verarbeitung schwieriger Proben starke Fähigkeiten zeigt.
Kunlun Wanwei Technology Co., Ltd. gab kürzlich bekannt, dass zwei neue vom Unternehmen entwickelte Belohnungsmodelle, Skywork-Reward-Gemma-2-27B und Skywork-Reward-Llama-3.1-8B, bei RewardBench, dem international anerkannten Belohnungsmodell, gut abgeschnitten haben Unter ihnen gewann das Modell Skywork-Reward-Gemma-2-27B den Spitzenplatz und wurde von den Verantwortlichen von RewardBench hoch gelobt.
Das Belohnungsmodell nimmt eine zentrale Position beim verstärkenden Lernen ein, indem es die Leistung des Agenten in verschiedenen Zuständen bewertet und Belohnungssignale bereitstellt, um den Lernprozess des Agenten zu steuern, damit er in einer bestimmten Umgebung die optimale Wahl treffen kann. Beim Training großer Sprachmodelle spielt das Belohnungsmodell eine besonders wichtige Rolle, da es dem Modell hilft, Inhalte genauer zu verstehen und zu generieren, die den menschlichen Vorlieben entsprechen.
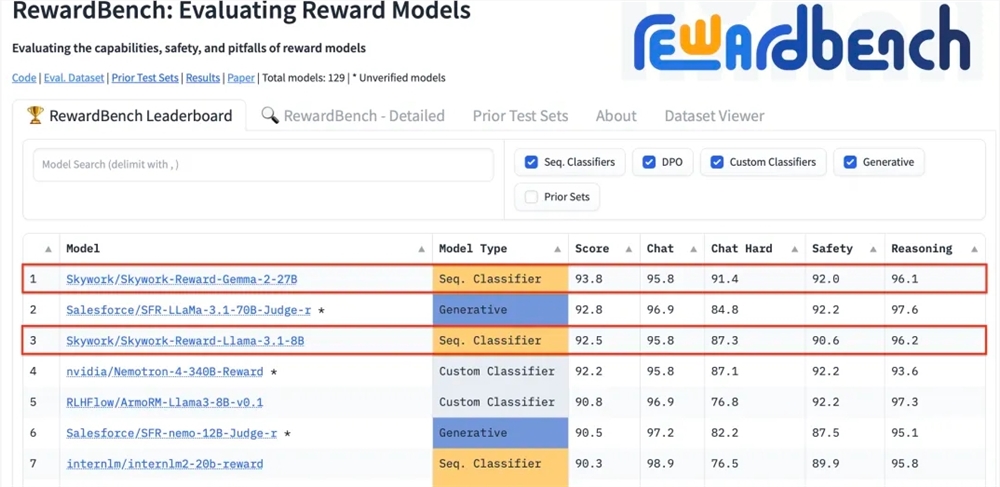
RewardBench ist eine Benchmark-Liste, die speziell die Wirksamkeit von Belohnungsmodellen in großen Sprachmodellen bewertet. Sie bewertet Modelle umfassend anhand mehrerer Aufgaben, einschließlich Dialog, Argumentation und Sicherheit. Der Testdatensatz dieser Liste besteht aus Tripeln bestehend aus Aufforderungswörtern, ausgewählten Antworten und abgelehnten Antworten. Er wird verwendet, um zu testen, ob das Belohnungsmodell die ausgewählten Antworten korrekt unter den abgelehnten Antworten einordnen kann, bevor die Antwort abgelehnt wird .
Das Skywork-Reward-Modell von Kunlun Wanwei basiert auf sorgfältig ausgewählten, teilweise geordneten Datensätzen und relativ kleinen Basismodellen. Im Vergleich zu bestehenden Belohnungsmodellen stammen seine teilweise geordneten Daten nur aus öffentlichen Daten im Internet und werden durch spezifische Filter gefiltert -Qualitätspräferenzdatensätze. Die Daten decken ein breites Themenspektrum ab, darunter Sicherheit, Mathematik und Code, und werden manuell überprüft, um die Objektivität der Daten und die Bedeutung von Belohnungslücken sicherzustellen.
Nach dem Test zeigte das Belohnungsmodell von Kunlun Wanwei eine hervorragende Leistung in Bereichen wie Dialog und Sicherheit. Insbesondere bei schwierigen Proben lieferte nur das Skywork-Reward-Gemma-2-27B-Modell korrekte Vorhersagen. Dieser Erfolg unterstreicht Kunlun Wanweis technische Stärke und Innovationsfähigkeit im globalen KI-Bereich und bietet auch neue Möglichkeiten für die Entwicklung und Anwendung der KI-Technologie.
27B-Modelladresse:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
8B-Modelladresse:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
Die hervorragende Leistung von Kunlun Wanwei bei RewardBench zeigt seine führende Technologie- und Innovationsfähigkeit im Bereich der künstlichen Intelligenz. Wir freuen uns darauf, in Zukunft weitere Durchbrüche zu erzielen.