Nous Research bringt den revolutionären KI-Trainingsoptimierer DisTrO auf den Markt und durchbricht damit die Situation, in der das Training großer KI-Modelle auf große Konzernriesen beschränkt ist. DisTrO kann die Menge der Datenübertragung zwischen mehreren GPUs erheblich reduzieren und KI-Modelle auch in gewöhnlichen Netzwerkumgebungen effizient trainieren. Dadurch wird die Schwelle für das KI-Modelltraining erheblich gesenkt und es wird mehr Einzelpersonen und Institutionen ermöglicht, an der Entwicklung der KI-Technologie teilzunehmen und Entwicklung im Gange. Es wird erwartet, dass diese innovative Technologie das Forschungs- und Entwicklungsmodell im Bereich KI völlig verändern und die Popularisierung und Entwicklung der KI-Technologie fördern wird.
Kürzlich brachte das Forschungsteam von Nous Research aufregende Neuigkeiten in die Technologiewelt. Sie brachten einen neuen Optimierer namens DisTrO (Distributed Internet Training) auf den Markt. Die Geburt dieser Technologie bedeutet, dass leistungsstarke KI-Modelle nicht nur das Patent großer Unternehmen sind, sondern dass auch normale Menschen die Möglichkeit haben, ihren eigenen Computer für effizientes Training zu Hause zu nutzen.
Der Zauber von DisTrO besteht darin, dass es die Informationsmenge, die beim Training eines KI-Modells zwischen mehreren Grafikprozessoren (GPUs) übertragen werden muss, erheblich reduzieren kann. Durch diese Innovation können leistungsstarke KI-Modelle unter normalen Netzwerkbedingungen trainiert werden und es sogar Einzelpersonen oder Institutionen auf der ganzen Welt ermöglichen, ihre Kräfte zu bündeln, um gemeinsam KI-Technologie zu entwickeln.
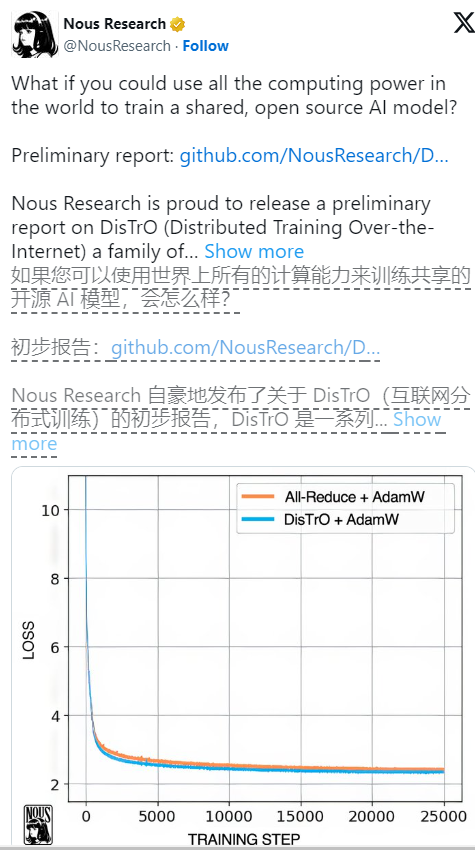
Laut einem technischen Artikel von Nous Research ist die Effizienzsteigerung von DisTrO 857-mal höher als die eines herkömmlichen All-Reduce-Algorithmus Der Schritt wird ebenfalls von 74,4 GB auf 86,8 MB reduziert. Solche Verbesserungen machen die Ausbildung nicht nur schneller und kostengünstiger, sondern bedeuten auch, dass mehr Menschen die Möglichkeit haben, an diesem Bereich teilzunehmen.
Nous Research gab auf seiner sozialen Plattform an, dass sich Forscher und Institutionen durch DisTrO nicht mehr auf ein bestimmtes Unternehmen verlassen müssen, um den Ausbildungsprozess zu verwalten und zu kontrollieren, was ihnen mehr Freiheit für Innovationen und Experimente bietet. Dieses offene Wettbewerbsumfeld fördert den technischen Fortschritt und kommt letztendlich der gesamten Gesellschaft zugute.
Beim KI-Training sind die Hardwareanforderungen oft unerschwinglich. Insbesondere leistungsstarke Nvidia-GPUs sind in dieser Zeit immer knapper und teurer geworden, und nur einige finanzkräftige Unternehmen können sich die Belastung einer solchen Schulung leisten. Die Philosophie von Nous Research ist jedoch genau das Gegenteil. Sie setzen sich dafür ein, das Training von KI-Modellen zu geringeren Kosten der Öffentlichkeit zugänglich zu machen und mehr Menschen die Teilnahme zu ermöglichen.
DisTrO reduziert den Kommunikationsaufwand um vier bis fünf Größenordnungen, indem es die Notwendigkeit einer vollständigen Gradientensynchronisierung zwischen GPUs verringert. Diese Innovation ermöglicht es, KI-Modelle auf langsamere Internetverbindungen zu trainieren, wobei die für viele Haushalte heute problemlos zugänglichen Download- und 10 Mbit/s-Upload-Geschwindigkeiten von 100 Mbit/s ausreichend sind.
In vorläufigen Tests mit dem großen Sprachmodell Llama2 von Meta zeigte DisTrO vergleichbare Trainingsergebnisse wie herkömmliche Methoden und reduzierte gleichzeitig den Kommunikationsaufwand deutlich. Die Forscher sagten auch, dass sie, obwohl sie bisher nur an kleineren Modellen getestet wurden, vorläufig spekulieren, dass mit zunehmender Größe des Modells die Reduzierung der Kommunikationsanforderungen deutlicher ausfallen und sogar das 1.000- bis 3.000-fache erreichen könnte.
Es ist erwähnenswert, dass DisTrO zwar das Training flexibler macht, aber immer noch auf GPU-Unterstützung angewiesen ist. Diese GPUs müssen nun jedoch nicht mehr am selben Ort gesammelt werden, sondern können über die ganze Welt verteilt werden und über das normale Internet zusammenarbeiten. Wir haben gesehen, dass DisTrO bei strengen Tests mit 32 H100-GPUs in der Lage war, mit der traditionellen AdamW+All-Reduce-Methode hinsichtlich der Konvergenzgeschwindigkeit mitzuhalten, die Kommunikationsanforderungen jedoch deutlich reduzierte.
DisTrO eignet sich nicht nur für große Sprachmodelle, sondern kann auch zum Trainieren anderer Arten von KI wie Bilderzeugungsmodellen verwendet werden. Die zukünftigen Anwendungsaussichten sind spannend. Darüber hinaus kann DisTrO durch die Verbesserung der Trainingseffizienz auch die Umweltauswirkungen des KI-Trainings verringern, da es die Nutzung der vorhandenen Infrastruktur optimiert und den Bedarf an großen Rechenzentren verringert.
Durch DisTrO fördert Nous Research nicht nur technologische Fortschritte in der KI-Ausbildung, sondern fördert auch ein offeneres und flexibleres Forschungsökosystem, das unbegrenzte Möglichkeiten für die zukünftige KI-Entwicklung eröffnet.
Referenz: https://venturebeat.com/ai/this-could-change-everything-nous-research-unveils-new-tool-to-train-powerful-ai-models-with-10000x-efficiency/
Das Aufkommen von DisTrO läutet den Demokratisierungsprozess der KI-Ausbildung ein, senkt die Schwelle für die Teilnahme, fördert die schnelle Entwicklung und weit verbreitete Anwendung der KI-Technologie und bringt neue Vitalität und unbegrenzte Möglichkeiten in den KI-Bereich. Wir gehen davon aus, dass DisTrO in Zukunft weitere Überraschungen für die Entwicklung der KI bringen wird.