Die Forschung des Mamba-Teams hat einen Durchbruch erzielt. Sie haben das große Transformer-Modell Llama erfolgreich in ein effizienteres Mamba-Modell „destilliert“. Diese Forschung kombiniert geschickt Technologien wie progressive Destillation, überwachte Feinabstimmung und Richtungspräferenzoptimierung und entwirft einen neuen Inferenzdekodierungsalgorithmus, der auf der einzigartigen Struktur des Mamba-Modells basiert und die Inferenzgeschwindigkeit des Modells erheblich verbessert, ohne die Leistung zu gewährleisten Effizienzsteigerung wurde ohne Einbußen erreicht. Diese Forschung reduziert nicht nur die Kosten für groß angelegte Modellschulungen, sondern liefert auch neue Ideen für die zukünftige Modelloptimierung, die eine wichtige akademische Bedeutung und einen hohen Anwendungswert haben.
Kürzlich ist die Forschung des Mamba-Teams ein Hingucker: Forscher von Universitäten wie Cornell und Princeton haben Llama, ein großes Transformer-Modell, erfolgreich in Mamba „destilliert“ und einen neuen Inferenzdekodierungsalgorithmus entwickelt, der die Modellinferenzgeschwindigkeit erheblich verbesserte.
Ziel der Forscher ist es, aus einem Lama eine Mamba zu machen. Warum tun Sie das? Weil das Training eines großen Modells von Grund auf teuer ist und Mamba seit seiner Einführung große Aufmerksamkeit erregt hat, aber nur wenige Teams tatsächlich selbst große Mamba-Modelle trainieren. Obwohl es einige seriöse Varianten auf dem Markt gibt, wie zum Beispiel Jamba von AI21 und Hybrid Mamba2 von NVIDIA, steckt in den vielen erfolgreichen Transformer-Modellen eine Fülle von Wissen. Wenn wir dieses Wissen nutzen und den Transformer auf Mamba abstimmen könnten, wäre das Problem gelöst.
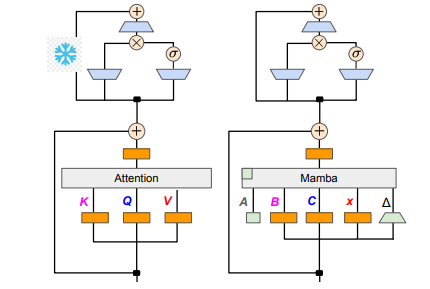
Das Forschungsteam erreichte dieses Ziel erfolgreich durch die Kombination verschiedener Methoden wie progressiver Destillation, überwachter Feinabstimmung und gerichteter Präferenzoptimierung. Es ist erwähnenswert, dass auch die Geschwindigkeit entscheidend ist, ohne dass die Leistung beeinträchtigt wird. Mamba bietet offensichtliche Vorteile beim Denken über lange Sequenzen, und Transformer verfügt auch über Lösungen zur Beschleunigung des Denkens, wie z. B. spekulative Dekodierung. Da die einzigartige Struktur von Mamba diese Lösungen nicht direkt anwenden kann, haben die Forscher speziell einen neuen Algorithmus entwickelt und ihn mit Hardwarefunktionen kombiniert, um eine Mamba-basierte spekulative Dekodierung zu implementieren.
Schließlich konnten die Forscher Zephyr-7B und Llama-38B erfolgreich in lineare RNN-Modelle umwandeln, und ihre Leistung war mit dem Standardmodell vor der Destillation vergleichbar. Der gesamte Trainingsprozess verwendet nur 20B-Tokens und die Ergebnisse sind vergleichbar mit dem Mamba7B-Modell, das von Grund auf mit 1,2T-Tokens trainiert wurde, und dem NVIDIA Hybrid Mamba2-Modell, das mit 3,5T-Tokens trainiert wurde.
In technischen Details sind lineares RNN und lineare Aufmerksamkeit miteinander verbunden, sodass Forscher die Projektionsmatrix im Aufmerksamkeitsmechanismus direkt wiederverwenden und die Modellkonstruktion durch Parameterinitialisierung abschließen können. Darüber hinaus hat das Forschungsteam die Parameter der MLP-Schicht in Transformer eingefroren, den Aufmerksamkeitskopf nach und nach durch eine lineare RNN-Schicht (z. B. Mamba) ersetzt und die Gruppenabfrageaufmerksamkeit für gemeinsame Schlüssel und Werte über Köpfe hinweg verarbeitet.
Während des Destillationsprozesses wird eine Strategie des schrittweisen Ersetzens der Aufmerksamkeitsschichten angewendet. Die überwachte Feinabstimmung umfasst zwei Hauptmethoden: Die eine basiert auf der KL-Divergenz auf Wortebene und die andere auf der Wissensdestillation auf Sequenzebene. In der Abstimmungsphase der Benutzerpräferenzen verwendete das Team die Methode der direkten Präferenzoptimierung (DPO), um sicherzustellen, dass das Modell die Benutzererwartungen bei der Generierung von Inhalten besser erfüllen kann, indem es es mit der Ausgabe des Lehrermodells vergleicht.
Als nächstes begannen die Forscher, die spekulative Dekodierung von Transformer auf das Mamba-Modell anzuwenden. Spekulative Dekodierung kann einfach so verstanden werden, dass ein kleines Modell verwendet wird, um mehrere Ausgaben zu generieren, und dann ein großes Modell verwendet wird, um diese Ausgaben zu überprüfen. Kleine Modelle laufen schnell und können schnell mehrere Ausgabevektoren generieren, während große Modelle für die Bewertung der Genauigkeit dieser Ausgaben verantwortlich sind und dadurch die Gesamtinferenzgeschwindigkeit erhöhen.
Um diesen Prozess zu implementieren, haben die Forscher eine Reihe von Algorithmen entworfen, die ein kleines Modell verwenden, um jedes Mal K Entwurfsausgaben zu generieren, und das große Modell dann durch Verifizierung die endgültige Ausgabe und den Cache der Zwischenzustände zurückgibt. Mit dieser Methode wurden auf der GPU gute Ergebnisse erzielt. Mamba2.8B erreichte eine 1,5-fache Inferenzbeschleunigung und die Akzeptanzrate erreichte 60 %. Obwohl die Auswirkungen auf GPUs unterschiedlicher Architektur unterschiedlich sind, optimierte das Forschungsteam durch die Integration von Kerneln und die Anpassung der Implementierungsmethoden weiter und erzielte schließlich den idealen Beschleunigungseffekt.
In der experimentellen Phase führten die Forscher mit Zephyr-7B und Llama-3Instruct8B ein dreistufiges Destillationstraining durch. Am Ende dauerte es nur 3 bis 4 Tage, bis die Forschungsergebnisse auf einem 80G A100 mit 8 Karten erfolgreich reproduziert wurden. Diese Forschung zeigt nicht nur die Transformation zwischen Mamba und Llama, sondern liefert auch neue Ideen zur Verbesserung der Inferenzgeschwindigkeit und Leistung zukünftiger Modelle.
Papieradresse: https://arxiv.org/pdf/2408.15237
Diese Forschung liefert wertvolle Erfahrungen und technische Lösungen zur Verbesserung der Effizienz groß angelegter Sprachmodelle. Die Ergebnisse sollen auf weitere Bereiche angewendet werden und die Weiterentwicklung der Technologie der künstlichen Intelligenz fördern. Die Bereitstellung der Vortragsadresse erleichtert den Lesern ein tieferes Verständnis der Forschungsdetails.