Google DeepMind hat in Zusammenarbeit mit mehreren Universitäten eine neue Methode namens Generative Reward Model (GenRM) entwickelt, die darauf abzielt, das Problem der unzureichenden Genauigkeit und Zuverlässigkeit generativer KI bei Denkaufgaben zu lösen. Obwohl bestehende generative KI-Modelle in Bereichen wie der Verarbeitung natürlicher Sprache weit verbreitet sind, geben sie häufig sicher fehlerhafte Informationen aus, insbesondere in Bereichen, die eine extrem hohe Genauigkeit erfordern, was ihren Anwendungsbereich einschränkt. Die Innovation von GenRM besteht darin, den Verifizierungsprozess als Aufgabe zur Vorhersage des nächsten Wortes neu zu definieren, die Textgenerierungsfunktionen großer Sprachmodelle (LLMs) in den Verifizierungsprozess zu integrieren und das Kettenschlussfolgern zu unterstützen, wodurch eine umfassendere und systematischere Verifizierung erreicht wird.
Kürzlich hat sich das Forschungsteam von Google DeepMind mit einer Reihe von Universitäten zusammengetan, um eine neue Methode namens Generative Reward Model (GenRM) vorzuschlagen, die darauf abzielt, die Genauigkeit und Zuverlässigkeit generativer KI bei Denkaufgaben zu verbessern.
Generative KI wird in vielen Bereichen wie der Verarbeitung natürlicher Sprache häufig eingesetzt. Sie generiert hauptsächlich kohärenten Text, indem sie das nächste Wort einer Reihe von Wörtern vorhersagt. Allerdings geben diese Modelle manchmal sicher falsche Informationen aus, was insbesondere in Bereichen, in denen es auf Genauigkeit ankommt, wie Bildung, Finanzen und Gesundheitswesen, ein großes Problem darstellt.
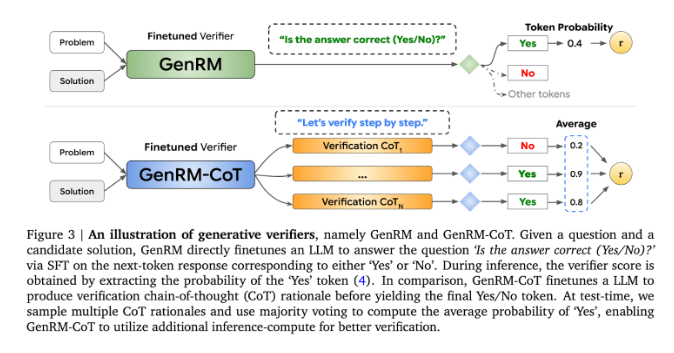
Derzeit haben Forscher verschiedene Lösungen für die Schwierigkeiten generativer KI-Modelle bei der Ausgabegenauigkeit ausprobiert. Unter ihnen werden diskriminierende Belohnungsmodelle (RMs) verwendet, um anhand der Punktzahlen zu bestimmen, ob potenzielle Antworten richtig sind. Diese Methode nutzt jedoch die generativen Fähigkeiten großer Sprachmodelle (LLMs) nicht vollständig aus. Eine weitere häufig verwendete Methode ist „LLM als Richter“, diese Methode ist jedoch bei der Lösung komplexer Argumentationsaufgaben oft nicht so effektiv wie ein professioneller Prüfer.
Die Innovation von GenRM besteht darin, den Verifizierungsprozess als Aufgabe zur Vorhersage des nächsten Wortes neu zu definieren. Dies bedeutet, dass GenRM im Gegensatz zu herkömmlichen diskriminierenden Belohnungsmodellen die Textgenerierungsfunktionen von LLMs in den Verifizierungsprozess einbezieht, sodass das Modell gleichzeitig potenzielle Lösungen generieren und bewerten kann. Darüber hinaus unterstützt GenRM auch Chained Reasoning (CoT), d. h. das Modell kann vor dem Erreichen der endgültigen Schlussfolgerung Zwischenschritte generieren und so den Verifizierungsprozess umfassender und systematischer gestalten.
Durch die Kombination von Generierung und Validierung verfolgt der GenRM-Ansatz eine einheitliche Trainingsstrategie, die es dem Modell ermöglicht, während des Trainings gleichzeitig die Generierungs- und Validierungsfähigkeiten zu verbessern. In realen Anwendungen generiert das Modell Zwischeninferenzschritte, die zur Überprüfung der endgültigen Antwort verwendet werden.
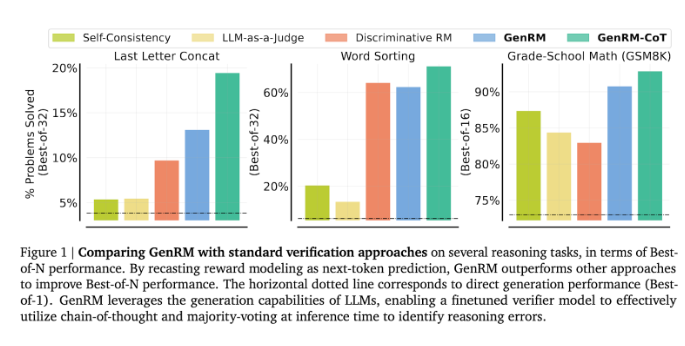
Die Forscher fanden heraus, dass das GenRM-Modell bei mehreren strengen Tests gut abschnitt, beispielsweise bei der deutlich verbesserten Genauigkeit bei Mathematik- und algorithmischen Problemlösungsaufgaben im Vorschulalter. Im Vergleich zum diskriminierenden Belohnungsmodell und der LLM-als-Richter-Methode stieg die Problemlösungserfolgsquote von GenRM um 16 % auf 64 %.
Bei der Überprüfung der Ausgabe des Gemini1.0Pro-Modells erhöhte GenRM beispielsweise die Erfolgsquote bei der Problemlösung von 73 % auf 92,8 %.
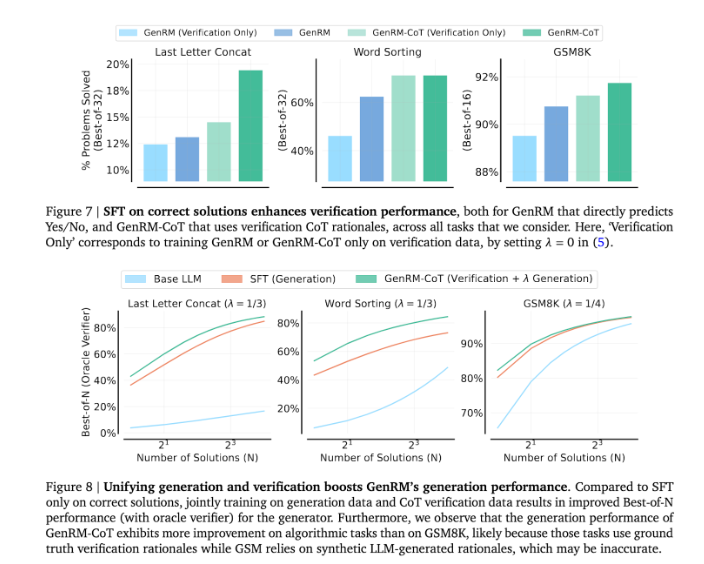
Die Einführung der GenRM-Methode stellt einen großen Fortschritt im Bereich der generativen KI dar und verbessert die Genauigkeit und Vertrauenswürdigkeit von KI-generierten Lösungen erheblich, indem die Lösungsgenerierung und -verifizierung in einem Prozess vereint wird.
Alles in allem liefert das Aufkommen von GenRM neue Ideen zur Verbesserung der Zuverlässigkeit generativer KI. Seine deutliche Verbesserung bei der Lösung komplexer Argumentationsprobleme weist auf die Möglichkeit hin, dass generative KI in weiteren Bereichen eingesetzt werden kann, was weiterer Forschung und Erforschung wert ist.