Datenbankabfrageoptimierer verlassen sich stark auf die Kardinalitätsschätzung (CE), um die Größe der Abfrageergebnisse vorherzusagen und so den besten Ausführungsplan auszuwählen. Ungenaue Kardinalitätsschätzungen können zu einer Verschlechterung der Abfrageleistung führen. Bestehende CE-Methoden weisen Einschränkungen auf, insbesondere bei der Bearbeitung komplexer Abfragen. Obwohl das lernende CE-Modell genauer ist, sind die Schulungskosten hoch und es fehlt eine systematische Benchmark-Bewertung.
In modernen relationalen Datenbanken spielt die Kardinalitätsschätzung (CE) eine entscheidende Rolle. Einfach ausgedrückt ist die Kardinalitätsschätzung eine Vorhersage darüber, wie viele Zwischenergebnisse eine Datenbankabfrage zurückgeben wird. Diese Vorhersage hat große Auswirkungen auf die Auswahl des Ausführungsplans des Abfrageoptimierers, z. B. auf die Entscheidung über die Verknüpfungsreihenfolge, die Verwendung von Indizes und die Auswahl der besten Verknüpfungsmethode. Wenn die Kardinalitätsschätzung ungenau ist, kann der Ausführungsplan stark beeinträchtigt werden, was zu extrem langsamen Abfragegeschwindigkeiten führt und die Gesamtleistung der Datenbank ernsthaft beeinträchtigt.
Allerdings weisen bestehende Methoden zur Kardinalitätsschätzung viele Einschränkungen auf. Die herkömmliche CE-Technologie basiert auf einigen vereinfachenden Annahmen und sagt die Kardinalität komplexer Abfragen häufig genau voraus, insbesondere wenn mehrere Tabellen und Bedingungen beteiligt sind. Obwohl das Erlernen von CE-Modellen eine bessere Genauigkeit liefern kann, ist ihre Anwendung durch lange Trainingszeiten, den Bedarf an großen Datensätzen und das Fehlen einer systematischen Benchmark-Bewertung begrenzt.
Um diese Lücke zu schließen, hat das Forschungsteam von Google CardBench eingeführt, ein neues Benchmarking-Framework. CardBench umfasst mehr als 20 reale Datenbanken und Tausende von Abfragen und übertrifft damit die bisherigen Benchmarks bei weitem. Dies ermöglicht es Forschern, verschiedene CE-Lernmodelle unter verschiedenen Bedingungen systematisch zu bewerten und zu vergleichen. Der Benchmark unterstützt drei Haupteinstellungen: instanzbasierte Modelle, Zero-Shot-Modelle und fein abgestimmte Modelle, die für unterschiedliche Trainingsanforderungen geeignet sind.
CardBench ist außerdem so konzipiert, dass es eine Reihe von Tools enthält, mit denen erforderliche Statistiken berechnet, echte SQL-Abfragen generiert und kommentierte Abfragediagramme für das Training von CE-Modellen erstellt werden können.
Der Benchmark stellt zwei Sätze von Trainingsdaten bereit: einen für eine einzelne Tabellenabfrage mit mehreren Filterprädikaten und einen für eine binäre Join-Abfrage mit zwei Tabellen. Der Benchmark umfasst 9125 Einzeltabellenabfragen und 8454 binäre Join-Abfragen für einen der kleineren Datensätze und gewährleistet so eine robuste und anspruchsvolle Umgebung für die Modellbewertung. Das Training von Datenlabels von Google BigQuery erforderte eine Abfrageausführungszeit von 7 CPU-Jahren, was den erheblichen Rechenaufwand für die Erstellung dieses Benchmarks unterstreicht. Durch die Bereitstellung dieser Datensätze und Tools senkt CardBench die Hürde für Forscher, neue CE-Modelle zu entwickeln und zu testen.
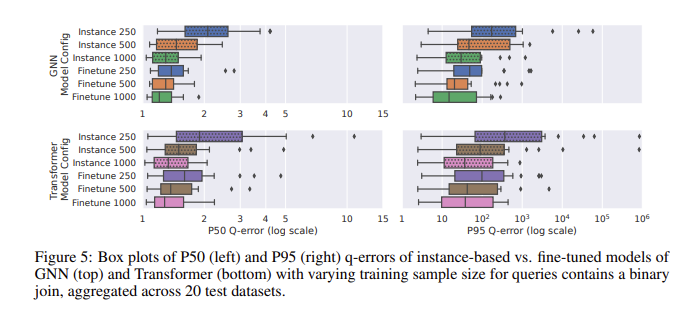
Bei der Leistungsbewertung mittels CardBench schnitt das verfeinerte Modell besonders gut ab. Während Zero-Shot-Modelle Schwierigkeiten haben, die Genauigkeit zu verbessern, wenn sie auf unsichtbare Datensätze angewendet werden, insbesondere bei komplexen Abfragen mit Verknüpfungen, können fein abgestimmte Modelle mit viel weniger Trainingsdaten eine vergleichbare Genauigkeit wie instanzbasierte Methoden erreichen. Beispielsweise erreichte ein fein abgestimmtes Graph Neural Network (GNN)-Modell einen mittleren Q-Fehler von 1,32 und einen 95. Perzentil-Q-Fehler von 120 bei binären Join-Abfragen, was deutlich besser ist als das Zero-Shot-Modell. Die Ergebnisse zeigen, dass selbst bei 500 Abfragen eine Feinabstimmung des vorab trainierten Modells dessen Leistung deutlich verbessern kann. Dadurch eignen sie sich für praktische Anwendungen, bei denen die Trainingsdaten möglicherweise begrenzt sind.
Die Einführung von CardBench bringt neue Hoffnung auf den Bereich der erlernten Kardinalitätsschätzung und ermöglicht es Forschern, Modelle effektiver zu bewerten und zu verbessern und so die weitere Entwicklung in diesem wichtigen Bereich voranzutreiben.
Papiereingang: https://arxiv.org/abs/2408.16170
Kurz gesagt: CardBench bietet ein umfassendes und leistungsstarkes Benchmarking-Framework, stellt wichtige Tools und Ressourcen für die Forschung und Entwicklung lernender Modelle zur Kardinalitätsschätzung bereit und fördert die Weiterentwicklung der Technologie zur Optimierung von Datenbankabfragen. Besonders hervorzuheben ist die hervorragende Leistung des fein abgestimmten Modells, das neue Möglichkeiten für praktische Anwendungsszenarien bietet.