Kürzlich zeigte eine im Cureus-Magazin veröffentlichte Studie, dass das GPT-4-Modell von OpenAI die nationale japanische Physiotherapieprüfung ohne zusätzliche Schulung erfolgreich bestanden hat. Die Forscher testeten GPT-4 anhand von 1.000 Fragen zu Gedächtnis, Verständnis, Anwendung, Analyse und Bewertung. Die Ergebnisse zeigten, dass es eine Genauigkeitsrate von 73,4 % aufwies und alle fünf Testteile bestand. Diese Forschung wirft Bedenken hinsichtlich des Potenzials von GPT-4 für medizinische Anwendungen auf, zeigt aber auch seine Grenzen bei der Behandlung spezifischer Arten von Problemen auf, wie etwa praktische Probleme und solche, die Bildtabellen enthalten.
Eine aktuelle, von Experten begutachtete Studie, die in der Zeitschrift Cureus veröffentlicht wurde, zeigt, dass das GPT-4-Sprachmodell von OpenAI die nationale japanische Physiotherapieprüfung ohne zusätzliche Schulung erfolgreich bestanden hat.
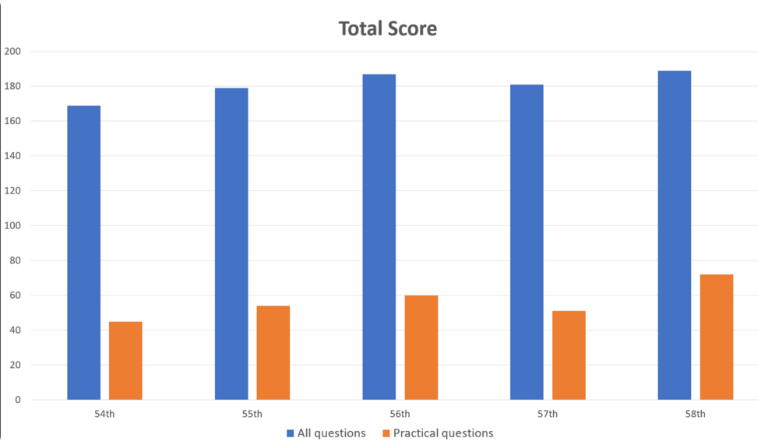
Die Forscher gaben 1.000 Fragen in GPT-4 ein, die Bereiche wie Gedächtnis, Verständnis, Anwendung, Analyse und Bewertung abdeckten. Die Ergebnisse zeigten, dass GPT-4 insgesamt 73,4 % der Fragen richtig beantwortete und alle fünf Testteile bestand. Die Forschung hat jedoch auch die Grenzen der KI in einigen Bereichen aufgezeigt.

GPT-4 schnitt bei allgemeinen Problemen mit einer Genauigkeit von 80,1 % gut ab, bei praktischen Problemen jedoch nur mit 46,6 %. Ebenso schneidet es bei reinen Textfragen deutlich besser ab (80,5 % richtig) als bei Fragen mit Bildern und Tabellen (35,4 % richtig). Dieser Befund steht im Einklang mit früheren Untersuchungen zu den Einschränkungen des visuellen Verständnisses von GPT-4.
Es ist erwähnenswert, dass der Schwierigkeitsgrad der Fragen und die Textlänge kaum Einfluss auf die Leistung von GPT-4 haben. Obwohl das Modell hauptsächlich mit englischen Daten trainiert wurde, schnitt es auch bei der Verarbeitung japanischer Eingaben gut ab.
Die Forscher stellten fest, dass diese Studie zwar das Potenzial von GPT-4 in der klinischen Rehabilitation und medizinischen Ausbildung zeigt, sie jedoch mit Vorsicht betrachtet werden sollte. Sie betonten, dass GPT-4 nicht alle Fragen richtig beantwortet und dass zukünftige Bewertungen neuer Versionen und der Fähigkeiten des Modells in schriftlichen Tests und Tests zum logischen Denken erforderlich sein werden.
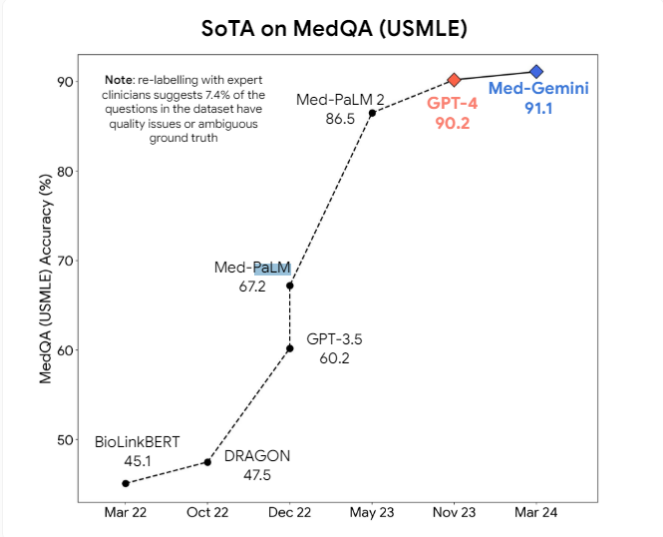
Darüber hinaus schlugen die Forscher vor, dass multimodale Modelle wie GPT-4v das visuelle Verständnis weiter verbessern könnten. Derzeit werden professionelle medizinische KI-Modelle wie Med-PaLM2 und Med-Gemini von Google sowie das auf Llama3 basierende medizinische Modell von Meta aktiv entwickelt, mit dem Ziel, Allzweckmodelle bei medizinischen Aufgaben zu übertreffen.
Allerdings gehen Experten davon aus, dass es noch lange dauern könnte, bis medizinische KI-Modelle in der Praxis weit verbreitet sind. Der Fehlerraum aktueller Modelle ist im medizinischen Bereich nach wie vor zu groß, und es sind erhebliche Fortschritte bei den Inferenzfähigkeiten erforderlich, um diese Modelle sicher in die tägliche medizinische Praxis zu integrieren.
Obwohl diese Studie das Potenzial von GPT-4 im medizinischen Bereich zeigt, erinnert sie uns auch daran, dass die KI-Technologie noch kontinuierlich verbessert werden muss, bevor sie wirklich auf komplexe medizinische Szenarien angewendet werden kann. Zukünftig werden multimodale Modelle und leistungsfähigere Argumentationsfähigkeiten entscheidende Verbesserungen sein, um die Sicherheit und Zuverlässigkeit von KI in der medizinischen Versorgung zu gewährleisten.