Der Bereich der künstlichen Intelligenz hat sich zum Ziel gesetzt, Maschinen das Verständnis der komplexen physikalischen Welt zu ermöglichen. Durchbrüche auf diesem Gebiet sind für viele Bereiche von entscheidender Bedeutung. Kürzlich haben Forschungsteams der Renmin University of China, der Beijing University of Posts and Telecommunications, des Shanghai AI Lab und anderer Institutionen die Ref-AVS-Technologie entwickelt und damit eine neue Lösung für dieses Problem bereitgestellt. Die Ref-AVS-Technologie integriert mehrere modale Informationen wie Videoobjektsegmentierung, Videoobjektreferenzsegmentierung und audiovisuelle Segmentierung durch eine clevere multimodale Fusionsmethode und ermöglicht es dem KI-System, Anweisungen in natürlicher Sprache genauer zu verstehen und komplexe Audio- Visuelle Aufgaben Die präzise Positionierung von Zielobjekten in der Szene durchbricht die bisherigen Einschränkungen der KI im multimodalen Verständnis.
Im Bereich der künstlichen Intelligenz war es schon immer eine große Herausforderung, Maschinen dazu zu bringen, die komplexe physikalische Welt wie Menschen zu verstehen. Kürzlich hat ein Forschungsteam bestehend aus der Renmin University of China, der Beijing University of Posts and Telecommunications, dem Shanghai AI Lab und anderen Institutionen eine bahnbrechende Technologie vorgeschlagen – Ref-AVS, die neue Hoffnung zur Lösung dieses Problems bringt.
Der Kern der Ref-AVS-Technologie liegt in ihrer einzigartigen multimodalen Fusionsmethode. Es integriert geschickt mehrere modale Informationen wie Videoobjektsegmentierung (VOS), Videoobjektreferenzsegmentierung (Ref-VOS) und audiovisuelle Segmentierung (AVS). Diese innovative Fusion ermöglicht es dem KI-System, nicht nur Objekte zu verarbeiten, die Geräusche erzeugen, sondern auch nicht klingende, aber ebenso wichtige Objekte in der Szene zu identifizieren. Dieser Durchbruch ermöglicht es der KI, von Benutzern in natürlicher Sprache beschriebene Anweisungen genauer zu verstehen und bestimmte Objekte in komplexen audiovisuellen Szenen genau zu lokalisieren.
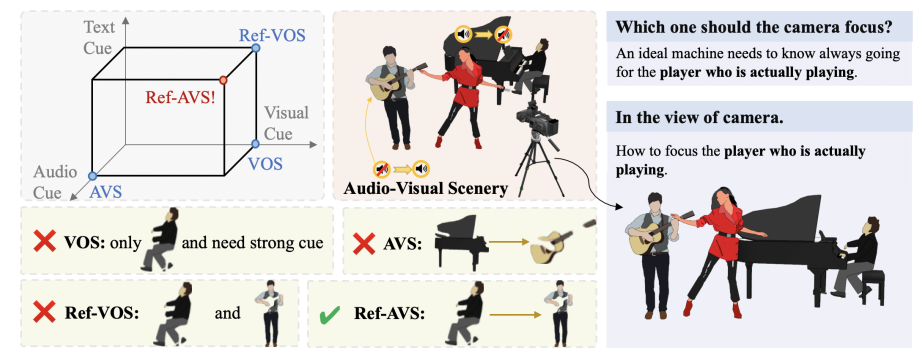
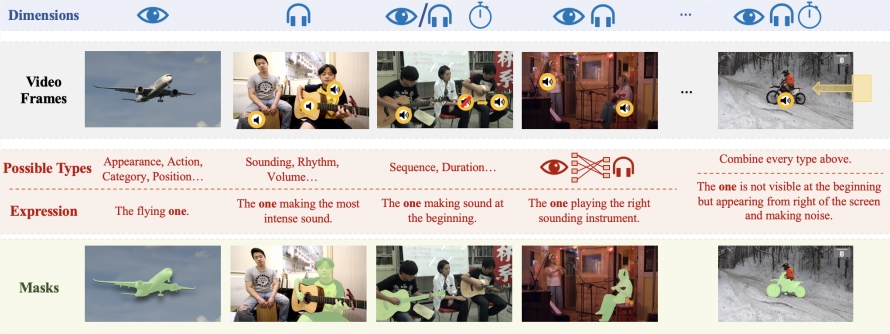
Um die Forschung und Verifizierung der Ref-AVS-Technologie zu unterstützen, erstellte das Forschungsteam einen umfangreichen Datensatz namens Ref-AVS Bench. Dieser Datensatz enthält 40.020 Videobilder, die 6.888 Objekte und 20.261 verweisende Ausdrücke abdecken. Jedes Videobild wird von entsprechenden Audio- und detaillierten Anmerkungen auf Pixelebene begleitet. Dieser reichhaltige und vielfältige Datensatz bietet eine solide Grundlage für die multimodale Forschung und eröffnet neue Möglichkeiten für zukünftige Forschung in verwandten Bereichen.
In einer Reihe strenger quantitativer und qualitativer Experimente zeigte die Ref-AVS-Technologie eine hervorragende Leistung. Insbesondere bei der gesehenen Teilmenge übertrifft Ref-AVS andere bestehende Methoden und stellt seine leistungsstarken Segmentierungsfähigkeiten voll unter Beweis. Bemerkenswerter ist, dass die Testergebnisse für die Teilmengen Unseen und Null die hervorragende Generalisierungsfähigkeit und Robustheit der Ref-AVS-Technologie auf Nullreferenzen weiter bestätigen, die für praktische Anwendungsszenarien von entscheidender Bedeutung sind.
Der Erfolg der Ref-AVS-Technologie hat nicht nur in der Wissenschaft große Aufmerksamkeit erregt, sondern auch neue Wege für zukünftige praktische Anwendungen eröffnet. Wir können absehen, dass diese Technologie in vielen Bereichen wie der Videoanalyse, der medizinischen Bildverarbeitung, dem autonomen Fahren und der Roboternavigation eine wichtige Rolle spielen wird. Im medizinischen Bereich kann Ref-AVS beispielsweise Ärzten helfen, komplexe medizinische Bilder genauer zu interpretieren. Im Bereich des autonomen Fahrens kann es die Wahrnehmung der Umgebung durch das Fahrzeug verbessern menschliche verbale Anweisungen ausführen.
Die Ergebnisse dieser Forschung wurden auf der ECCV2024 vorgestellt und relevante Papiere und Projektinformationen wurden ebenfalls veröffentlicht, was wertvolle Lern- und Erkundungsressourcen für Forscher und Entwickler auf der ganzen Welt bietet, die sich für dieses Gebiet interessieren. Diese offene und teilende Haltung spiegelt nicht nur den akademischen Geist des chinesischen wissenschaftlichen Forschungsteams wider, sondern wird auch die schnelle Entwicklung des gesamten KI-Bereichs fördern.
Das Aufkommen der Ref-AVS-Technologie markiert einen wichtigen Schritt im multimodalen Verständnis künstlicher Intelligenz. Es demonstriert nicht nur die innovativen Fähigkeiten des chinesischen wissenschaftlichen Forschungsteams auf dem Gebiet der KI, sondern zeichnet auch einen intelligenteren und natürlicheren Entwurf für die Zukunft der Mensch-Computer-Interaktion. Da diese Technologie weiterhin verbessert und angewendet wird, haben wir Grund zu der Annahme, dass zukünftige KI-Systeme in der Lage sein werden, die komplexe Welt der Menschen besser zu verstehen und sich an sie anzupassen und revolutionäre Veränderungen in allen Lebensbereichen herbeizuführen.
Papieradresse: https://arxiv.org/abs/2407.10957
Projekthomepage:
https://gewu-lab.github.io/Ref-AVS/
Kurz gesagt, das Aufkommen der Ref-AVS-Technologie hat neue Durchbrüche im Bereich des multimodalen Verständnisses künstlicher Intelligenz gebracht. Auf ihre leistungsstarke Leistung und ihre breiten Anwendungsaussichten kann man sich freuen. Diese Technologie wird die Entwicklung künstlicher Intelligenz hin zu intelligenteren und natürlicheren Interaktionen vorantreiben und der menschlichen Gesellschaft mehr Komfort bieten.