Kürzlich veröffentlichte MLCommons die Ergebnisse von MLPerf Inference v4.1. Mehrere Hersteller von KI-Inferenzchips nahmen teil, und die Konkurrenz war hart. Erstmals nehmen an diesem Wettbewerb Chips von AMD, Google, UntetherAI und anderen Herstellern sowie die neuesten Blackwell-Chips von Nvidia teil. Neben dem Leistungsvergleich ist auch die Energieeffizienz zu einer wichtigen Wettbewerbsdimension geworden. Verschiedene Hersteller haben in verschiedenen Benchmark-Tests ihre besonderen Fähigkeiten unter Beweis gestellt und ihre jeweiligen Vorteile unter Beweis gestellt und so neue Dynamik in den Markt für KI-Inferenzchips gebracht.
Im Bereich der Ausbildung künstlicher Intelligenz sind die Grafikkarten von Nvidia nahezu konkurrenzlos, doch wenn es um KI-Inferenz geht, scheinen die Konkurrenten gerade in puncto Energieeffizienz langsam aufzuholen. Trotz der starken Leistung von Nvidias neuesten Blackwell-Chips ist unklar, ob Nvidia seinen Vorsprung behaupten kann. Heute gab ML Commons die Ergebnisse des neuesten KI-Inferenzwettbewerbs bekannt – MLPerf Inference v4.1. Zum ersten Mal nehmen AMDs Instinct-Beschleuniger, Googles Trillium-Beschleuniger, Chips des kanadischen Startups UntetherAI und Nvidias Blackwell-Chips teil. Zwei weitere Unternehmen, Cerebras und FuriosaAI, haben neue Inferenzchips auf den Markt gebracht, MLPerf jedoch nicht zum Testen eingereicht.
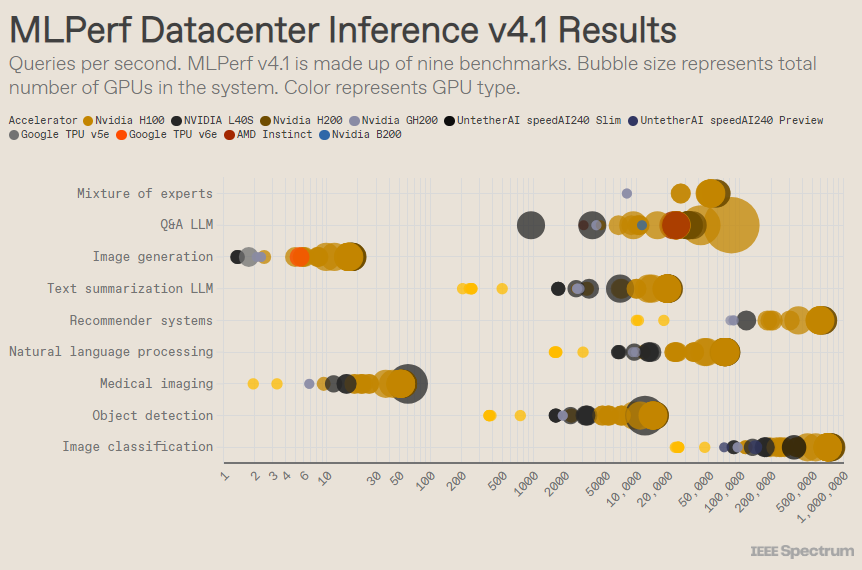
MLPerf ist wie ein olympischer Wettbewerb aufgebaut, mit mehreren Veranstaltungen und Unterveranstaltungen. Die Kategorie „Data Center Enclosure“ verzeichnete die meisten Einträge. Im Gegensatz zur offenen Kategorie müssen die Teilnehmer in der geschlossenen Kategorie direkt Rückschlüsse auf ein bestimmtes Modell ziehen, ohne die Software wesentlich zu ändern. In der Kategorie „Rechenzentrum“ wird in erster Linie die Fähigkeit getestet, Anfragen stapelweise zu verarbeiten, während sich die Kategorie „Edge“ auf die Reduzierung der Latenz konzentriert.
In jeder Kategorie gibt es 9 verschiedene Benchmarks, die eine Vielzahl von KI-Aufgaben abdecken, darunter beliebte Bildgenerierung (denken Sie an Midjourney) und die Beantwortung von Fragen mit großen Sprachmodellen (wie ChatGPT) sowie einige wichtige, aber weniger bekannte Aufgaben, wie z Bildklassifizierung, Objekterkennung und Empfehlungs-Engines.
Diese Runde fügt einen neuen Maßstab hinzu – das „Experten-Hybridmodell“. Hierbei handelt es sich um eine immer beliebter werdende Methode zur Bereitstellung von Sprachmodellen, bei der ein Sprachmodell in mehrere unabhängige kleine Modelle aufgeteilt wird, die jeweils auf eine bestimmte Aufgabe abgestimmt sind, z. B. tägliche Konversation, Lösung mathematischer Probleme oder Programmierunterstützung. „Durch die Zuweisung jeder Abfrage zu ihrem entsprechenden kleinen Modell wird die Ressourcennutzung reduziert, was die Kosten senkt und den Durchsatz erhöht“, sagte Miroslav Hodak, leitender technischer Mitarbeiter bei AMD.

Beim beliebten „Rechenzentrum geschlossen“-Benchmark gewinnen immer noch Einsendungen, die auf der Nvidia H200-GPU und dem GH200-Superchip basieren, die GPU und CPU in einem Paket vereinen. Ein genauerer Blick auf die Ergebnisse offenbart jedoch einige interessante Details. Einige Wettbewerber verwendeten mehrere Beschleuniger, während andere nur einen verwendeten. Die Ergebnisse sind noch verwirrender, wenn wir die Abfragen pro Sekunde anhand der Anzahl der Beschleuniger normalisieren und die Einreichungen mit der besten Leistung für jeden Beschleunigertyp beibehalten. Es ist zu beachten, dass dieser Ansatz die Rolle der CPU und der Verbindung ignoriert.
Auf Pro-Beschleuniger-Basis schnitt Nvidias Blackwell bei Frage-und-Antwort-Aufgaben mit großen Sprachmodellen hervorragend ab und lieferte eine 2,5-fache Beschleunigung gegenüber früheren Chip-Iterationen, dem einzigen Benchmark, dem er sich unterzog. Der speedAI240-Vorschauchip von Untether AI schnitt bei der einzigen Bilderkennungsaufgabe, der er unterzogen wurde, fast genauso gut ab wie der H200. Googles Trillium schneidet bei Bildgenerierungsaufgaben etwas schlechter ab als H100 und H200, während AMDs Instinct bei Frage- und Antwortaufgaben mit großen Sprachmodellen eine gleichwertige Leistung wie H100 erbringt.
Ein Teil des Erfolgs von Blackwell beruht auf seiner Fähigkeit, große Sprachmodelle mit 4-Bit-Gleitkommagenauigkeit auszuführen. Nvidia und Konkurrenten haben daran gearbeitet, die Anzahl der in Transformationsmodellen wie ChatGPT dargestellten Bits zu reduzieren, um Berechnungen zu beschleunigen. Nvidia hat 8-Bit-Mathematik im H100 eingeführt, und dieser Beitrag ist die erste Demonstration von 4-Bit-Mathematik im MLPerf-Benchmark.
Die größte Herausforderung bei der Arbeit mit Zahlen mit solch geringer Genauigkeit sei die Aufrechterhaltung der Genauigkeit, sagte Dave Salvator, Produktmarketingdirektor bei Nvidia. Um eine hohe Genauigkeit bei MLPerf-Einreichungen zu gewährleisten, hat das Nvidia-Team zahlreiche Innovationen in der Software vorgenommen.
Darüber hinaus verdoppelt sich die Speicherbandbreite von Blackwell nahezu auf 8 Terabyte pro Sekunde, verglichen mit 4,8 Terabyte beim H200.
Nvidias Blackwell-Einreichung verwendet einen einzelnen Chip, aber Salvator sagt, dass er für Vernetzung und Skalierung konzipiert ist und in Kombination mit Nvidias NVLink-Verbindung die beste Leistung erbringt. Blackwell-GPUs unterstützen bis zu 18 NVLink-Verbindungen mit 100 GB pro Sekunde und einer Gesamtbandbreite von 1,8 Terabyte pro Sekunde, fast doppelt so viel wie die Verbindungsbandbreite des H100.
Salvator glaubt, dass mit der weiteren Skalierung großer Sprachmodelle auch die Inferenz Multi-GPU-Plattformen erfordern wird, um den Bedarf zu decken, und Blackwell ist für diese Situation konzipiert. „Havel ist eine Plattform“, sagte Salvator.
Nvidia hat sein Blackwell-Chipsystem in die Unterkategorie „Vorschau“ aufgenommen, was bedeutet, dass es noch nicht verfügbar ist, aber voraussichtlich vor der nächsten MLPerf-Veröffentlichung verfügbar sein wird, die in etwa sechs Monaten liegt.
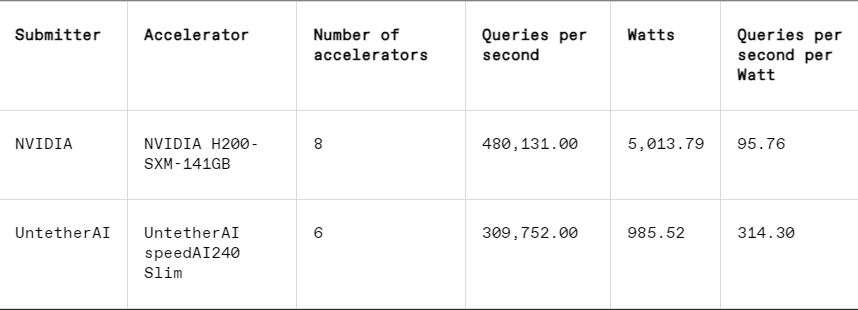
In jedem Benchmark enthält MLPerf auch einen Abschnitt zur Energiemessung, der den tatsächlichen Stromverbrauch jedes Systems während der Ausführung von Aufgaben systematisch testet. Der Hauptwettbewerb dieser Runde (Kategorie „Data Center Enclosed Energy“) hatte nur zwei Einsender, Nvidia und Untether AI. Während Nvidia an allen Benchmarks teilnahm, lieferte Untether nur Ergebnisse zur Bilderkennungsaufgabe.
Untether AI zeichnet sich in dieser Hinsicht aus und erreicht erfolgreich eine hervorragende Energieeffizienz. Ihr Chip nutzt einen Ansatz namens „In-Memory-Computing“. Der Chip von Untether AI besteht aus einer Bank von Speicherzellen, in deren Nähe sich ein kleiner Prozessor befindet. Jeder Prozessor arbeitet parallel und verarbeitet Daten gleichzeitig mit benachbarten Speichereinheiten, wodurch der Zeit- und Energieaufwand für die Übertragung von Modelldaten zwischen Speicher und Rechenkernen erheblich reduziert wird.
„Wir haben herausgefunden, dass bei der Ausführung von KI-Workloads 90 % des Energieverbrauchs darin bestehen, Daten vom DRAM in Cache-Verarbeitungseinheiten zu verschieben“, sagte Robert Beachler, Vice President of Product bei Untether AI. „Was Untether also tut, ist, die Berechnung näher an die Daten zu verlagern, anstatt die Daten zur Recheneinheit zu verschieben.“
Dieser Ansatz funktioniert besonders gut in einer anderen Unterkategorie von MLPerf: dem Kantenabschluss. Diese Kategorie konzentriert sich auf praktischere Anwendungsfälle wie Maschineninspektion in Fabriken, geführte Bildverarbeitungsroboter und autonome Fahrzeuge – Anwendungen, die strenge Anforderungen an Energieeffizienz und schnelle Verarbeitung stellen, erklärte Beachler.
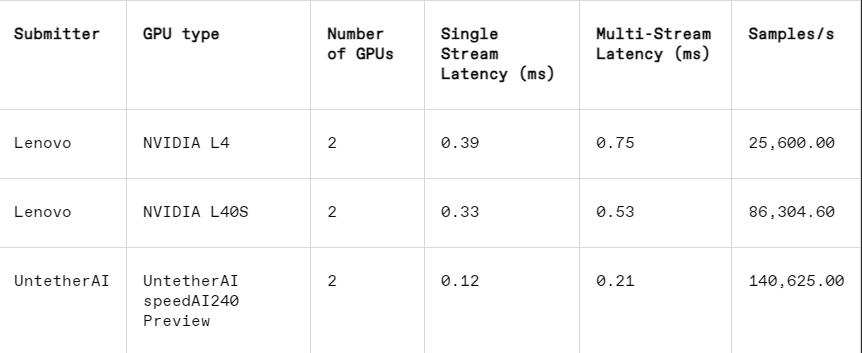
Bei der Bilderkennungsaufgabe ist die Latenzleistung des speedAI240-Vorschauchips von Untether AI 2,8-mal schneller als die des L40S von Nvidia, und der Durchsatz (Anzahl der Proben pro Sekunde) wird ebenfalls um das 1,6-fache erhöht. Das Startup legte in dieser Kategorie auch Ergebnisse zum Stromverbrauch vor, die Konkurrenten von Nvidia jedoch nicht, was einen direkten Vergleich erschwerte. Allerdings hat der speedAI240-Preview-Chip von Untether AI einen nominellen Stromverbrauch von 150 Watt, während der L40S von Nvidia 350 Watt beträgt, was einen 2,3-fachen Vorteil beim Stromverbrauch und eine bessere Latenzleistung zeigt.
Obwohl Cerebras und Furiosa nicht an MLPerf teilnahmen, veröffentlichten sie jeweils auch neue Chips. Cerebras stellte seinen Inferenzdienst auf der IEEE Hot Chips-Konferenz an der Stanford University vor. Das in Sunny Valley, Kalifornien, ansässige Unternehmen Cerebras stellt riesige Chips her, die so groß sind, wie es Siliziumwafer zulassen, wodurch Verbindungen zwischen Chips vermieden und die Speicherbandbreite des Geräts erheblich erhöht werden. Sie werden hauptsächlich zum Trainieren riesiger neuronaler Netzwerke verwendet. Jetzt haben sie ihren neuesten Computer, CS3, aktualisiert, um Inferenz zu unterstützen.
Obwohl Cerebras keinen MLPerf eingereicht hat, behauptet das Unternehmen, dass seine Plattform den H100 um das Siebenfache und den konkurrierenden Groq-Chip um das Zweifache in der Anzahl der pro Sekunde generierten LLM-Token übertrifft. „Heute befinden wir uns im Zeitalter der generativen KI“, sagte Andrew Feldman, CEO und Mitbegründer von Cerebras. „Das liegt alles daran, dass es einen Engpass bei der Speicherbandbreite gibt. Egal ob Nvidias H100 oder AMDs MI300 oder TPU, sie alle nutzen den gleichen externen Speicher, was zu den gleichen Einschränkungen führt. Wir durchbrechen diese Barriere, weil wir es auf Wafer-Level-Design machen.“ "
Auf der Hot-Chips-Konferenz stellte Furiosa aus Seoul auch seinen Chip RNGD (ausgesprochen „Rebell“) der zweiten Generation vor. Der neue Chip von Furiosa verfügt über die Tensor Contraction Processor (TCP)-Architektur. Bei KI-Workloads ist die grundlegende mathematische Funktion die Matrixmultiplikation, die oft als Grundelement in Hardware implementiert wird. Allerdings können Größe und Form der Matrix, also des breiteren Tensors, erheblich variieren. RNGD implementiert diese allgemeinere Tensormultiplikation als Grundelement. „Während der Inferenz variieren die Stapelgrößen stark, daher ist es wichtig, die inhärente Parallelität und Datenwiederverwendung einer bestimmten Tensorform voll auszunutzen“, sagte June Paik, Gründerin und CEO von Furiosa, bei Hot Chips.
Obwohl Furiosa nicht über MLPerf verfügt, verglichen sie den RNGD-Chip in internen Tests mit dem zusammenfassenden LLM-Benchmark von MLPerf. Die Ergebnisse waren mit dem L40S-Chip von Nvidia vergleichbar, verbrauchten jedoch nur 185 Watt im Vergleich zu den 320 Watt des L40S. Paik sagte, dass sich die Leistung mit weiteren Softwareoptimierungen verbessern werde.
IBM kündigte außerdem die Einführung seines neuen Spyre-Chips an, der für Unternehmen zur Generierung von KI-Workloads konzipiert ist und voraussichtlich im ersten Quartal 2025 verfügbar sein wird.
Es ist klar, dass der Markt für KI-Inferenzchips auf absehbare Zeit geschäftig sein wird.
Referenz: https://spectrum.ieee.org/new-inference-chips
Insgesamt zeigen die Ergebnisse von MLPerf v4.1, dass der Wettbewerb auf dem Markt für KI-Inferenzchips immer härter wird. Obwohl Nvidia immer noch die Führung behält, kann der Aufstieg von Herstellern wie AMD, Google und Untether AI nicht ignoriert werden. Energieeffizienz wird in Zukunft zu einem zentralen Wettbewerbsfaktor werden und auch neue Technologien wie In-Memory-Computing werden eine wichtige Rolle spielen. Die technologischen Innovationen verschiedener Hersteller werden die Verbesserung der KI-Schlussfolgerungsfähigkeiten weiterhin vorantreiben und starke Impulse für die Popularisierung und Entwicklung von KI-Anwendungen geben.