Die ModelScope-Community hat eine aktualisierte Version ihres inländischen Open-Source-Sora-Videogenerierungsmodells CogVideoX – CogVideoX-5B – als Open-Source-Version bereitgestellt. Dabei handelt es sich um ein Text-zu-Video-Generierungsmodell, das auf einem groß angelegten DiT-Modell basiert. Im Vergleich zum vorherigen CogVideoX-2B verfügt das neue Modell über deutlich verbesserte Videoqualität und visuelle Effekte. CogVideos , Videos mit höherer Qualität und mehr Bewegung.
Im Vergleich zum vorherigen CogVideoX-2B hat das neue Modell die Qualität und visuellen Effekte der Videoerzeugung deutlich verbessert.
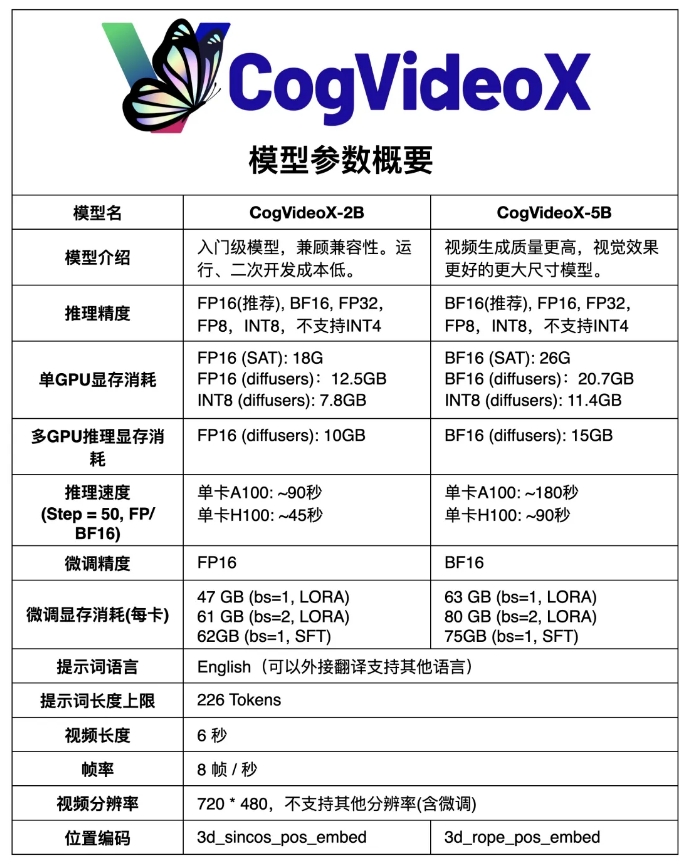
CogVideoX-5B basiert auf einem groß angelegten DiT-Modell (Diffusion Transformer), das speziell für Text-zu-Video-Generierungsaufgaben entwickelt wurde. Das Modell verwendet einen 3D-kausalen Variations-Autoencoder (3D-kausalen VAE) und eine Experten-Transformer-Technologie, kombiniert Text- und Videoeinbettungen, verwendet 3D-RoPE als Positionskodierung und nutzt einen 3D-Vollaufmerksamkeitsmechanismus für die räumlich-zeitliche Gelenkmodellierung.
Darüber hinaus nutzt das Modell progressive Trainingstechnologie und ist in der Lage, kohärente und langfristig hochwertige Videos mit signifikanten Bewegungsmerkmalen zu erzeugen.
Modelllink:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
Die Open Source von CogVideoX-5B hat neue technologische Durchbrüche und Entwicklungsmöglichkeiten auf dem Gebiet der inländischen KI-Videogenerierung gebracht und außerdem leistungsstarke Tools und Ressourcen für Forscher und Entwickler bereitgestellt. Es wird davon ausgegangen, dass in Zukunft weitere innovative Anwendungen auf Basis von CogVideoX-5B erscheinen werden, die den kontinuierlichen Fortschritt der KI-Videogenerierungstechnologie fördern. Der einfache Zugang zum Modell senkt auch die Hemmschwelle für Forschung und Anwendung und fördert so eine breitere Verbreitung und Anwendung der Technologie.