Die Text-to-SQL-Technologie zielt darauf ab, Datenbankabfragen zu vereinfachen, sodass normale Benutzer problemlos Daten abrufen können, ohne die SQL-Sprache zu lernen. Angesichts immer komplexerer Datenbankstrukturen ist die genaue Umwandlung natürlicher Sprache in SQL-Befehle jedoch immer noch eine Herausforderung. Forschungsteams der South China University of Technology und der Tsinghua University haben eine innovative Lösung vorgeschlagen – MAG-SQL, die die Genauigkeit und Effizienz der Text-zu-SQL-Konvertierung durch die Zusammenarbeit mehrerer Agenten erheblich verbessert.
Im Bereich der natürlichen Sprache (NLP) entwickelt sich die Text-to-SQL-Technologie (Text-to-SQL) rasant. Diese Technologie ermöglicht es normalen Benutzern, Datenbanken problemlos in japanischer Sprache abzufragen, ohne professionelle Programmiersprachen beherrschen zu müssen wie SQL. Da die Datenbankstruktur jedoch immer komplexer wird, ist die genaue Umwandlung natürlicher Sprache in SQL-Befehle zu einer großen Herausforderung geworden.
Forschungsteams der South China University of Technology und der Tsinghua University haben kürzlich eine neue Lösung vorgeschlagen – MAG-SQL (Multiple Intelligence Generating Model), die darauf abzielt, die Wirkung der Textkonvertierung in SQL zu verbessern. Diese Methode nutzt die Zusammenarbeit mehrerer Agenten und zielt darauf ab, die Genauigkeit der SQL-Generierung zu verbessern.
Die Funktionsweise von MAG-SQL ist ziemlich clever. Zu den Kernkomponenten gehören der „Soft Mode Linker“, der „Target-Conditional Resolver“, der „Sub-SQL Generator“ und der „Sub-SQL Modifier“. Erstens filtert der Soft-Mode-Linker die Datenbankspalten heraus, die für die Abfrage am relevantesten sind, wodurch unnötige Informationsinterferenzen reduziert und die Genauigkeit der Generierung von SQL-Befehlen verbessert werden. Als nächstes unterteilt der zielbedingte Zerleger die komplexe Abfrage zur einfacheren Verarbeitung in kleinere Unterabfragen.
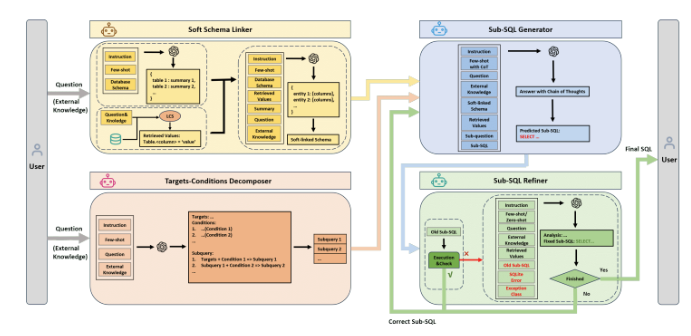
Der Sub-SQL-Generator generiert dann auf Basis der vorherigen Ergebnisse Sub-SQL-Abfragen und stellt so sicher, dass die SQL-Befehle schrittweise verfeinert werden können. Schließlich ist der Sub-SQL-Korrektor für die Korrektur generierter SQL-Fehler verantwortlich, wodurch die Gesamtgenauigkeit weiter verbessert wird. Diese mehrstufige Verarbeitungsmethode sorgt dafür, dass MAG-SQL in komplexen Datenbanken eine gute Leistung erbringt.
In aktuellen Tests schnitt MAG-SQL beim BIRD-Datensatz sehr gut ab. Bei Verwendung des GPT-4-Modells erreichte das System eine Ausführungsgenauigkeit von 61,08 %, was im Vergleich zu den 46,35 % des herkömmlichen GPT-4 deutlich verbessert wurde. Selbst wenn GPT-3.5 verwendet wird, erreicht die Genauigkeit von MAG-SQL 57,62 % und übertrifft damit die vorherige MAC-SQL-Methode. Darüber hinaus schneidet MAG-SQL bei einem anderen komplexen Datensatz, Spider, genauso gut ab und zeigt seine gute Vielseitigkeit.
Die Einführung von MAG-SQL verbessert nicht nur die Genauigkeit der Textkonvertierung in SQL, sondern liefert auch neue Ideen zur Lösung komplexer Abfragen. Dieses Multiagenten-Framework hat durch wiederholte und iterative Verfeinerung die Leistungsfähigkeit großer Sprachmodelle in praktischen Anwendungen erheblich verbessert, insbesondere beim Umgang mit komplexen Datenbanken und schwierigen Abfragen.
Papiereingang: https://arxiv.org/pdf/2408.07930
Highlight:
? ** Verbesserte Genauigkeit **: MAG-SQL erreichte eine Ausführungsgenauigkeit von 61,08 % für den BIRD-Datensatz und übertraf damit die 46,35 % des herkömmlichen GPT-4 bei weitem.
**Zusammenarbeit mit mehreren Agenten**: Bei dieser Methode werden mehrere Agenten zur Arbeitsteilung und Zusammenarbeit eingesetzt, wodurch der SQL-Generierungsprozess effizienter und genauer wird.
**Breite Anwendungsaussichten**: MAG-SQL schneidet auch bei anderen Datensätzen (wie Spider) gut ab, was seine gute Benutzerfreundlichkeit und Anwendbarkeit unter Beweis stellt.
Das Multiagenten-Framework von MAG-SQL hat der Text-to-SQL-Technologie erhebliche Leistungsverbesserungen gebracht. Seine hervorragende Leistung bei komplexen Datensätzen zeigt das enorme Potenzial dieser Technologie in praktischen Anwendungen und wird den Weg für zukünftige Innovationen bei Datenbankabfragemethoden ebnen . Bietet neue Richtungen.