In den letzten Jahren hat die Leistung von Großsprachmodellen (LLM) viel Aufmerksamkeit erregt. In diesem Artikel wird eine aufregende Forschung eingeführt. Diese Forschung stellt das Konzept traditioneller "größerer Modelle und besserer" heraus, bietet neue Ideen und Richtungen für die zukünftige Entwicklung von LLM und bietet Forschern und Entwicklern mehr Möglichkeiten mit begrenzten Ressourcen. Es zeigt das enorme Potenzial von Suchstrategien bei der Verbesserung der Fähigkeiten zur Modellsbekämpfung und Auslöser im Abschnitt über die Beziehung zwischen Rechenressourcen und Modellparametern.
In jüngster Zeit war eine neue Studie aufregend und beweist, dass große Sprachmodelle (LLM) die Leistung durch Suchfunktion erheblich verbessern können. Insbesondere das Lama3.1-Modell mit einem Parametervolumen von nur 800 Millionen durchlief 100 Suchvorgänge und war nicht mit dem GPT-4O im Python-Code vergleichbar.
Diese Idee scheint die Menschen an den Pionier des Lernens zu erinnern, Rich Suttons klassischem Blog -Beitrag "The Bitter Lessing" im Jahr 2019. Er erwähnte, dass wir mit der Verbesserung der Rechenleistung die Leistung allgemeiner Methoden erkennen müssen. Insbesondere scheinen die beiden Methoden der "Suche" und "Lernen" eine ausgezeichnete Wahl zu sein, die sich weiter erweitern kann.
Obwohl Sutton die Bedeutung des Lernens betont, dh größere Modelle können normalerweise mehr Wissen lernen, aber wir ignorieren häufig das Potenzial der Suche im Argumentationsprozess. In jüngster Zeit stellten Forscher aus Stanford, Oxford und Deepmind fest, dass die Erhöhung der Anzahl der wiederholten Stichprobenzeiten während der Argumentationsphase die Leistung von Modellen in den Bereichen Mathematik, Argumentation und Codegenerierung erheblich verbessern kann.
Nachdem die beiden Ingenieure von diesen Studien inspiriert wurden, beschlossen sie, Experimente durchzuführen. Sie fanden heraus, dass die Verwendung von 100 kleinen Lama-Modellen für die Suche GPT-4O in Python-Programmieraufgaben übertreffen und sogar binden kann. Sie verwenden lebhafte Metaphern, um zu beschreiben: "In der Vergangenheit könnte ein malaysischer Malaysia eine gewisse Fähigkeit erreichen. Jetzt können nur 100 Entenküken das Gleiche vervollständigen."
Um eine höhere Leistung zu erzielen, verwendeten sie die VLLM-Bibliothek, um Batch-Argumentation durchzuführen und mit 10 A100-40 GB GPUs zu laufen. Der Autor hat den Benchmark -Test von Humaneval ausgewählt, da er den Code ausführen kann, der durch Ausführen der Testbewertung generiert wird, was objektiver und genauer ist.
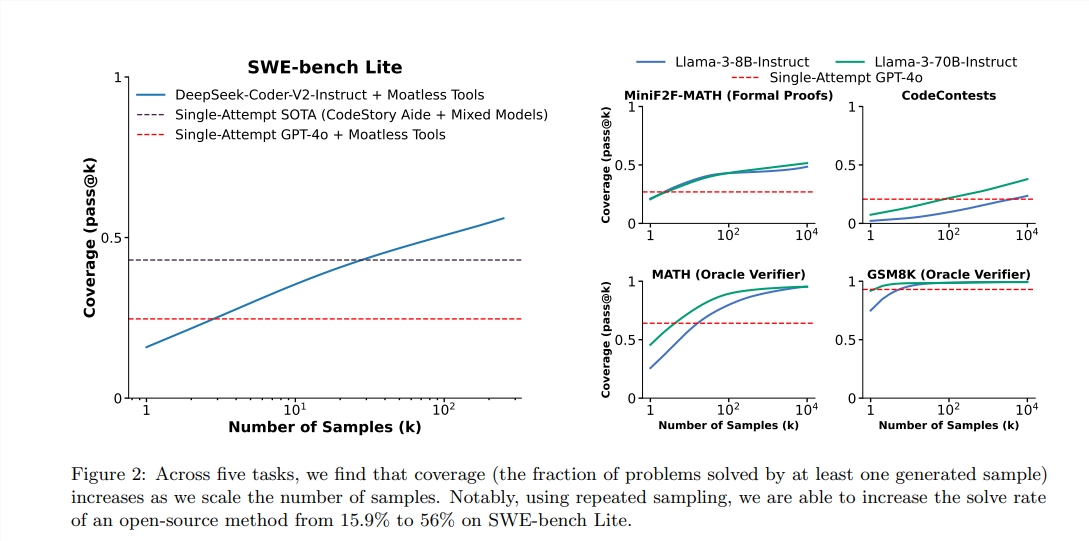
Laut dem Bericht beträgt der Pass@1-Punktzahl von GPT-4O 90,2%im Null-Stichproben-Argument. Durch die oben genannten Methoden hat sich auch der Pass@k -Punktzahl von Lama3.18b erheblich verbessert. Wenn die Anzahl der wiederholten Stichproben 100 beträgt, erreichte die Punktzahl von Lama 90,5%.
Erwähnenswert ist erwähnenswert, dass dieses Experiment zwar keine strikte Reproduktion der ursprünglichen Forschung ist, es jedoch betont, dass das kleinere Modell, wenn die Suchmethode die Argumentationsphase verbessert, auch die Möglichkeit großer Modelle innerhalb des vorhersehbaren Bereichs übertreffen kann.
Die Suche ist stark, da sie sich mit der Zunahme der Berechnung und der Übertragung von Ressourcen vom Speicher auf die Berechnung "transparent" erweitern kann, wodurch das Gleichgewicht der Ressourcen erreicht wird. In jüngster Zeit hat DeepMind wichtige Fortschritte im Bereich der Mathematik gemacht und die Kraft der Suche nachgewiesen.
Der Erfolg der Suche muss jedoch zunächst eine hohe Bewertung der Ergebnisse durchführen. Das DeepMind -Modell hat eine wirksame Überwachung erreicht, indem mathematische Probleme in der natürlichen Sprache in einen formalen Ausdruck umgewandelt wurden. In anderen Bereichen sind offene NLP -Aufgaben wie "zusammenfassende E -Mail" viel schwieriger, eine effektive Suche durchzuführen.
Diese Studie zeigt, dass die Leistungsverbesserung der Generierung von Modellen in bestimmten Bereichen mit ihren Bewertungs- und Suchfunktionen zusammenhängt. Zukünftige Forschung kann untersuchen, wie diese Fähigkeiten durch eine wiederholte digitale Umgebung verbessern können.
Abschlussarbeit: https: //arxiv.org/pdf/2407.21787
Insgesamt bietet diese Forschung eine neue Perspektive für die Leistungsverbesserung großer Sprachmodelle. In Zukunft ist die effektive Kombination von Lern- und Suchstrategien eine wichtige Richtung für die LLM -Entwicklung. Die verknüpfte Verbindung dieser Studie wurde ebenfalls bereitgestellt, und interessierte Leser können sie weiter verstehen.