Der Aufstieg der Transformer-Architektur hat den Bereich der Verarbeitung natürlicher Sprache revolutioniert, ihr hoher Rechenaufwand ist jedoch zu einem Engpass bei der Verarbeitung langer Texte geworden. Als Reaktion auf dieses Problem stellt dieser Artikel eine neue Methode namens Tree Attention vor, die die Rechenkomplexität der Selbstaufmerksamkeit des Transformer-Modells mit langem Kontext durch Baumreduzierung effektiv reduziert und die Leistung moderner GPU-Cluster voll ausnutzt Verbessert die Recheneffizienz erheblich.
In dieser Zeit der Informationsexplosion ist künstliche Intelligenz wie helle Sterne, die den Nachthimmel der menschlichen Weisheit erhellen. Unter diesen Stars ist die Transformer-Architektur zweifellos die schillerndste. Mit dem Selbstaufmerksamkeitsmechanismus als Kern leitet sie eine neue Ära der Verarbeitung natürlicher Sprache ein. Allerdings haben selbst die hellsten Sterne Ecken, die schwer zu erreichen sind. Bei Transformer-Modellen mit langem Kontext wird der hohe Ressourcenverbrauch der Selbstaufmerksamkeitsberechnung zum Problem. Stellen Sie sich vor, Sie versuchen, die KI dazu zu bringen, einen Artikel zu verstehen, der Zehntausende Wörter lang ist. Jedes Wort muss mit jedem anderen Wort im Artikel verglichen werden.
Um dieses Problem zu lösen, schlug eine Gruppe von Wissenschaftlern von Zyphra und EleutherAI eine neue Methode namens Tree Attention vor.
Die rechnerische Komplexität der Selbstaufmerksamkeit als Kern des Transformer-Modells nimmt quadratisch mit zunehmender Sequenzlänge zu. Dies wird zu einem unüberwindbaren Hindernis beim Umgang mit langen Texten, insbesondere bei großen Sprachmodellen (LLMs).
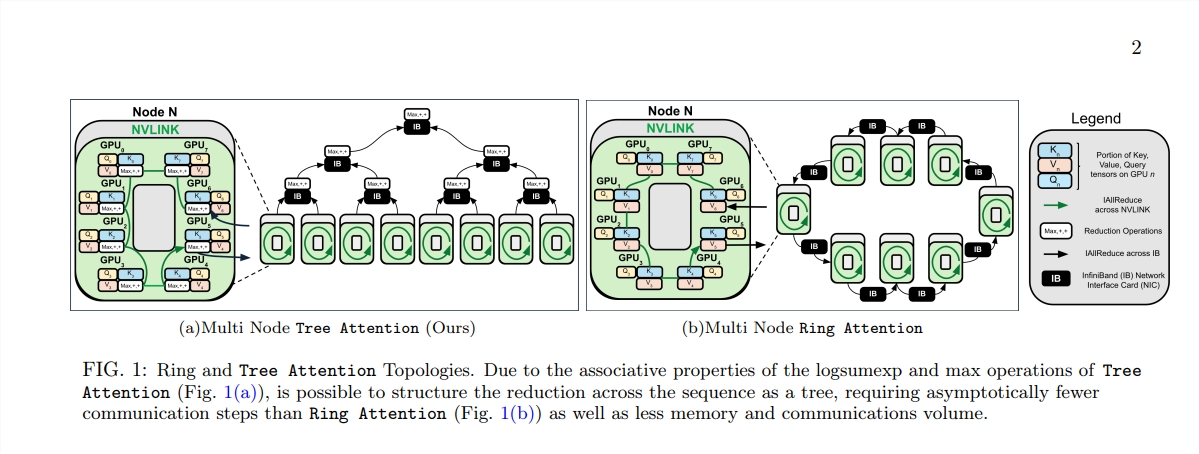
Die Geburt von Tree Attention ist wie das Pflanzen von Bäumen, die in diesem Computerwald effiziente Berechnungen durchführen können. Es zerlegt die Berechnung der Selbstaufmerksamkeit durch Baumreduktion in mehrere parallele Aufgaben. Jede Aufgabe ist wie ein Blatt am Baum, die zusammen einen vollständigen Baum bilden.
Was noch erstaunlicher ist, ist, dass die Befürworter von Tree Attention auch die Energiefunktion der Selbstaufmerksamkeit abgeleitet haben, die nicht nur eine bayesianische Erklärung für Selbstaufmerksamkeit liefert, sondern diese auch eng mit Energiemodellen wie dem Hopfield-Netzwerk-Standup verbindet.
Tree Attention berücksichtigt insbesondere auch die Netzwerktopologie moderner GPU-Cluster und reduziert den knotenübergreifenden Kommunikationsbedarf durch die intelligente Nutzung von Verbindungen mit hoher Bandbreite innerhalb des Clusters, wodurch die Recheneffizienz verbessert wird.
Durch eine Reihe von Experimenten überprüften die Wissenschaftler die Leistung von Tree Attention bei unterschiedlichen Sequenzlängen und Anzahlen von GPUs. Die Ergebnisse zeigen, dass Tree Attention bei der Dekodierung auf mehreren GPUs bis zu achtmal schneller ist als bestehende Ring Attention-Methoden und gleichzeitig das Kommunikationsvolumen und die Spitzenspeichernutzung deutlich reduziert.
Der Vorschlag von Tree Attention bietet nicht nur eine effiziente Lösung für die Berechnung von Aufmerksamkeitsmodellen mit langem Kontext, sondern bietet uns auch eine neue Perspektive, um den internen Mechanismus des Transformer-Modells zu verstehen. Da die KI-Technologie weiter voranschreitet, haben wir Grund zu der Annahme, dass Tree Attention eine wichtige Rolle in der zukünftigen KI-Forschung und -Anwendung spielen wird.
Papieradresse: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
Das Aufkommen von Tree Attention bietet eine effiziente und innovative Lösung zur Lösung des Rechenengpasses bei der Langtextverarbeitung. Es ist von weitreichender Bedeutung für das Verständnis und die zukünftige Entwicklung des Transformer-Modells. Mit dieser Methode werden nicht nur erhebliche Leistungsverbesserungen erzielt, sondern, was noch wichtiger ist, sie liefert neue Ideen und Richtungen für die nachfolgende Forschung, die einer eingehenden Untersuchung und Diskussion wert sind.