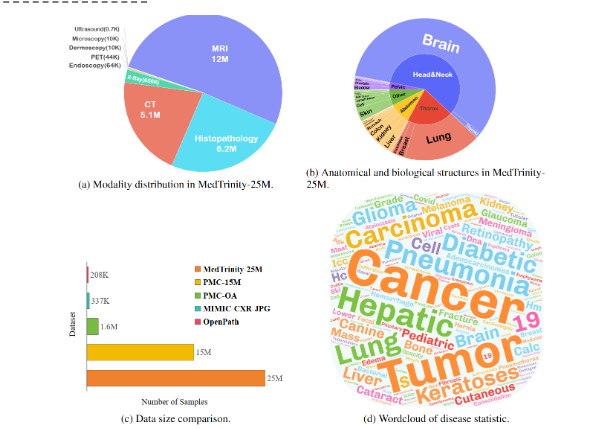
Das UCSC-VLAA-Team veröffentlichte den riesigen multimodalen medizinischen Datensatz MedTrinity-25M, der 25 Millionen medizinische Bilder und detaillierte Anmerkungen enthält, was einen großen Sprung bei den Datenressourcen im medizinischen Bereich darstellt. Die multigranulare Annotation dieses Datensatzes ermöglicht es Forschern, medizinische Daten tiefer zu verstehen und anzuwenden und bietet eine solide Grundlage für das Training fortschrittlicher medizinischer multimodaler großer Modelle. Der Konstruktionsprozess von MedTrinity-25M umfasst eine Vielzahl von Technologien, darunter hochentwickelte Datenverarbeitung, Metadatenintegration, MLLM-gestützte Beschreibungsgenerierung (Large-Scale Language Model) usw., was die Benutzerfreundlichkeit und den Forschungswert der Daten erheblich verbessert.
Der groß angelegte multimodale Datensatz „MedTrinity-25M“ des UCSC-VLAA-Teams wird offiziell veröffentlicht. Dieser Datensatz enthält 25 Millionen medizinische Bilder und detaillierte Anmerkungen. Es kann als eine wichtige Innovation im medizinischen Bereich beschrieben werden. Es verfügt über multigranulare Annotationen, die Forschern helfen können, medizinische Daten besser zu verstehen und anzuwenden und zum Trainieren medizinischer multimodaler großer Modelle verwendet werden können.
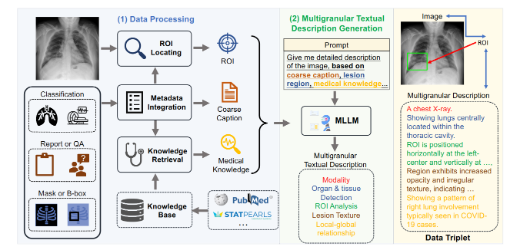
Der Konstruktionsprozess von MedTrinity-25M ist recht kompliziert. Nach sorgfältiger Datenverarbeitung extrahierte das Team wichtige Informationen aus verschiedenen Datentypen, integrierte Metadaten, generierte grobe Titel, lokalisierte Interessengebiete und sammelte relevante medizinische Informationen. Interessanter ist, dass sie diese Informationen nutzten, um detaillierte Beschreibungen mithilfe groß angelegter Sprachmodelle (MLLM) zu erstellen. Dieser Ansatz verbessert nicht nur die Datenverfügbarkeit, sondern eröffnet auch neue Wege für die medizinische Forschung.
Was den Veröffentlichungsprozess betrifft, ist es erwähnenswert, dass der Demo-Datensatz von MedTrinity-25M bereits im Juni 2024 online war, während der vollständige Datensatz offiziell am 21. Juli und zuletzt am 7. August veröffentlicht wurde verwandte Papiere.
Zusätzlich zum Datensatz selbst stellt das Team auch eine Reihe vorab trainierter Modelle bereit, wie z. B. LLaVA-Med++, die bei mehreren medizinischen Aufgaben gute Leistungen erbringen. Forscher können diese Tools nutzen, um ihre Projekte besser abzuschließen und so die Effizienz der medizinischen Forschung erheblich zu verbessern.
MedTrinity-25M stellt eine wertvolle Ressource für die medizinische Gemeinschaft dar. Ich hoffe, dass jeder diesen Datensatz umfassend nutzen kann, um die Entwicklung der medizinischen Forschung voranzutreiben.
Projekteingang: https://top.aibase.com/tool/medtrinity-25m
Die Veröffentlichung des MedTrinity-25M-Datensatzes und seiner unterstützenden Modelle gibt der medizinischen Künstliche-Intelligenz-Forschung einen starken Schub. Wir gehen davon aus, dass dieser Datensatz Durchbrüche in der medizinischen Bildanalyse, Krankheitsdiagnose und anderen Bereichen vorantreiben und letztendlich mehr Patienten zugute kommen wird. Forscher sind herzlich eingeladen, das Projektportal zu besuchen, um mehr über diese wertvolle Ressource zu erfahren und sie zu nutzen.