Andrej Karpathy, eine Autorität auf dem Gebiet der KI, stellte kürzlich das auf menschlichem Feedback basierende Reinforcement Learning (RLHF) in Frage, da es der Ansicht war, dass dies nicht der einzige Weg sei, echte KI auf menschlicher Ebene zu erreichen, was in der Branche große Besorgnis und hitzige Diskussionen ausgelöst hat . Er glaubt, dass RLHF eher eine Notlösung als die ultimative Lösung ist, und nahm AlphaGo als Beispiel, um die Unterschiede bei der Problemlösung zwischen echtem Reinforcement Learning und RLHF zu vergleichen. Karpathys Ansichten bieten zweifellos eine neue Perspektive auf aktuelle KI-Forschungsrichtungen und bringen auch neue Herausforderungen für die zukünftige KI-Entwicklung mit sich.
Kürzlich vertrat Andrej Karpathy, ein bekannter Forscher in der KI-Branche, einen kontroversen Standpunkt. Er glaubt, dass die derzeit weithin gelobte Technologie des Verstärkungslernens auf Basis menschlicher Rückmeldungen (RLHF) möglicherweise nicht der einzige Weg ist, dies zu erreichen echte Problemlösungsfähigkeiten auf menschlicher Ebene. Diese Aussage hat zweifellos eine schwere Bombe auf das aktuelle Feld der KI-Forschung geworfen.
RLHF galt einst als Schlüsselfaktor für den Erfolg groß angelegter Sprachmodelle (LLM) wie ChatGPT und wurde als Geheimwaffe gefeiert, die der KI Verständnis, Gehorsam und natürliche Interaktionsfähigkeiten verleiht. Im traditionellen KI-Trainingsprozess wird RLHF normalerweise als letztes Glied nach dem Vortraining und der überwachten Feinabstimmung (SFT) verwendet. Karpathy verglich RLHF jedoch mit einem Engpass und einer Notlösung und glaubte, dass es bei weitem nicht die ultimative Lösung für die KI-Entwicklung sei.
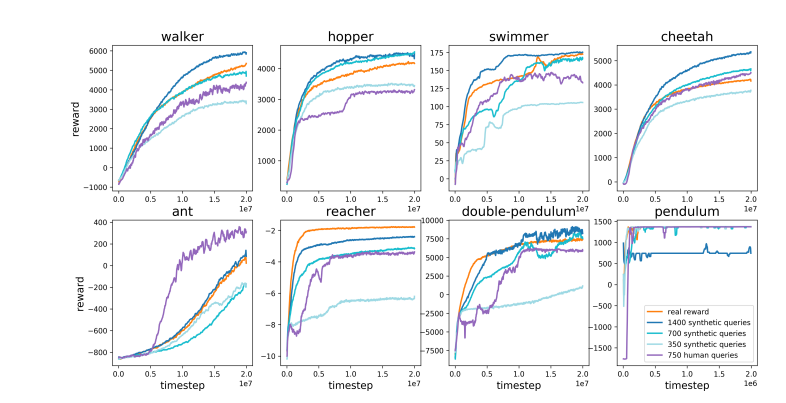
Karpathy verglich RLHF geschickt mit AlphaGo von DeepMind. AlphaGo nutzte, wie er es nennt, echte RL-Technologie (Reinforcement Learning), und indem es ständig gegen sich selbst spielte und seine Gewinnquote maximierte, übertraf es schließlich die besten menschlichen Schachspieler ohne menschliches Eingreifen. Dieser Ansatz erreicht übermenschliche Leistungsniveaus, indem neuronale Netze so optimiert werden, dass sie direkt aus Spielergebnissen lernen.
Im Gegensatz dazu glaubt Karpathy, dass es bei RLHF mehr darum geht, menschliche Vorlieben zu imitieren, als tatsächlich Probleme zu lösen. Er stellte sich vor, dass menschliche Bewerter eine große Anzahl von Spielzuständen vergleichen und Präferenzen auswählen müssten, wenn AlphaGo die RLHF-Methode anwendet. Dieser Prozess könnte bis zu 100.000 Vergleiche erfordern, um ein Belohnungsmodell zu trainieren, das die Überprüfung der menschlichen Atmosphäre nachahmt. Allerdings können solche atmosphärenbasierten Urteile in einem anspruchsvollen Spiel wie Go zu irreführenden Ergebnissen führen.
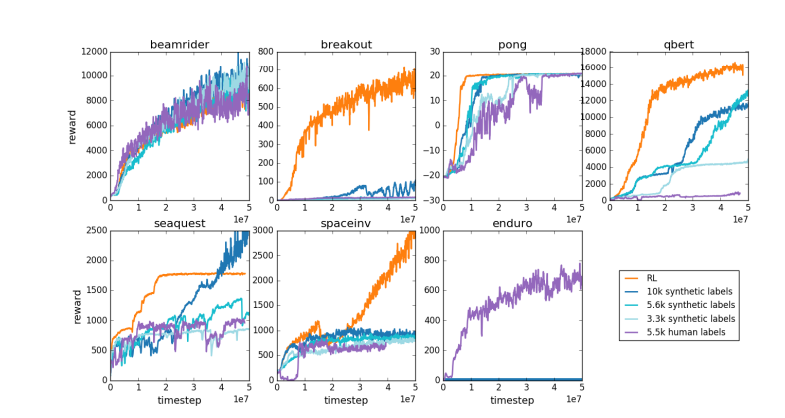
Aus dem gleichen Grund funktioniert das aktuelle LLM-Belohnungsmodell ähnlich – es tendiert dazu, Antworten hoch einzustufen, die menschliche Bewerter statistisch gesehen zu bevorzugen scheinen. Hierbei handelt es sich eher um einen Agenten, der auf oberflächliche menschliche Vorlieben eingeht, als auf die Widerspiegelung echter Problemlösungsfähigkeiten. Noch besorgniserregender ist, dass Modelle möglicherweise schnell lernen, diese Belohnungsfunktion zu nutzen, anstatt ihre Fähigkeiten tatsächlich zu verbessern.
Karpathy weist darauf hin, dass verstärkendes Lernen zwar in geschlossenen Umgebungen wie Go gut funktioniert, echtes verstärkendes Lernen jedoch für offene Sprachaufgaben schwer zu erreichen ist. Dies liegt vor allem daran, dass es schwierig ist, in offenen Aufgaben klare Ziele und Belohnungsmechanismen zu definieren. Wie kann man Aufgaben wie das Zusammenfassen eines Artikels, das Beantworten einer vagen Frage zur Pip-Installation, das Erzählen eines Witzes oder das Umschreiben von Java-Code in Python objektiv belohnen? Karpathy stellt diese aufschlussreiche Frage, und in diese Richtung zu gehen ist kein Prinzip. Aber es ist auch nicht einfach und erfordert etwas kreatives Denken.

Dennoch glaubt Karpathy, dass Sprachmodelle das Potenzial haben, die menschlichen Fähigkeiten zur Problemlösung wirklich zu erreichen oder sogar zu übertreffen, wenn dieses schwierige Problem gelöst werden kann. Diese Ansicht deckt sich mit einem kürzlich von Google DeepMind veröffentlichten Artikel, der darauf hinwies, dass Offenheit die Grundlage der künstlichen allgemeinen Intelligenz (AGI) ist.
Als einer von mehreren hochrangigen KI-Experten, die OpenAI in diesem Jahr verlassen haben, arbeitet Karpathy derzeit an seinem eigenen KI-Startup für den Bildungsbereich. Seine Ausführungen brachten zweifellos eine neue Dimension des Denkens in den Bereich der KI-Forschung und lieferten wertvolle Einblicke in die zukünftige Richtung der KI-Entwicklung.
Karpathys Ansichten lösten breite Diskussionen in der Branche aus. Befürworter glauben, dass er ein zentrales Thema der aktuellen KI-Forschung aufdeckt, nämlich wie man KI wirklich in die Lage versetzen kann, komplexe Probleme zu lösen, anstatt nur menschliches Verhalten zu imitieren. Gegner befürchten, dass ein vorzeitiger Verzicht auf RLHF zu einer Abweichung in der Richtung der KI-Entwicklung führen könnte.
Papieradresse: https://arxiv.org/pdf/1706.03741
Karpathys Ansichten lösten eingehende Diskussionen über die zukünftige Entwicklungsrichtung der KI aus. Seine Zweifel an RLHF veranlassten Forscher, aktuelle KI-Trainingsmethoden zu überdenken und effektivere Wege zu erkunden, mit dem ultimativen Ziel, echte künstliche Intelligenz zu erreichen.