Die rasante Entwicklung großer Sprachmodelle (LLMs) hat zu erstaunlichen Fähigkeiten zur Verarbeitung natürlicher Sprache geführt, ihre enormen Rechen- und Speicheranforderungen schränken jedoch ihre Popularität ein. Der Betrieb eines Modells mit 176 Milliarden Parametern erfordert Hunderte Gigabyte Speicherplatz und mehrere High-End-GPUs, was die Skalierung teuer und schwierig macht. Um dieses Problem zu lösen, haben sich Forscher auf Modellkomprimierungstechniken wie die Quantisierung konzentriert, um die Modellgröße und die Betriebsanforderungen zu reduzieren. Dabei besteht jedoch auch das Risiko eines Genauigkeitsverlusts.
Künstliche Intelligenz (KI) wird immer intelligenter, insbesondere große Sprachmodelle (LLMs), die natürliche Sprache hervorragend verarbeiten können. Aber wussten Sie, dass hinter diesen intelligenten KI-Gehirnen enorme Rechenleistung und Speicherplatz erforderlich sind, um sie zu unterstützen?
Ein mehrsprachiges Bloom-Modell mit 176 Milliarden Parametern benötigt mindestens 350 GB Speicherplatz, um die Gewichte des Modells zu speichern, und erfordert außerdem mehrere fortschrittliche GPUs für die Ausführung. Dies ist nicht nur kostspielig, sondern auch schwierig zu verbreiten.
Um dieses Problem zu lösen, haben Forscher eine Technik namens „Quantifizierung“ vorgeschlagen. Die Quantifizierung ist wie eine „Verkleinerung“ des KI-Gehirns. Durch die Abbildung der Gewichte und Aktivierungen des Modells auf ein Datenformat mit niedrigeren Ziffern wird nicht nur die Größe des Modells reduziert, sondern auch die Ausführungsgeschwindigkeit des Modells beschleunigt. Allerdings birgt dieser Prozess auch Risiken und es kann zu Genauigkeitsverlusten kommen.
Angesichts dieser Herausforderung entwickelten Forscher der Beihang University und SenseTime Technology gemeinsam das LLMC-Toolkit. LLMC ist wie ein persönlicher Gewichtsverlust-Coach für KI. Es kann Forschern und Entwicklern dabei helfen, den am besten geeigneten Gewichtsverlustplan zu finden, der das KI-Modell leichter machen kann, ohne sein Intelligenzniveau zu beeinträchtigen.
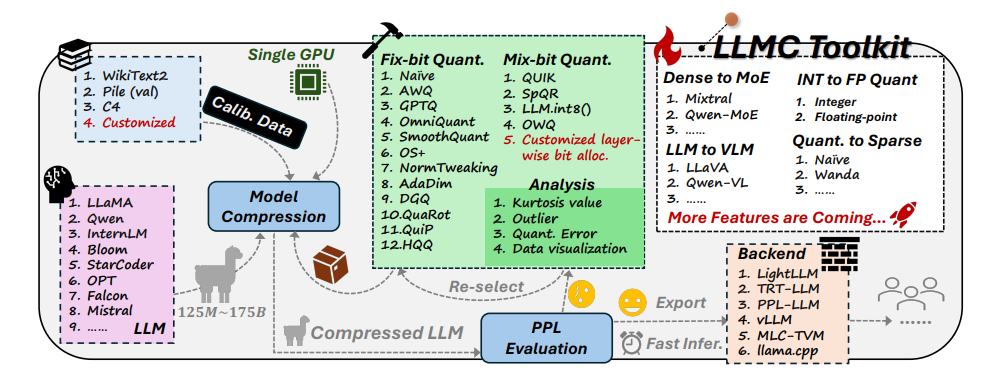
Das LLMC-Toolkit verfügt über drei Hauptfunktionen:
Diversifizierung: LLMC bietet 16 verschiedene quantitative Methoden, was der Vorbereitung von 16 verschiedenen Abnehmrezepten für KI entspricht. Ganz gleich, ob Ihre KI am ganzen Körper oder lokal abnehmen möchte, LLMC kann Ihre Bedürfnisse erfüllen.
Geringe Kosten: LLMC ist sehr ressourcenschonend und benötigt selbst für die Verarbeitung sehr großer Modelle nur wenig Hardwareunterstützung. Wenn beispielsweise nur eine 40-GB-A100-GPU verwendet wird, kann das Modell OPT-175B mit 175 Milliarden Parametern angepasst und ausgewertet werden. Das ist so effizient, als würde man einen Olympiasieger auf einem Heimlaufband trainieren!
Hohe Kompatibilität: LLMC unterstützt eine Vielzahl von Quantisierungseinstellungen und Modellformaten und ist außerdem mit einer Vielzahl von Backends und Hardwareplattformen kompatibel. Es ist wie ein Universaltrainer, der Ihnen dabei helfen kann, unabhängig von der verwendeten Ausrüstung einen passenden Trainingsplan zu entwickeln.
Praktische Anwendungen von LLMC: KI intelligenter und energieeffizienter machen
Das Aufkommen des LLMC-Toolkits bietet einen umfassenden und fairen Benchmark-Test für die Quantifizierung großer Sprachmodelle. Es berücksichtigt drei Schlüsselfaktoren: Trainingsdaten, Algorithmus und Datenformat, um Benutzern dabei zu helfen, die beste Lösung zur Leistungsoptimierung zu finden.
In praktischen Anwendungen kann LLMC Forschern und Entwicklern helfen, geeignete Algorithmen und Low-Bit-Formate effizienter zu integrieren und so die Popularisierung der Komprimierung großer Sprachmodelle zu fördern. Das bedeutet, dass wir in Zukunft möglicherweise leichtere, aber ebenso leistungsstarke KI-Anwendungen sehen werden.
Die Autoren des Papiers teilten auch einige interessante Erkenntnisse und Vorschläge mit:
Bei der Auswahl von Trainingsdaten sollten Sie einen Datensatz wählen, der hinsichtlich der Vokabularverteilung den Testdaten ähnlicher ist, genau wie Menschen, die Gewicht verlieren, entsprechend ihren eigenen Umständen geeignete Rezepte auswählen müssen.
Im Hinblick auf Quantifizierungsalgorithmen untersuchten sie die Auswirkungen der drei Haupttechniken Transformation, Zuschneiden und Rekonstruktion sowie den Vergleich der Auswirkungen verschiedener Trainingsmethoden auf die Gewichtsabnahme.
Bei der Wahl zwischen Ganzzahl- und Gleitkomma-Quantisierung stellten sie fest, dass die Gleitkomma-Quantisierung bei der Bewältigung komplexer Situationen größere Vorteile bietet, während die Ganzzahl-Quantisierung in einigen Sonderfällen möglicherweise besser ist. Es ist, als wären in verschiedenen Phasen der Gewichtsabnahme unterschiedliche Trainingsintensitäten erforderlich.
Das Aufkommen des LLMC-Toolkits hat einen neuen Trend in den KI-Bereich gebracht. Es stellt nicht nur einen leistungsstarken Assistenten für Forscher und Entwickler dar, sondern zeigt auch die Richtung für die zukünftige Entwicklung der KI auf. Durch LLMC können wir mit leichteren, leistungsstarken KI-Anwendungen rechnen, die es KI ermöglichen, wirklich in unser tägliches Leben einzudringen.
Projektadresse: https://github.com/ModelTC/llmc
Papieradresse: https://arxiv.org/pdf/2405.06001
Alles in allem bietet das LLMC-Toolkit eine effektive Lösung zur Lösung des Ressourcenverbrauchsproblems großer Sprachmodelle. Es reduziert nicht nur die Kosten und den Schwellenwert des Modellbetriebs, sondern verbessert auch die Effizienz und Benutzerfreundlichkeit des Modells, indem es eine Injektion in das Modell einfügt Popularisierung und Entwicklung neuer Vitalität. In Zukunft können wir uns auf das Aufkommen leichterer KI-Anwendungen auf Basis von LLMC freuen, die unser Leben komfortabler machen.