Im boomenden Bereich der KI rücken Datenerfassungsmethoden zunehmend in den Fokus. In diesem Artikel wird die Kontroverse untersucht, die durch das groß angelegte Data-Scraping-Verhalten des Claude-Teams des KI-Unternehmens Anthropic verursacht wurde. Das Crawler-Programm ClaudeBot des Claude-Teams hat ohne Genehmigung große Datenmengen von mehreren Websites gecrawlt, was nicht nur gegen die Website-Bestimmungen verstieß, sondern auch zu einem enormen Verbrauch von Serverressourcen führte, was weit verbreitete Kritik und Besorgnis auslöste. Dieser Vorfall verdeutlicht den Widerspruch zwischen der KI-Entwicklung und dem Schutz des Datenurheberrechts und veranlasst die Branche, die Ethik und rechtlichen Normen der Datenerfassung zu überdenken.
Die Ursache des Vorfalls war, dass der Crawler von Claudes Team den Server eines Unternehmens innerhalb von 24 Stunden 1 Million Mal besuchte und dabei Website-Inhalte kostenlos crawlte. Dieses Verhalten ignorierte nicht nur eklatant die Ankündigung des Crawling-Verbots der Website, sondern beanspruchte auch zwangsweise eine große Menge an Serverressourcen.
Trotz aller Bemühungen, sich zu verteidigen, gelang es dem Opferunternehmen letztlich nicht, Claudes Team an der Datenbeschaffung zu hindern. Die Unternehmensleiter nutzten wütend die sozialen Medien, um die Aktionen von Claudes Team zu verurteilen. Viele Internetnutzer äußerten ebenfalls ihre Unzufriedenheit, und einige schlugen sogar vor, dieses Verhalten mit dem Wort „Stehlen“ zu beschreiben.
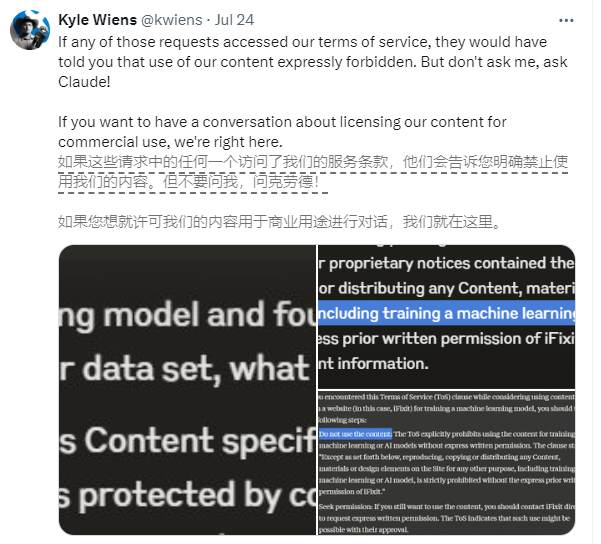
Bei dem beteiligten Unternehmen handelt es sich um iFixit, eine amerikanische E-Commerce- und How-to-Website. iFixit bietet Millionen von Seiten mit kostenlosen Online-Reparaturanleitungen für Unterhaltungselektronik und Gadgets. iFixit stellte jedoch fest, dass Claudes Crawler-Programm ClaudeBot in kurzer Zeit eine große Anzahl von Anfragen initiierte und an einem Tag auf 10 TB Dateien und im gesamten Monat Mai auf insgesamt 73 TB zugriff.
Kyle Wiens, CEO von iFixit, sagte, dass ClaudeBot ohne Erlaubnis alle ihre Daten gestohlen und Serverressourcen belegt habe. Obwohl iFixit auf seiner Website ausdrücklich darauf hinweist, dass unbefugtes Daten-Scraping verboten ist, scheint das Claude-Team diesbezüglich ein Auge zuzudrücken.
Das Verhalten von Claudes Team ist nicht einzigartig. Im April dieses Jahres litt das Linux Mint-Forum auch unter den häufigen Besuchen von ClaudeBot, was dazu führte, dass das Forum langsamer lief oder sogar abstürzte. Darüber hinaus wiesen einige Stimmen darauf hin, dass es neben Claude und OpenAIs GPT noch viele andere KI-Unternehmen gibt, die ebenfalls die robots.txt-Einstellungen der Website ignorieren und gewaltsam Daten abgreifen.
Angesichts dieser Situation wurde vorgeschlagen, dass Websitebesitzer gefälschte Inhalte mit nachvollziehbaren oder eindeutigen Informationen auf der Seite hinzufügen, um festzustellen, ob die Daten illegal gescrapt wurden. iFixit hat diesen Schritt tatsächlich getan und herausgefunden, dass ihre Daten nicht nur von Claude, sondern auch von OpenAI gescrapt wurden.
Der Vorfall löste eine breite Diskussion über die Data-Scraping-Praktiken von KI-Unternehmen aus. Einerseits erfordert die Entwicklung von KI eine große Datenmenge, um sie zu unterstützen; andererseits sollte die Datenerfassung auch die Rechte und Vorschriften des Website-Eigentümers respektieren. Wie man ein Gleichgewicht zwischen der Förderung des technischen Fortschritts und dem Schutz des Urheberrechts findet, ist eine Frage, über die sich die gesamte Branche Gedanken machen muss.
Der Vorfall der Datenerfassung durch Claudes Team löste Alarm aus und erinnerte KI-Unternehmen daran, dass sie bei der Verfolgung des technologischen Fortschritts die Rechte an geistigem Eigentum respektieren, Gesetze und Vorschriften einhalten und aktiv nach gesetzeskonformen Wegen zur Datenbeschaffung suchen müssen. Nur so können wir die gesunde Entwicklung der KI-Technologie sicherstellen und vermeiden, dass der Ruf der Branche und das öffentliche Vertrauen durch unangemessenes Verhalten geschädigt werden.