Das neu veröffentlichte Zamba2-2.7B-Sprachmodell von Zyphra sorgt im Bereich der kleinen Sprachmodelle für Aufsehen. Dieses Modell reduziert den Bedarf an Inferenzressourcen erheblich und bietet gleichzeitig eine mit dem 7B-Modell vergleichbare Leistung, wodurch es sich ideal für Anwendungen auf Mobilgeräten eignet. Zamba2-2.7B hat die Reaktionsgeschwindigkeit, Speichernutzung und Latenz deutlich verbessert, was für Anwendungen, die Echtzeitinteraktion erfordern, wie virtuelle Assistenten und Chatbots, von entscheidender Bedeutung ist. Sein verbesserter Interleaved-Shared-Attention-Mechanismus und der LoRA-Projektor sorgen für eine effiziente Bearbeitung komplexer Aufgaben.
Kürzlich hat Zyphra das neue Sprachmodell Zamba2-2.7B veröffentlicht. Diese Veröffentlichung ist von großer Bedeutung in der Geschichte der Entwicklung kleiner Sprachmodelle. Das neue Modell erzielt erhebliche Leistungs- und Effizienzsteigerungen, da sein Trainingsdatensatz etwa 3 Billionen Token erreicht und es in seiner Leistung mit Zamba1-7B und anderen führenden 7B-Modellen vergleichbar ist.
Das Überraschendste ist, dass der Ressourcenbedarf von Zamba2-2.7B während der Inferenz deutlich reduziert wird, was es zu einer effizienten Lösung für Anwendungen auf Mobilgeräten macht.
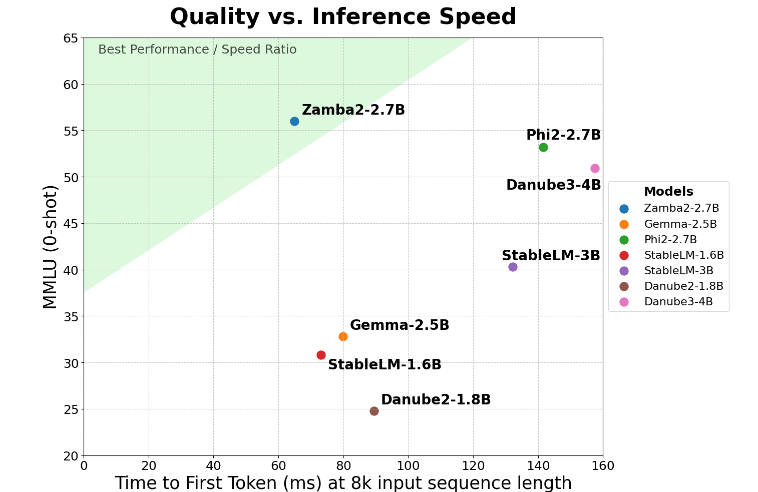
Zamba2-2.7B erreicht eine zweifache Verbesserung der Schlüsselmetrik „Reaktionszeit bei der ersten Generierung“, was bedeutet, dass es erste Antworten schneller als die Konkurrenz generieren kann. Dies ist von entscheidender Bedeutung für Anwendungen wie virtuelle Assistenten und Chatbots, die eine Interaktion in Echtzeit erfordern.
Neben der Geschwindigkeitsverbesserung leistet Zamba2-2.7B auch hervorragende Arbeit bei der Speichernutzung. Es reduziert den Speicheraufwand um 27 % und eignet sich daher ideal für den Einsatz auf Geräten mit begrenzten Speicherressourcen. Eine solche intelligente Speicherverwaltung stellt sicher, dass das Modell in Umgebungen mit begrenzten Rechenressourcen effektiv ausgeführt werden kann und erweitert seinen Anwendungsbereich auf verschiedenen Geräten und Plattformen.
Zamba2-2.7B hat außerdem den erheblichen Vorteil einer geringeren Build-Latenz. Im Vergleich zu Phi3-3.8B ist seine Latenz um das 1,29-fache reduziert, was die Interaktion reibungsloser macht. Eine niedrige Latenz ist besonders wichtig bei Anwendungen, die eine nahtlose, kontinuierliche Kommunikation erfordern, wie z. B. Kundendienst-Bots und interaktive Bildungstools. Daher ist Zamba2-2.7B zweifellos die erste Wahl für Entwickler, wenn es um die Verbesserung der Benutzererfahrung geht.
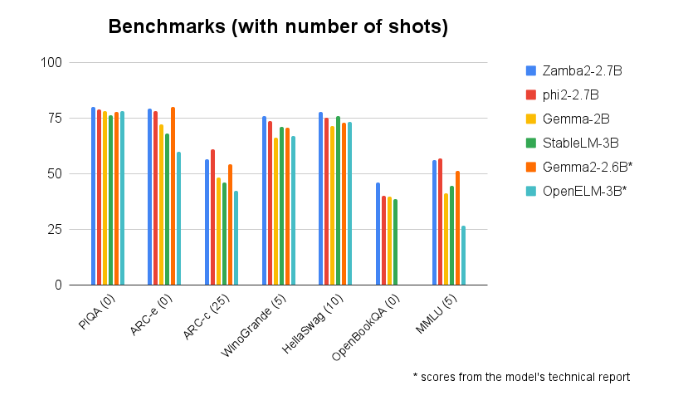
Zamba2-2.7B schneidet bei Benchmark-Vergleichen mit anderen Modellen ähnlicher Größe durchweg besser ab. Seine überragende Leistung ist ein Beweis für die Innovationskraft und Bemühungen von Zyphra, die Entwicklung der Technologie der künstlichen Intelligenz voranzutreiben. Dieses Modell nutzt einen verbesserten Interleaved-Shared-Attention-Mechanismus und ist mit einem LoRA-Projektor auf einem Shared-MLP-Modul ausgestattet, um eine leistungsstarke Ausgabe bei der Bearbeitung komplexer Aufgaben zu gewährleisten.
Modelleingang: https://huggingface.co/Zyphra/Zamba2-2.7B
Höhepunkte:
Das Modell Zamba2-27B verdoppelt die erste Reaktionszeit und eignet sich somit für interaktive Echtzeitanwendungen.
?Dieses Modell reduziert den Speicheraufwand um 27 % und ist für Geräte mit begrenzten Ressourcen geeignet.
In Bezug auf die Generationsverzögerung übertrifft Zamba2-2.7B ähnliche Modelle und verbessert so das Benutzererlebnis.
Kurz gesagt, Zamba2-2.7B hat mit seiner hervorragenden Leistung und Effizienz einen neuen Maßstab für kleine Sprachmodelle gesetzt, bietet Entwicklern leistungsfähigere und flexiblere KI-Tools und wird voraussichtlich eine wichtige Rolle in mobilen Anwendungen spielen. Seine effiziente Ressourcennutzung und das reibungslose Benutzererlebnis machen es zu einer wichtigen treibenden Kraft für die Entwicklung zukünftiger KI-Anwendungen.