Metas Erfahrung beim Training des groß angelegten Sprachmodells Llama 3.1 hat uns beispiellose Herausforderungen und Chancen bei der Entwicklung von KI aufgezeigt. Der riesige Cluster von 16.384 GPUs erlitt während des 54-tägigen Trainingszeitraums durchschnittlich alle 3 Stunden einen Ausfall. Dies verdeutlichte nicht nur das schnelle Wachstum des Umfangs des KI-Modells, sondern machte auch den enormen Engpass in der Stabilität des Supercomputings deutlich System. In diesem Artikel wird auf die Herausforderungen eingegangen, denen Meta während des Llama 3.1-Schulungsprozesses begegnet ist, auf die Strategien, die Meta zur Bewältigung dieser Herausforderungen angewendet hat, und auf die Auswirkungen auf die gesamte KI-Branche analysiert werden.
In der Welt der künstlichen Intelligenz geht jeder Durchbruch mit atemberaubenden Daten einher. Stellen Sie sich vor, dass 16.384 GPUs gleichzeitig laufen. Dies ist keine Szene aus einem Science-Fiction-Film, sondern eine echte Darstellung von Meta beim Training des neuesten Llama3.1-Modells. Allerdings verbirgt sich hinter diesem technischen Fest ein Fehler, der durchschnittlich alle 3 Stunden auftritt. Diese erstaunliche Zahl zeigt nicht nur die Geschwindigkeit der KI-Entwicklung, sondern verdeutlicht auch die enormen Herausforderungen, vor denen die aktuelle Technologie steht.
Von den 2.028 GPUs, die in Llama1 verwendet werden, auf die 16.384 GPUs, die in Llama3.1 verwendet werden, ist dieses sprunghafte Wachstum nicht nur eine Änderung der Menge, sondern auch eine extreme Herausforderung für die Stabilität des bestehenden Supercomputersystems. Die Forschungsdaten von Meta zeigen, dass während des 54-tägigen Trainingszyklus von Llama3.1 insgesamt 419 unerwartete Komponentenausfälle auftraten, von denen etwa die Hälfte mit der H100-GPU und ihrem HBM3-Speicher zusammenhing. Diese Daten lassen uns nachdenken: Hat sich bei der Suche nach Durchbrüchen in der KI-Leistung gleichzeitig auch die Zuverlässigkeit des Systems verbessert?
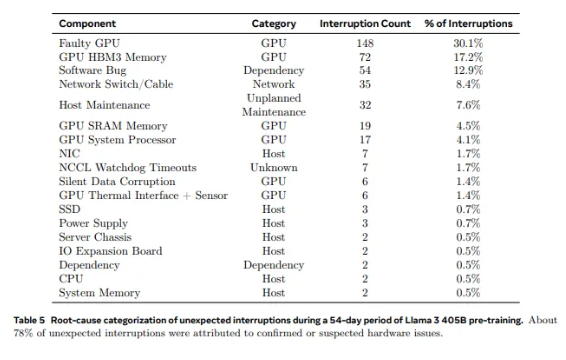
Tatsächlich gibt es im Bereich Supercomputing eine unbestreitbare Tatsache: Je größer der Maßstab, desto schwieriger ist es, Ausfälle zu vermeiden. Metas Llama 3.1-Trainingscluster besteht aus Zehntausenden Prozessoren, Hunderttausenden anderen Chips und Hunderten Kilometern Kabeln, eine Komplexität, die mit der des neuronalen Netzwerks einer Kleinstadt vergleichbar ist. Bei einem solchen Giganten scheinen Fehlfunktionen an der Tagesordnung zu sein.
Angesichts häufiger Ausfälle war das Meta-Team nicht hilflos. Sie führten eine Reihe von Bewältigungsstrategien ein: Verkürzung der Job-Anfangs- und Checkpoint-Zeiten, Entwicklung proprietärer Diagnosetools, Nutzung des NCCL-Flugschreibers von PyTorch usw. Diese Maßnahmen verbessern nicht nur die Fehlertoleranz des Systems, sondern erhöhen auch die Möglichkeiten der automatisierten Verarbeitung. Die Ingenieure von Meta sind wie moderne Feuerwehrleute und bereit, alle Brände zu löschen, die den Trainingsprozess stören könnten.
Die Herausforderungen liegen jedoch nicht nur in der Hardware selbst. Auch Umweltfaktoren und Schwankungen des Stromverbrauchs stellen Supercomputing-Cluster vor unerwartete Herausforderungen. Das Meta-Team stellte fest, dass Temperaturschwankungen bei Tag und Nacht sowie drastische Schwankungen des GPU-Stromverbrauchs einen erheblichen Einfluss auf die Trainingsleistung haben. Diese Entdeckung erinnert uns daran, dass wir bei der Suche nach technologischen Durchbrüchen die Bedeutung des Umwelt- und Energieverbrauchsmanagements nicht außer Acht lassen dürfen.
Der Trainingsprozess von Llama3.1 kann als ultimativer Test der Stabilität und Zuverlässigkeit des Supercomputersystems bezeichnet werden. Die Strategien des Meta-Teams zur Bewältigung von Herausforderungen und die entwickelten automatisierten Tools liefern wertvolle Erfahrungen und Inspiration für die gesamte KI-Branche. Trotz der Schwierigkeiten haben wir Grund zu der Annahme, dass zukünftige Supercomputing-Systeme mit der kontinuierlichen Weiterentwicklung der Technologie leistungsfähiger und stabiler sein werden.
In dieser Zeit der rasanten Entwicklung der KI-Technologie ist Metas Versuch zweifellos ein mutiges Abenteuer. Es verschiebt nicht nur die Leistungsgrenzen von KI-Modellen, sondern zeigt uns auch die wahren Herausforderungen, denen wir bei der Verfolgung der Grenzen gegenüberstehen. Freuen wir uns auf die unendlichen Möglichkeiten, die die KI-Technologie bietet, und loben wir gleichzeitig die Ingenieure, die unermüdlich an der Spitze der Technologie arbeiten. Jeder Versuch, jeder Misserfolg und jeder Durchbruch, den sie erzielen, ebnet den Weg für den technischen Fortschritt der Menschheit.
Referenzen:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- ein-Fehler-alle-drei-Stunden-für-metas-16384-gpu-training-cluster
Der Trainingsfall von Llama 3.1 hat uns wertvolle Lektionen geliefert und die zukünftige Entwicklungsrichtung von Supercomputing-Systemen aufgezeigt: Während wir Leistung anstreben, müssen wir großen Wert auf Systemstabilität und -zuverlässigkeit legen und aktiv Strategien für den Umgang mit verschiedenen Ausfällen erforschen. Nur so können wir die kontinuierliche und stabile Entwicklung der KI-Technologie zum Nutzen der Menschheit sicherstellen.