Der Metawissenschaftler Thomas Scialom erläuterte den Entwicklungsprozess von Llama 3.1 ausführlich im Latent Space-Podcast und gab einen Ausblick auf die Entwicklungsrichtung von Llama 4. Llama 3.1 ist kein einfaches Parameter-Stacking, sondern ein Kompromiss zwischen Parametergröße, Trainingszeit und Hardware-Einschränkungen. Seine 405B-Parametergröße ist eine Reaktion auf GPT-4o. Obwohl die enorme Modellgröße die Ausführung auf normalen Computern erschwert, ermöglicht die Open-Source-Funktion mehr Menschen die Teilnahme und die Förderung der technologischen Entwicklung.
Die Geburt von Llama3.1 ist ein perfektes Gleichgewicht zwischen Parameterskala, Trainingszeit und Hardwarebeschränkungen. Der riesige Körper von 405B ist keine zufällige Wahl, sondern eine Herausforderung von Meta an GPT-4o. Obwohl Hardwareeinschränkungen verhindern, dass Llama3.1 auf jedem Heimcomputer läuft, macht die Leistungsfähigkeit der Open-Source-Community alles möglich.
Während der Entwicklung von Llama 3.1 haben Scialom und sein Team das Skalierungsgesetz erneut untersucht. Sie fanden heraus, dass die Modellgröße tatsächlich entscheidend war, wichtiger war jedoch die Gesamtmenge der Trainingsdaten. Llama3.1 entschied sich dafür, die Anzahl der Trainingstoken zu erhöhen, auch wenn dies den Aufwand für mehr Rechenleistung bedeutete.
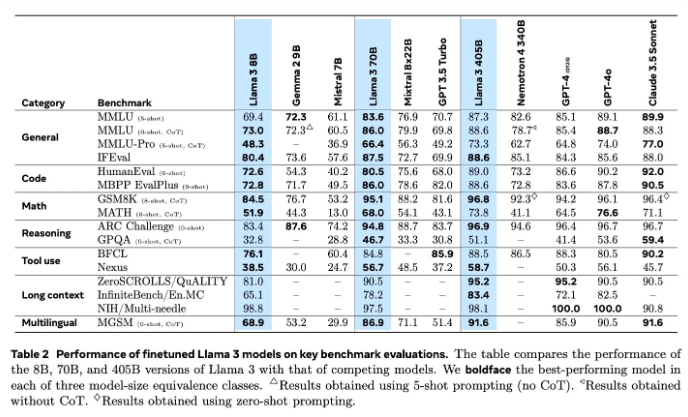
Es gibt keine weltbewegenden Änderungen in der Architektur von Llama 3.1, aber Meta hat große Anstrengungen in Bezug auf Umfang und Qualität der Daten unternommen. Der 15T-Token-Ozean hat Llama3.1 einen qualitativen Sprung in der Tiefe und Breite des Wissens beschert.
In Bezug auf die Datenauswahl ist Scialom fest davon überzeugt, dass es im öffentlichen Internet zu viel Textmüll gibt und das wahre Gold synthetische Daten sind. Im Post-Training-Prozess von Llama3.1 wurden überhaupt keine manuell geschriebenen Antworten verwendet, sondern man verließ sich vollständig auf die von Llama2 generierten synthetischen Daten.
Die Modellbewertung war im KI-Bereich schon immer ein schwieriges Problem. Llama3.1 hat verschiedene Methoden zur Bewertung und Verbesserung ausprobiert, darunter Belohnungsmodelle und verschiedene Benchmark-Tests. Die eigentliche Herausforderung besteht jedoch darin, die richtigen Impulse zu finden, mit denen leistungsstarke Modelle besiegt werden können.
Meta hat im Juni mit der Schulung von Llama4 begonnen und dieses Mal haben sie sich auf die Agententechnologie konzentriert. Die Entwicklung von Agententools wie Toolformer läutet Metas neue Erkundung im Bereich der KI ein.
Die Open Source von Llama3.1 ist nicht nur ein mutiger Versuch von Meta, sondern auch ein tiefgreifender Gedanke über die Zukunft der KI. Mit der Einführung von Llama4 haben wir Grund zu der Annahme, dass Meta weiterhin führend in der KI sein wird. Freuen wir uns darauf, wie Llama4 und die Agententechnologie die Zukunft der KI neu definieren werden.
Durch ein tiefes Verständnis des F&E-Prozesses von Llama 3.1 können wir Metas kontinuierliche Innovation und Bemühungen im Bereich groß angelegter Sprachmodelle sowie seinen Schwerpunkt auf der Open-Source-Community erkennen. Die Forschungs- und Entwicklungsrichtung von Llama 4 weist auch auf den zukünftigen Entwicklungstrend der KI-Technologie hin, der es wert ist, abzuwarten und zu beobachten. Seien wir gespannt, wie sich die KI-Technologie in Zukunft entwickeln wird.