NVIDIA hat kürzlich die Minitron-Serie kleiner Sprachmodelle veröffentlicht, darunter die Versionen 4B und 8B. Dieser Schritt zielt darauf ab, die Schulungs- und Bereitstellungskosten großer Sprachmodelle zu senken und mehr Entwicklern die einfache Nutzung dieser fortschrittlichen Technologie zu ermöglichen. Durch „Pruning“- und „Wissensdestillations“-Technologien reduziert das Minitron-Modell die Modellgröße erheblich und behält gleichzeitig eine mit großen Modellen vergleichbare Leistung bei. In einigen Indikatoren übertrifft es sogar andere bekannte Modelle. Dies ist von großer Bedeutung für die Förderung der Popularisierung der Technologie der künstlichen Intelligenz.
Vor kurzem hat NVIDIA neue Schritte im Bereich der künstlichen Intelligenz unternommen und die Minitron-Serie kleiner Sprachmodelle auf den Markt gebracht, darunter die Versionen 4B und 8B. Diese Modelle erhöhen nicht nur die Trainingsgeschwindigkeit um das ganze 40-fache, sondern erleichtern Entwicklern auch den Einsatz für verschiedene Anwendungen, etwa für Übersetzungen, Stimmungsanalysen und Konversations-KI.
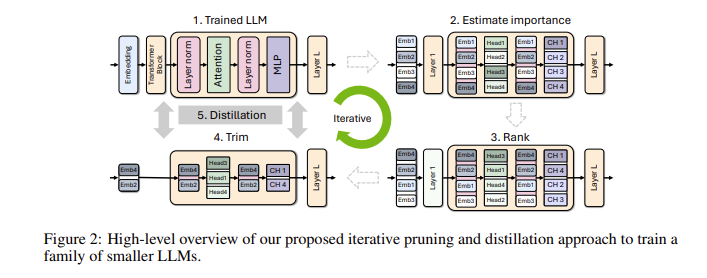
Sie fragen sich vielleicht, warum kleine Sprachmodelle so wichtig sind. Obwohl herkömmliche große Sprachmodelle eine starke Leistung aufweisen, sind ihre Schulungs- und Bereitstellungskosten sehr hoch und sie erfordern häufig große Mengen an Rechenressourcen und Daten. Um diese fortschrittlichen Technologien für mehr Menschen erschwinglich zu machen, hat sich das Forschungsteam von NVIDIA einen brillanten Weg einfallen lassen: die Kombination zweier Technologien: „Bereinigung“ und „Wissensdestillation“, um die Größe des Modells effizient zu reduzieren.
Konkret werden die Forscher zunächst von einem vorhandenen großen Modell ausgehen und es bereinigen. Sie bewerten die Wichtigkeit jedes Neurons, jeder Schicht oder jedes Aufmerksamkeitskopfes im Modell und entfernen diejenigen, die weniger wichtig sind. Auf diese Weise wird das Modell deutlich kleiner und auch der Ressourcen- und Zeitaufwand für das Training wird deutlich reduziert. Als nächstes werden sie auch einen kleinen Datensatz verwenden, um ein Wissensdestillationstraining für das beschnittene Modell durchzuführen, um die Genauigkeit des Modells wiederherzustellen. Überraschenderweise spart dieser Prozess nicht nur Geld, sondern verbessert auch die Leistung des Modells!
Bei tatsächlichen Tests erzielte das Forschungsteam von NVIDIA gute Ergebnisse mit der Nemotron-4-Modellfamilie. Sie konnten die Modellgröße erfolgreich um das Zwei- bis Vierfache reduzieren und dabei eine ähnliche Leistung beibehalten. Noch spannender ist, dass das 8B-Modell andere bekannte Modelle wie Mistral7B und LLaMa-38B in mehreren Indikatoren übertrifft und während des Trainingsprozesses ganze 40-mal weniger Trainingsdaten benötigt, was 1,8-mal weniger Rechenkosten einspart. Stellen Sie sich vor, was das bedeutet? Mehr Entwickler können leistungsstarke KI-Funktionen mit weniger Ressourcen und Kosten nutzen!
NVIDIA stellt diese optimierten Minitron-Modelle als Open Source auf Huggingface zur Verfügung, sodass jeder sie frei nutzen kann.
Demo-Zugang: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Höhepunkte:
** Verbesserte Trainingsgeschwindigkeit **: Die Trainingsgeschwindigkeit des Minitron-Modells ist 40-mal schneller als bei herkömmlichen Modellen, sodass Entwickler Zeit und Mühe sparen können.
**Kosteneinsparungen**: Durch Pruning- und Wissensdestillationstechnologie werden die für das Training erforderlichen Rechenressourcen und Datenmengen erheblich reduziert.
? **Open-Source-Sharing**: Das Minitron-Modell wurde auf Huggingface als Open-Source-Version bereitgestellt, sodass mehr Menschen problemlos darauf zugreifen und es nutzen können, was die Popularisierung der KI-Technologie fördert.
Die offene Quelle des Minitron-Modells stellt einen wichtigen Durchbruch in der praktischen Anwendung kleiner Sprachmodelle dar. Es zeigt auch, dass die Technologie der künstlichen Intelligenz beliebter und einfacher zu verwenden sein wird, wodurch mehr Entwickler und Anwendungsszenarien unterstützt werden. In Zukunft können wir mit weiteren ähnlichen Innovationen rechnen, die die kontinuierliche Weiterentwicklung der Technologie der künstlichen Intelligenz vorantreiben werden.