Das neueste von Nvidia AI veröffentlichte ChatQA2-Modell hat bedeutende Durchbrüche im Bereich des Langtextkontextverständnisses und der Retrieval Enhanced Generation (RAG) erzielt. Es basiert auf dem leistungsstarken Llama3-Modell, das durch die Erweiterung des Kontextfensters auf 128.000 Token und die Einführung einer dreistufigen Feinabstimmung der Anweisungen die Fähigkeiten zur Befehlsfolge, die RAG-Leistung und die Fähigkeiten zum Verstehen von Langtexten erheblich verbessert. ChatQA2 ist in der Lage, bei der Verarbeitung umfangreicher Textdaten kontextbezogene Kohärenz und einen hohen Erinnerungswert aufrechtzuerhalten und hat in mehreren Benchmark-Tests eine mit GPT-4-Turbo vergleichbare Leistung gezeigt und diese in einigen Aspekten sogar übertroffen. Dies stellt einen erheblichen Fortschritt in der Fähigkeit großer Sprachmodelle dar, lange Texte zu verarbeiten.
Durchbruch bei der Leistung: ChatQA2 verbessert die Befehlsverfolgungsfähigkeiten, die RAG-Leistung und das Langtextverständnis erheblich, indem das Kontextfenster auf 128.000 Token erweitert und ein dreistufiger Befehlsanpassungsprozess eingeführt wird. Dieser technologische Durchbruch ermöglicht es dem Modell, bei der Verarbeitung von Datensätzen mit bis zu 1 Milliarde Token kontextbezogene Kohärenz und einen hohen Rückruf aufrechtzuerhalten.
Technische Details: ChatQA2 wurde unter Verwendung detaillierter und reproduzierbarer technischer Lösungen entwickelt. Das Modell erweitert zunächst das Kontextfenster von Llama3-70B durch kontinuierliches Vortraining von 8.000 auf 128.000 Token. Als nächstes wurde ein dreistufiger Befehlsoptimierungsprozess angewendet, um sicherzustellen, dass das Modell eine Vielzahl von Aufgaben effektiv bewältigen kann.
Bewertungsergebnisse: In der InfiniteBench-Bewertung erreichte ChatQA2 bei Aufgaben wie Langtextzusammenfassung, Frage und Antwort, Multiple Choice und Dialog eine mit GPT-4-Turbo-2024-0409 vergleichbare Genauigkeit und übertraf diese beim RAG-Benchmark. Dieser Erfolg unterstreicht die umfassenden Fähigkeiten von ChatQA2 über verschiedene Kontextlängen und Funktionen hinweg.
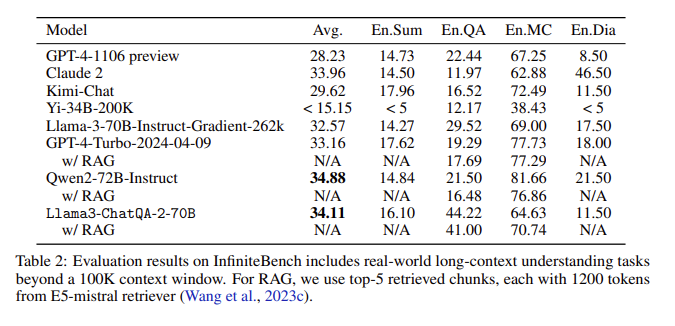
Lösung wichtiger Probleme: ChatQA2 zielt auf wichtige Probleme im RAG-Prozess ab, wie z. B. Kontextfragmentierung und geringe Erinnerung, indem es einen hochmodernen Langtext-Retriever verwendet, um die Genauigkeit und Effizienz des Abrufs zu verbessern.
Durch die Erweiterung des Kontextfensters und die Implementierung eines dreistufigen Befehlsoptimierungsprozesses erreicht ChatQA2 ein Langtextverständnis und eine RAG-Leistung, die mit GPT-4-Turbo vergleichbar ist. Dieses Modell bietet flexible Lösungen für eine Vielzahl nachgelagerter Aufgaben und vereint Genauigkeit und Effizienz durch fortschrittliche Langtext- und abrufgestützte Generierungstechniken.
Papiereingang: https://arxiv.org/abs/2407.14482
Das Aufkommen von ChatQA2 bringt neue Möglichkeiten für die Langtextverarbeitung und RAG-Anwendungen. Seine Effizienz und Genauigkeit bieten einen wichtigen Referenzwert für die zukünftige Entwicklung der künstlichen Intelligenz. Die offene Forschung zu diesem Modell fördert auch die Zusammenarbeit zwischen Wissenschaft und Industrie und treibt so den kontinuierlichen Fortschritt auf diesem Gebiet voran. Freuen Sie sich darauf, in Zukunft weitere innovative Anwendungen auf Basis dieses Modells zu sehen.