Llama 3.1, dieses riesige Open-Source-Sprachmodell mit 405 Milliarden Parametern, sorgte aufgrund von Leaks ohne offizielle Veröffentlichung für einen großen Schock im KI-Bereich. Seine Leistung ist so leistungsstark, dass es in einigen Benchmark-Tests sogar GPT-4o übertrifft und damit einen neuen Maßstab für Open-Source-Modelle setzt. Die hitzige Diskussion auf Reddit beweist einmal mehr seinen Einfluss auf die KI-Community. Dieser Artikel befasst sich mit der Leistung, den Highlights und Sicherheitsmaßnahmen von Llama 3.1 und enthüllt dieses mysteriöse Modell.
Llama3.1 ist durchgesickert! Sie haben es richtig gehört, dieses Open-Source-Modell mit 405 Milliarden Parametern hat auf Reddit für Aufruhr gesorgt. Dies ist wahrscheinlich das Open-Source-Modell, das GPT-4o bisher am nächsten kommt und es in einigen Aspekten sogar übertrifft.
Llama3.1 ist ein großes Sprachmodell, das von Meta (ehemals Facebook) entwickelt wurde. Obwohl es noch keine offizielle Veröffentlichung gibt, hat die geleakte Version bereits für Aufsehen in der Community gesorgt. Dieses Modell umfasst nicht nur das Basismodell, sondern auch Benchmark-Ergebnisse von 8B, 70B und den maximalen Parameter von 405B.
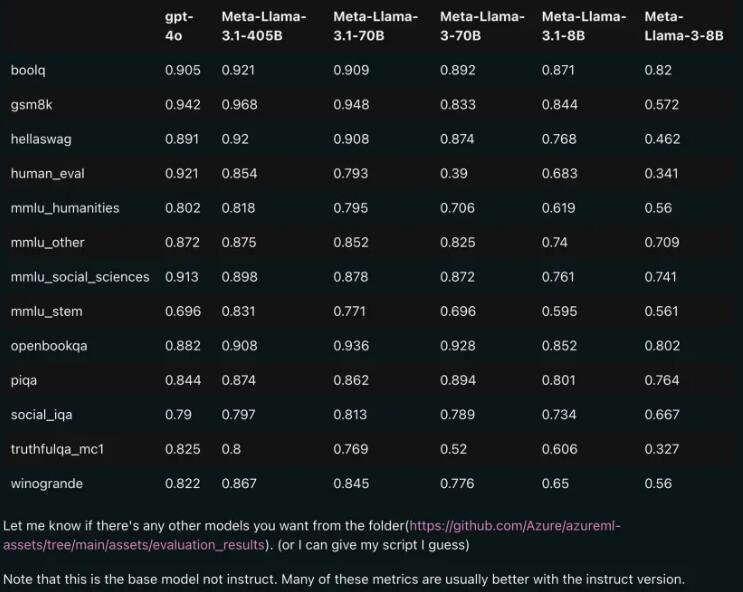
Leistungsvergleich: Llama3.1 vs. GPT-4o
Den durchgesickerten Vergleichsergebnissen zufolge übertraf sogar die 70B-Version von Llama3.1 GPT-4o in mehreren Benchmark-Tests. Dies ist das erste Mal, dass ein Open-Source-Modell bei mehreren Benchmarks das SOTA-Niveau (State of the Art, die fortschrittlichste Technologie) erreicht hat. Die Leute können nicht anders, als zu seufzen: Die Leistungsfähigkeit von Open Source ist wirklich mächtig!
Modell-Highlights: Mehrsprachenunterstützung, umfangreichere Trainingsdaten
Das Llama3.1-Modell verwendet mehr als 15T-Token aus öffentlichen Quellen für das Training, und die Frist für die Daten vor dem Training endet im Dezember 2023. Es unterstützt nicht nur Englisch, sondern auch Französisch, Deutsch, Hindi, Italienisch, Portugiesisch, Spanisch und Thailändisch. Dies macht es ideal für mehrsprachige Konversationsanwendungsfälle.

Das Llama3.1-Forschungsteam legt großen Wert auf die Sicherheit des Modells. Sie nutzten einen vielschichtigen Datenerfassungsansatz, der von Menschen generierte und synthetische Daten kombinierte, um potenzielle Sicherheitsrisiken zu mindern. Darüber hinaus führt das Modell auch Grenz-Prompts und kontradiktorische Prompts ein, um die Datenqualitätskontrolle zu verbessern.
Quelle der Modellkarte: https://pastebin.com/9jGkYbXY#google_vignette
Das Leck von Llama 3.1 wird zweifellos tiefgreifende Auswirkungen auf den KI-Bereich haben. Es zeigt nicht nur das enorme Potenzial von Open-Source-Modellen, sondern regt auch zum weiteren Nachdenken über Modellsicherheit und ethische Fragen an. Wir werden Llama 3.1 und seine weitere Entwicklung auch in Zukunft im Auge behalten und freuen uns darauf, dass es weitere Überraschungen für die Weiterentwicklung der KI-Technologie mit sich bringt.