Der Wettbewerb im Bereich der künstlichen Intelligenz ist hart und der Aufstieg von Open-Source-Modellen stellt die Dominanz der Technologiegiganten in Frage. Kürzlich veröffentlichte das Hardware-Startup für künstliche Intelligenz Groq zwei Open-Source-Sprachmodelle – Llama-3-Groq-70B-Tool-Use und Llama3Groq Tool Use 8B – und erzielte beeindruckende Ergebnisse beim Berkeley Function Call Ranking (BFCL). Darunter der 70B-Parameter Version übertraf die proprietären Modelle von OpenAI, Google, Anthropic und anderen Unternehmen. Der Erfolg dieser Modelle liegt nicht nur in ihrer leistungsstarken Leistung, sondern auch in der Verwendung ethisch erzeugter synthetischer Daten während des Trainingsprozesses, wodurch Probleme wie Datenschutz und Überanpassung wirksam gelöst werden und neue Möglichkeiten für die nachhaltige Entwicklung des Fachgebiets entstehen Beispiel künstlicher Intelligenz.
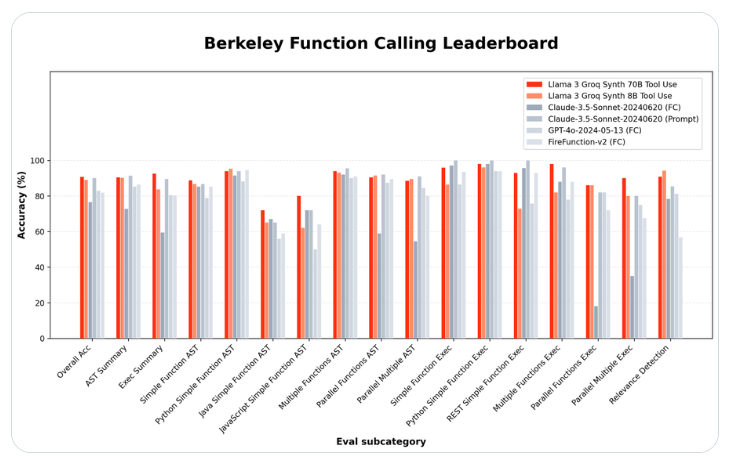
Das Hardware-Startup für künstliche Intelligenz Groq hat zwei Open-Source-Sprachmodelle veröffentlicht, die die Technologiegiganten in ihrer Fähigkeit, spezielle Tools zu verwenden, übertreffen. Das neue Llama-3-Groq-70B-Tool-Use-Modell hat den Spitzenplatz im Berkeley Function Call Ranking (BFCL) erobert und übertrifft proprietäre Produkte von Unternehmen wie OpenAI, Google und Anthropic.
Groq-Projektleiter Rick Lamers gab den Durchbruch in einem Artikel auf X.com bekannt. Er sagte: „Ich bin stolz, das Llama3Groq Tool mit den Modellen 8B und 70B bekannt zu geben. Dabei handelt es sich um eine vollständig optimierte Version des Open-Source-Tools von Llama3, das den ersten Platz in der BFCL erreicht hat und alle anderen Modelle, einschließlich proprietärer Modelle, übertrifft.“ Wie Claude Sonnet3.5, GPT-4Turbo, GPT-4o und Gemini1.5Pro.“
Synthetische Daten und ethische KI: ein neues Paradigma im Modelltraining
Die größere 70B-Parameterversion erreichte eine Gesamtgenauigkeit von 90,76 % bei BFCL, während das kleinere 8B-Modell 89,06 % erreichte und insgesamt den dritten Platz belegte. Diese Ergebnisse zeigen, dass Open-Source-Modelle bei bestimmten Aufgaben mit der Leistung von Closed-Source-Alternativen mithalten oder diese sogar übertreffen können.
Groq entwickelte die Modelle in Zusammenarbeit mit dem Forschungsunternehmen für künstliche Intelligenz Glaive und nutzte dabei die vollständige Feinabstimmung und direkte Präferenzoptimierung (DPO) auf dem Llama-3-Basismodell von Meta. Das Team betont, dass es für das Training nur ethisch generierte synthetische Daten verwendet und damit häufige Bedenken hinsichtlich Datenschutz und Überanpassung berücksichtigt.
Diese Modelle sind jetzt über die Groq-API und die Hugging Face-Plattform verfügbar. Diese Zugänglichkeit kann Innovationen in Bereichen beschleunigen, die eine komplexe Werkzeugnutzung und Funktionsaufrufe erfordern, wie etwa automatisierte Codierung, Datenanalyse und interaktive KI-Assistenten.
Groq hat außerdem eine öffentliche Demo zu Hugging Face Spaces gestartet, die es Benutzern ermöglicht, mit dem Modell zu interagieren und seine Werkzeugfunktionen aus erster Hand zu testen. Wie Gradio, das Hugging Face im Dezember 2021 erworben hat, werden viele der Demos von Hugging Face Spaces auf diese Weise erstellt. Die KI-Community hat begeistert reagiert und viele Forscher und Entwickler sind bestrebt, die Fähigkeiten dieser Modelle zu erkunden.
Höhepunkte:
⭐ Das von Groq veröffentlichte Open-Source-KI-Modell übertrifft die proprietären Modelle des Technologieriesen bei bestimmten Aufgaben
⭐ Durch die Verwendung synthetischer Daten für das Training stellt Groq häufige Datenschutz- und Überanpassungsprobleme bei der Entwicklung von KI-Modellen in Frage
⭐ Die Einführung von Open-Source-Modellen kann den Entwicklungspfad des KI-Bereichs verändern und eine breitere Zugänglichkeit von KI und die Entwicklung innovativer Ökosysteme fördern
Der Erfolg des Open-Source-Modells von Groq hat der Entwicklung auf dem Gebiet der künstlichen Intelligenz neue Dynamik verliehen und zeigt auch, dass Open-Source-Modelle in Zukunft eine immer wichtigere Rolle spielen werden. Die Anwendung synthetischer Daten liefert neue Ideen zur Lösung von Problemen wie Datenschutz und Modellverzerrung, die einer eingehenden Untersuchung und Referenz durch die Branche würdig sind. Wir freuen uns auf die Entstehung weiterer hervorragender Open-Source-Modelle in der Zukunft, um den kontinuierlichen Fortschritt der Technologie der künstlichen Intelligenz voranzutreiben.