Hbase distributed database v2.5.8
2.5.8
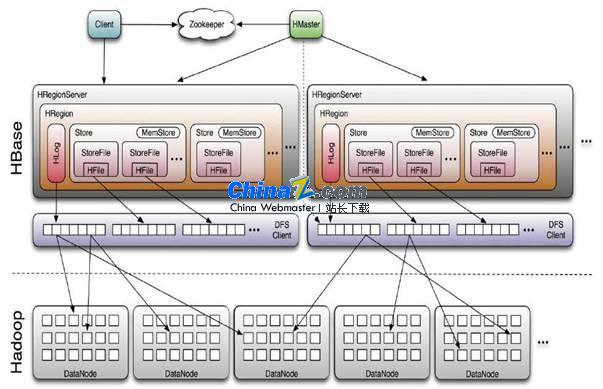
Hbase is Apache's NoSQL distributed scalable Hadoop database that scales out well. Data in Hbase is a column-oriented database where structured data is stored in key-value pairs. Hbase is written in Java. Hbase is inspired by Google Paper - "Big Table: A Distributed Storage System for Structured Data". Hbase is mainly used where very fast read and write access is required. In this post, I will show how to install Apache Hbase on Windows. Hbase can be used independently of Hadoop.
Linearly scalable.
Consistent reading and writing.
Automatic and configurable sharding of tables
Automatic failover support for region servers.
Integrate with Hadoop as source and target.
Easy-to-use Java-based API for client access.
Low-latency access to a single row among billions of records.
Quickly find larger tables.
Thrift gateway and REST-ful web services supporting XML, Protobuf and binary data encoding options
Extensible Jruby-based (JIRB) Shell
Supports exporting metrics to file or Ganglia via the Hadoop metrics subsystem; or via JMX