bitnet.cpp is the official inference framework for 1-bit LLMs (e.g., BitNet b1.58). It offers a suite of optimized kernels, that support fast and lossless inference of 1.58-bit models on CPU (with NPU and GPU support coming next).
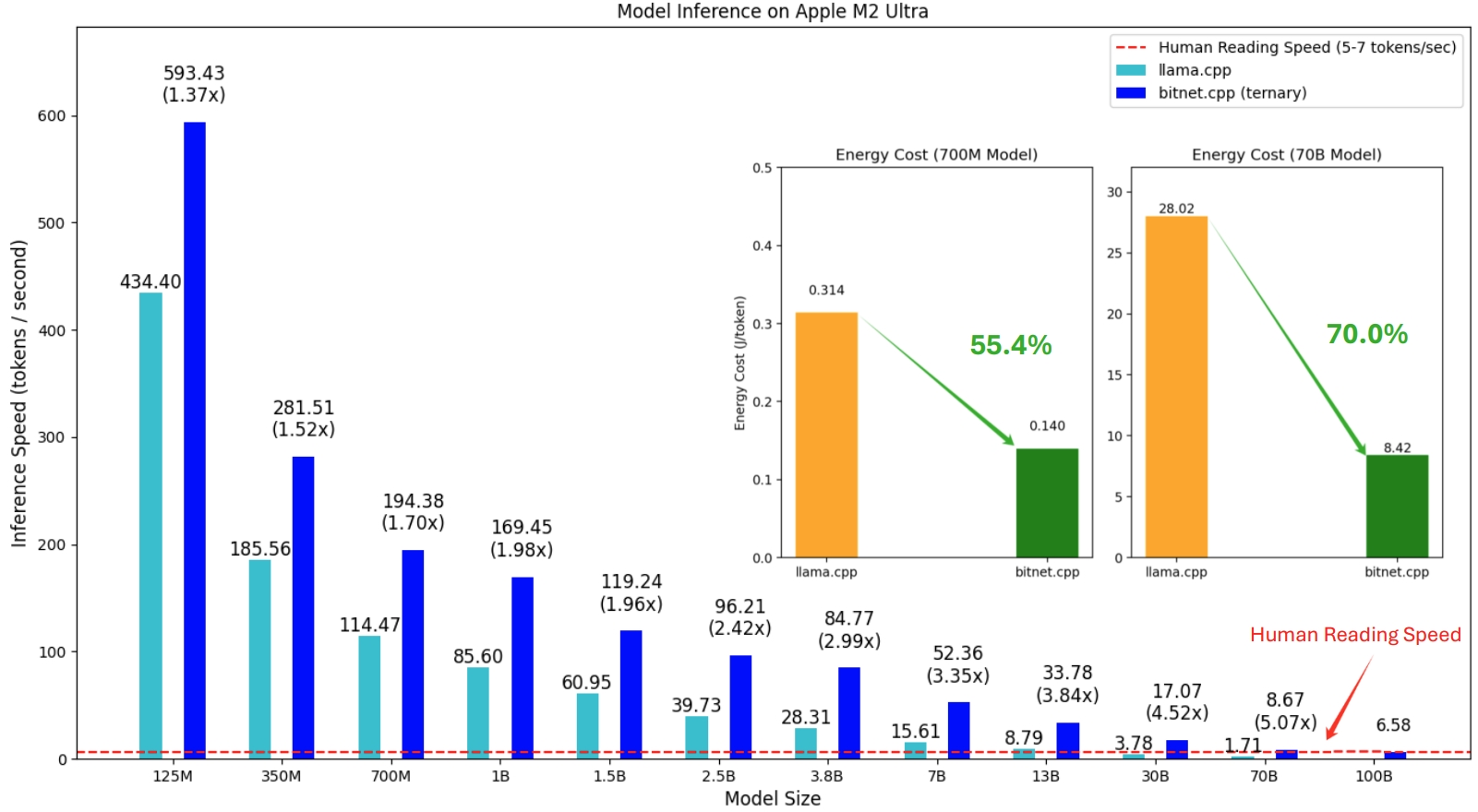
The first release of bitnet.cpp is to support inference on CPUs. bitnet.cpp achieves speedups of 1.37x to 5.07x on ARM CPUs, with larger models experiencing greater performance gains. Additionally, it reduces energy consumption by 55.4% to 70.0%, further boosting overall efficiency. On x86 CPUs, speedups range from 2.37x to 6.17x with energy reductions between 71.9% to 82.2%. Furthermore, bitnet.cpp can run a 100B BitNet b1.58 model on a single CPU, achieving speeds comparable to human reading (5-7 tokens per second), significantly enhancing the potential for running LLMs on local devices. Please refer to the technical report for more details.


The tested models are dummy setups used in a research context to demonstrate the inference performance of bitnet.cpp.
A demo of bitnet.cpp running a BitNet b1.58 3B model on Apple M2:
10/21/2024 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
10/17/2024 bitnet.cpp 1.0 released.
03/21/2024 The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ
02/27/2024 The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
10/17/2023 BitNet: Scaling 1-bit Transformers for Large Language Models
This project is based on the llama.cpp framework. We would like to thank all the authors for their contributions to the open-source community. Also, bitnet.cpp's kernels are built on top of the Lookup Table methodologies pioneered in T-MAC. For inference of general low-bit LLMs beyond ternary models, we recommend using T-MAC.
❗️We use existing 1-bit LLMs available on Hugging Face to demonstrate the inference capabilities of bitnet.cpp. These models are neither trained nor released by Microsoft. We hope the release of bitnet.cpp will inspire the development of 1-bit LLMs in large-scale settings in terms of model size and training tokens.
| Model | Parameters | CPU | Kernel | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-large | 0.7B | x86 | ✔ | ✘ | ✔ |
| ARM | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| ARM | ✘ | ✔ | ✘ | ||
| Llama3-8B-1.58-100B-tokens | 8.0B | x86 | ✔ | ✘ | ✔ |
| ARM | ✔ | ✔ | ✘ | ||
python>=3.9
cmake>=3.22
clang>=18
Desktop-development with C++
C++-CMake Tools for Windows
Git for Windows
C++-Clang Compiler for Windows
MS-Build Support for LLVM-Toolset (clang)
For Windows users, install Visual Studio 2022. In the installer, toggle on at least the following options(this also automatically installs the required additional tools like CMake):
For Debian/Ubuntu users, you can download with Automatic installation script
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
conda (highly recommend)
Important
If you are using Windows, please remember to always use a Developer Command Prompt / PowerShell for VS2022 for the following commands
Clone the repo
git clone --recursive https://github.com/microsoft/BitNet.gitcd BitNet
Install the dependencies
# (Recommended) Create a new conda environmentconda create -n bitnet-cpp python=3.9 conda activate bitnet-cpp pip install -r requirements.txt
Build the project
# Download the model from Hugging Face, convert it to quantized gguf format, and build the projectpython setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_s# Or you can manually download the model and run with local pathhuggingface-cli download HF1BitLLM/Llama3-8B-1.58-100B-tokens --local-dir models/Llama3-8B-1.58-100B-tokens python setup_env.py -md models/Llama3-8B-1.58-100B-tokens -q i2_s
usage: setup_env.py [-h] [--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}] [--model-dir MODEL_DIR] [--log-dir LOG_DIR] [--quant-type {i2_s,tl1}] [--quant-embd]
[--use-pretuned]
Setup the environment for running inference
optional arguments:
-h, --help show this help message and exit
--hf-repo {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}, -hr {1bitLLM/bitnet_b1_58-large,1bitLLM/bitnet_b1_58-3B,HF1BitLLM/Llama3-8B-1.58-100B-tokens}
Model used for inference
--model-dir MODEL_DIR, -md MODEL_DIR
Directory to save/load the model
--log-dir LOG_DIR, -ld LOG_DIR
Directory to save the logging info
--quant-type {i2_s,tl1}, -q {i2_s,tl1}
Quantization type
--quant-embd Quantize the embeddings to f16
--use-pretuned, -p Use the pretuned kernel parameters# Run inference with the quantized modelpython run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?nAnswer:" -n 6 -temp 0# Output:# Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?# Answer: Mary is in the garden.
usage: run_inference.py [-h] [-m MODEL] [-n N_PREDICT] -p PROMPT [-t THREADS] [-c CTX_SIZE] [-temp TEMPERATURE] Run inference optional arguments: -h, --help show this help message and exit -m MODEL, --model MODEL Path to model file -n N_PREDICT, --n-predict N_PREDICT Number of tokens to predict when generating text -p PROMPT, --prompt PROMPT Prompt to generate text from -t THREADS, --threads THREADS Number of threads to use -c CTX_SIZE, --ctx-size CTX_SIZE Size of the prompt context -temp TEMPERATURE, --temperature TEMPERATURE Temperature, a hyperparameter that controls the randomness of the generated text
We provide scripts to run the inference benchmark providing a model.
usage: e2e_benchmark.py -m MODEL [-n N_TOKEN] [-p N_PROMPT] [-t THREADS] Setup the environment for running the inference required arguments: -m MODEL, --model MODEL Path to the model file. optional arguments: -h, --help Show this help message and exit. -n N_TOKEN, --n-token N_TOKEN Number of generated tokens. -p N_PROMPT, --n-prompt N_PROMPT Prompt to generate text from. -t THREADS, --threads THREADS Number of threads to use.
Here's a brief explanation of each argument:
-m, --model: The path to the model file. This is a required argument that must be provided when running the script.
-n, --n-token: The number of tokens to generate during the inference. It is an optional argument with a default value of 128.
-p, --n-prompt: The number of prompt tokens to use for generating text. This is an optional argument with a default value of 512.
-t, --threads: The number of threads to use for running the inference. It is an optional argument with a default value of 2.
-h, --help: Show the help message and exit. Use this argument to display usage information.
For example:
python utils/e2e_benchmark.py -m /path/to/model -n 200 -p 256 -t 4
This command would run the inference benchmark using the model located at /path/to/model, generating 200 tokens from a 256 token prompt, utilizing 4 threads.
For the model layout that do not supported by any public model, we provide scripts to generate a dummy model with the given model layout, and run the benchmark on your machine:
python utils/generate-dummy-bitnet-model.py models/bitnet_b1_58-large --outfile models/dummy-bitnet-125m.tl1.gguf --outtype tl1 --model-size 125M# Run benchmark with the generated model, use -m to specify the model path, -p to specify the prompt processed, -n to specify the number of token to generatepython utils/e2e_benchmark.py -m models/dummy-bitnet-125m.tl1.gguf -p 512 -n 128