auto round
Intel®
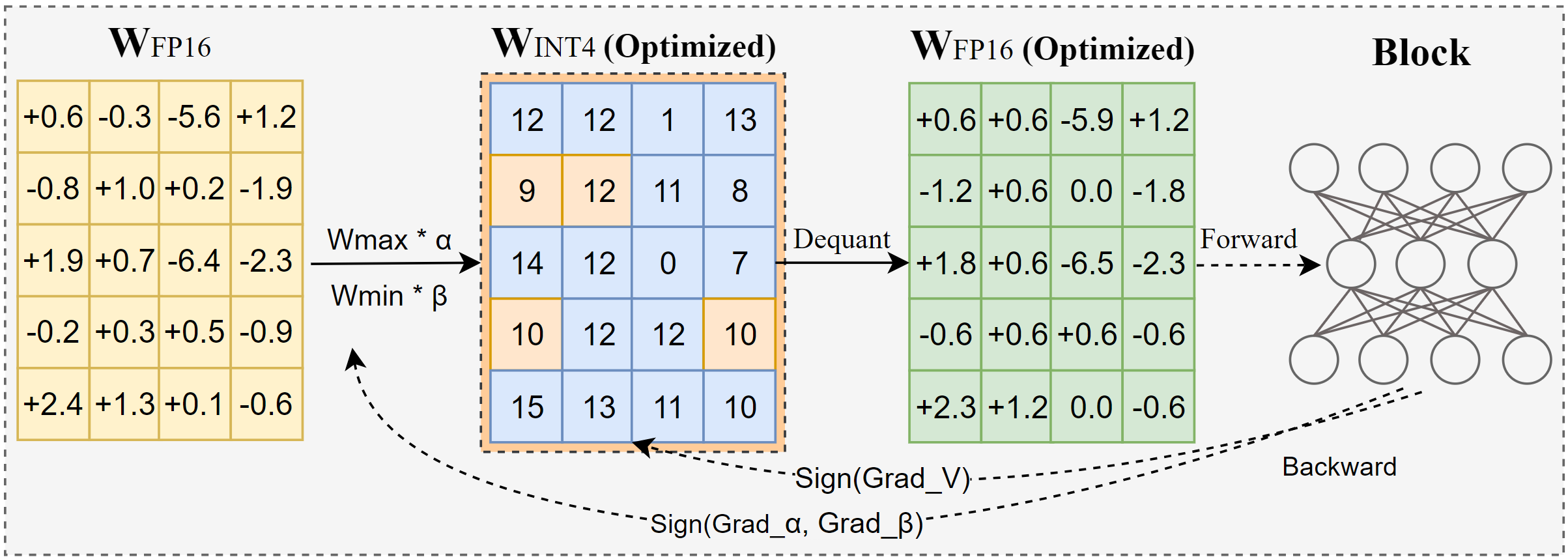
AutoRound is an advanced quantization algorithm for low-bits LLM inference. It's tailored for a wide range of models. AutoRound adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, which competes impressively against recent methods without introducing any additional inference overhead and keeping low tuning cost. The below image presents an overview of AutoRound. Check out our paper on arxiv for more details and visit low_bit_open_llm_leaderboard for more accuracy data and recipes across various models.


[2024/10] AutoRound has been integrated to torch/ao, check out their release note
[2024/10] Important update: We now support full-range symmetric quantization and have made it the default configuration. This configuration is typically better or comparable to asymmetric quantization and significantly outperforms other symmetric variants, especially at low bit-widths like 2-bit.
[2024/09] AutoRound format supports several LVM models, check out the examples Qwen2-Vl,Phi-3-vision, Llava
[2024/08] AutoRound format supports Intel Gaudi2 devices. Please refer to Intel/Qwen2-7B-int4-inc.
[2024/08] AutoRound introduces several experimental features, including fast tuning of norm/bias parameters (for 2-bit and W4A4), activation quantization, and the mx_fp data type.
pip install -vvv --no-build-isolation -e .
pip install auto-round
A user guide detailing the full list of supported arguments is provided by calling auto-round -h on the terminal.
Alternatively, you can use auto_round instead of auto-round. Set the format you want in format and
multiple formats exporting has been supported.
CUDA_VISIBLE_DEVICES=0 auto-round --model facebook/opt-125m --bits 4 --group_size 128 --format "auto_round,auto_gptq" --disable_eval --output_dir ./tmp_autoround
We provide two recipes for best accuracy and fast running speed with low memory. Details as below.
## best accuracy, 3X slower, low_gpu_mem_usage could save ~20G but ~30% slowerCUDA_VISIBLE_DEVICES=0 auto-round --model facebook/opt-125m --bits 4 --group_size 128 --nsamples 512 --iters 1000 --low_gpu_mem_usage --disable_eval
## fast and low memory, 2-3X speedup, slight accuracy drop at W4G128CUDA_VISIBLE_DEVICES=0 auto-round --model facebook/opt-125m --bits 4 --group_size 128 --nsamples 128 --iters 200 --seqlen 512 --batch_size 4 --disable_eval
AutoRound Format: This format is well-suited for CPU, HPU devices, 2 bits, as well as mixed-precision inference. [2,4] bits are supported. It also benefits from the Marlin kernel, which can boost inference performance notably. However, it has not yet gained widespread community adoption.
AutoGPTQ Format: This format is well-suited for symmetric quantization on CUDA devices and is widely adopted by the community, [2,3,4,8] bits are supported. It also benefits from the Marlin kernel, which can boost inference performance notably. However, the asymmetric kernel has issues that can cause considerable accuracy drops, particularly at 2-bit quantization and small models. Additionally, symmetric quantization tends to perform poorly at 2-bit precision.
AutoAWQ Format: This format is well-suited for asymmetric 4-bit quantization on CUDA devices and is widely adopted within the community, only 4-bits quantization is supported. It features specialized layer fusion tailored for Llama models.
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "facebook/opt-125m"model = AutoModelForCausalLM.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)from auto_round import AutoRoundbits, group_size, sym = 4, 128, Trueautoround = AutoRound(model, tokenizer, bits=bits, group_size=group_size, sym=sym)## the best accuracy, 3X slower, low_gpu_mem_usage could save ~20G but ~30% slower# autoround = AutoRound(model, tokenizer, nsamples=512, iters=1000, low_gpu_mem_usage=True, bits=bits, group_size=group_size, sym=sym)## fast and low memory, 2-3X speedup, slight accuracy drop at W4G128# autoround = AutoRound(model, tokenizer, nsamples=128, iters=200, seqlen=512, batch_size=4, bits=bits, group_size=group_size, sym=sym )autoround.quantize()output_dir = "./tmp_autoround"## format= 'auto_round'(default in version>0.3.0), 'auto_gptq', 'auto_awq'autoround.save_quantized(output_dir, format='auto_round', inplace=True)
Testing was conducted on the Nvidia A100 80G using the nightly version of PyTorch 2.6.0.dev20241029+cu124. Please note that data loading and packing costs have been excluded from the evaluation. We enable torch.compile for Torch 2.6, but not for 2.5 due to encountered issues.
To optimize GPU memory usage, in addition to activating low_gpu_mem_usage, you can set gradient_accumulate_steps=8and abatch_size=1, though this may increase tuning time.
The 3B and 14B models were evaluated on Qwen 2.5, the 8X7B model is Mixtral, while the remaining models utilized LLaMA 3.1.
| Torch version/Config W4G128 | 3B | 8B | 14B | 70B | 8X7B |
|---|---|---|---|---|---|
| 2.6 with torch compile | 7min 10GB | 12min 18GB | 23min 22GB | 120min 42GB | 28min 46GB |
| 2.6 with torch compile low_gpu_mem_usage=True | 12min 6GB | 19min 10GB | 33min 11GB | 140min 25GB | 38min 36GB |
| 2.6 with torch compile low_gpu_mem_usage=True gradient_accumulate_steps=8,bs=1 | 15min 3GB | 25min 6GB | 45min 7GB | 187min 19GB | 75min 36GB |
| 2.5 w/o torch compile | 8min 10GB | 16min 20GB | 30min 25GB | 140min 49GB | 50min 49GB |
Please run the quantization code first
CPU: auto_round version >0.3.1, pip install intel-extension-for-pytorch(much higher speed on Intel CPU) or pip install intel-extension-for-transformers,
HPU: docker image with Gaudi Software Stack is recommended. More details can be found in Gaudi Guide.
CUDA: no extra operations for sym quantization, for asym quantization, need to install auto-round from source
from transformers import AutoModelForCausalLM, AutoTokenizerfrom auto_round import AutoRoundConfigbackend = "auto" ##cpu, hpu, cuda, cuda:marlin(supported in auto_round>0.3.1 and 'pip install -v gptqmodel --no-build-isolation')quantization_config = AutoRoundConfig(backend=backend)quantized_model_path = "./tmp_autoround"model = AutoModelForCausalLM.from_pretrained(quantized_model_path, device_map=backend.split(':')[0], quantization_config=quantization_config)tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)text = "There is a girl who likes adventure,"inputs = tokenizer(text, return_tensors="pt").to(model.device)print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]))auto-round --model saved_quantized_model --eval --task lambada_openai --eval_bs 1
from transformers import AutoModelForCausalLM, AutoTokenizerquantized_model_path = "./tmp_autoround"model = AutoModelForCausalLM.from_pretrained(quantized_model_path, device_map="auto")tokenizer = AutoTokenizer.from_pretrained(quantized_model_path)text = "There is a girl who likes adventure,"inputs = tokenizer(text, return_tensors="pt").to(model.device)print(tokenizer.decode(model.generate(**inputs, max_new_tokens=50)[0]))
AutoRound supports basically all the major large language models.
Please note that an asterisk (*) indicates third-party quantized models, which may lack accuracy data and use a different recipe. We greatly appreciate their efforts and encourage more users to share their models, as we cannot release most of the models ourselves.
| Model | Supported |
|---|---|
| meta-llama/Meta-Llama-3.1-70B-Instruct | recipe |
| meta-llama/Meta-Llama-3.1-8B-Instruct | model-kaitchup-autogptq-int4*, model-kaitchup-autogptq-sym-int4*, recipe |
| meta-llama/Meta-Llama-3.1-8B | model-kaitchup-autogptq-sym-int4* |
| Qwen/Qwen-VL | accuracy, recipe |
| Qwen/Qwen2-7B | model-autoround-sym-int4, model-autogptq-sym-int4 |
| Qwen/Qwen2-57B-A14B-Instruct | model-autoround-sym-int4,model-autogptq-sym-int4 |
| 01-ai/Yi-1.5-9B | model-LnL-AI-autogptq-int4* |
| 01-ai/Yi-1.5-9B-Chat | model-LnL-AI-autogptq-int4* |
| Intel/neural-chat-7b-v3-3 | model-autogptq-int4 |
| Intel/neural-chat-7b-v3-1 | model-autogptq-int4 |
| TinyLlama-1.1B-intermediate | model-LnL-AI-autogptq-int4* |
| mistralai/Mistral-7B-v0.1 | model-autogptq-lmhead-int4, model-autogptq-int4 |
| google/gemma-2b | model-autogptq-int4 |
| tiiuae/falcon-7b | model-autogptq-int4-G64 |
| sapienzanlp/modello-italia-9b | model-fbaldassarri-autogptq-int4* |
| microsoft/phi-2 | model-autoround-sym-int4 model-autogptq-sym-int4 |
| microsoft/Phi-3.5-mini-instruct | model-kaitchup-autogptq-sym-int4* |
| microsoft/Phi-3-vision-128k-instruct | recipe |
| mistralai/Mistral-7B-Instruct-v0.2 | accuracy, recipe, example |
| mistralai/Mixtral-8x7B-Instruct-v0.1 | accuracy, recipe, example |
| mistralai/Mixtral-8x7B-v0.1 | accuracy, recipe, example |
| meta-llama/Meta-Llama-3-8B-Instruct | accuracy, recipe, example |
| google/gemma-7b | accuracy, recipe, example |
| meta-llama/Llama-2-7b-chat-hf | accuracy, recipe, example |
| Qwen/Qwen1.5-7B-Chat | accuracy, sym recipe, asym recipe , example |
| baichuan-inc/Baichuan2-7B-Chat | accuracy, recipe, example |
| 01-ai/Yi-6B-Chat | accuracy, recipe, example |
| facebook/opt-2.7b | accuracy, recipe, example |
| bigscience/bloom-3b | accuracy, recipe, example |
| EleutherAI/gpt-j-6b | accuracy, recipe, example |
AutoRound has been integrated into multiple repositories.
Intel Neural Compressor
ModelCloud/GPTQModel
pytorch/ao
If you find AutoRound useful for your research, please cite our paper:
@article{cheng2023optimize,
title={Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs},
author={Cheng, Wenhua and Zhang, Weiwei and Shen, Haihao and Cai, Yiyang and He, Xin and Lv, Kaokao and Liu, Yi},
journal={arXiv preprint arXiv:2309.05516},
year={2023}
}