efficient language detector
3.0.0
Efficient language detector (Nito-ELD or ELD) is a fast and accurate natural language detection software, written 100% in PHP, with a speed comparable to fast C++ compiled detectors, and accuracy within the range of the best detectors to date.
It has no dependencies, easy installation, all it's needed is PHP with the mb extension.
ELD is also available (outdated versions) in Javascript and Python.
Installation
How to use
Benchmarks
Databases
Testing
Languages
Changes from ELD v2 to v3:
detect()->language now returns string
'und'for undetermined instead ofNULLDatabases are not compatible, and bigger, medium v2 ≈ small v3
dynamicLangSubset() function is removed
Function cleanText() is now named enableTextCleanup()
$ composer require nitotm/efficient-language-detector
--prefer-dist will omit tests/, misc/ & benchmark/, or use --prefer-source to include everything
Install nitotm/efficient-language-detector:dev-main to try the last unstable changes
Alternatively, download / clone the files can work just fine.
(Only small DB install under construction)
It is recommended to use OPcache, specially for the larger databases to reduce load times.
We need to set opcache.interned_strings_buffer, opcache.memory_consumption high enough for each database
Recommended value in parentheses. Check Databases for more info.
| php.ini setting | Small | Medium | Large | Extralarge |
|---|---|---|---|---|
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
detect() expects a UTF-8 string and returns an object with a language property, containing an ISO 639-1 code (or other selected format), or 'und' for undetermined language.
// require_once 'manual_loader.php'; To load ELD without autoloader. Update path.use NitotmEld{LanguageDetector, EldDataFile, EldFormat};// LanguageDetector(databaseFile: ?string, outputFormat: ?string)$eld = new LanguageDetector(EldDataFile::SMALL, EldFormat::ISO639_1);// Database files: 'small', 'medium', 'large', 'extralarge'. Check memory requirements// Formats: 'ISO639_1', 'ISO639_2T', 'ISO639_1_BCP47', 'ISO639_2T_BCP47' and 'FULL_TEXT'// Constants are not mandatory, LanguageDetector('small', 'ISO639_1'); will also work$eld->detect('Hola, cómo te llamas?');// object( language => string, scores() => array, isReliable() => bool )// ( language => 'es', scores() => ['es' => 0.25, 'nl' => 0.05], isReliable() => true )$eld->detect('Hola, cómo te llamas?')->language;// 'es' Calling langSubset() once, will set the subset. The first call takes longer as it creates a new database, if saving the database file (default), it will be loaded next time we make the same subset.
To use a subset without additional overhead, the proper way is to instantiate the detector with the file saved and returned by langSubset(). Check available Languages below.
// It always accepts ISO 639-1 codes, as well as the selected output format if different.// langSubset(languages: [], save: true, encode: true); Will return subset file name if saved$eld->langSubset(['en', 'es', 'fr', 'it', 'nl', 'de']);// Object ( success => bool, languages => ?array, error => ?string, file => ?string )// ( success => true, languages => ['en', 'es'...], error => NULL, file => 'small_6_mfss...' )// to remove the subset$eld->langSubset();// The best and fastest way to use a subset, is to load it just like a default database$eld_subset = new NitotmEldLanguageDetector('small_6_mfss5z1t');// if enableTextCleanup(True), detect() removes Urls, .com domains, emails, alphanumerical...// Not recommended, as urls & domains contain hints of a language, which might help accuracy$eld->enableTextCleanup(true); // Default is false// If needed, we can get info of the ELD instance: languages, database type, etc.$eld->info();
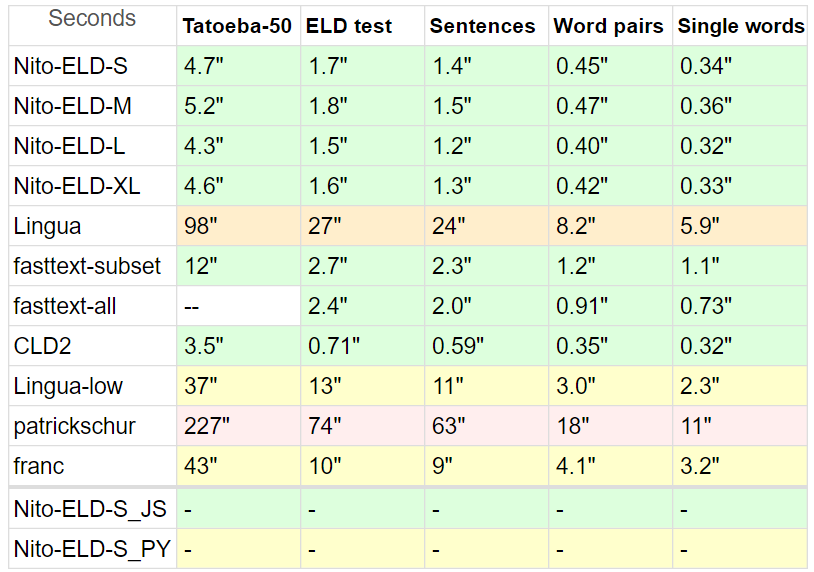
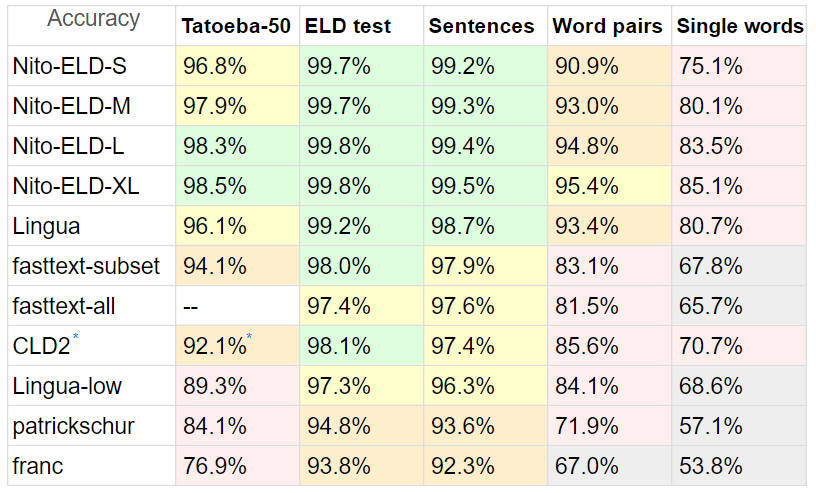
I compared ELD with a different variety of detectors, as there are not many in PHP.
| URL | Version | Language |
|---|---|---|
| https://github.com/nitotm/efficient-language-detector/ | 3.0.0 | PHP |
| https://github.com/pemistahl/lingua-py | 2.0.2 | Python |
| https://github.com/facebookresearch/fastText | 0.9.2 | C++ |
| https://github.com/CLD2Owners/cld2 | Aug 21, 2015 | C++ |
| https://github.com/patrickschur/language-detection | 5.3.0 | PHP |
| https://github.com/wooorm/franc | 7.2.0 | Javascript |
Benchmarks:
Tatoeba: 20MB, short sentences from Tatoeba, 50 languages supported by all contenders, up to 10k lines each.
For Tatoeba, I limited all detectors to the 50 languages subset, making the comparison as fair as possible.
Also, Tatoeba is not part of ELD training dataset (nor tuning), but it is for fasttext
ELD Test: 10MB, sentences from the 60 languages supported by ELD, 1000 lines each. Extracted from the 60GB of ELD training data.
Sentences: 8MB, sentences from Lingua benchmark, minus unsupported languages and Yoruba which had broken characters.
Word pairs 1.5MB, and Single words 870KB, also from Lingua, same 53 languages.


Lingua participates with 54 languages, Franc with 58, patrickschur with 54.
fasttext does not have a built-in subset option, so to show its accuracy and speed potential I made two benchmarks, fasttext-all not being limited by any subset at any test
* Google's CLD2 also lacks subset option, and it's difficult to make a subset even with its option bestEffort = True, as usually returns only one language, so it has a comparative disadvantage.
Time is normalized: (total lines * time) / processed lines
| Small | Medium | Large | Extralarge | |
|---|---|---|---|---|
| Pros | Lowest memory | Equilibrated | Fastest | Most accurate |
| Cons | Least accurate | Slowest (but fast) | High memory | Highest memory |
| File size | 3 MB | 10 MB | 32 MB | 71 MB |
| Memory usage | 76 MB | 280 MB | 977 MB | 2083 MB |
| Memory usage Cached | 0.4 MB + OP | 0.4 MB + OP | 0.4 MB + OP | 0.4 MB + OP |
| OPcache used memory | 21 MB | 69 MB | 244 MB | 539 MB |
| OPcache used interned | 4 MB | 10 MB | 45 MB | 98 MB |
| Load time Uncached | 0.14 sec | 0.5 sec | 1.5 sec | 3.4 sec |
| Load time Cached | 0.0002 sec | 0.0002 sec | 0.0002 sec | 0.0002 sec |
| Settings (Recommended) | ||||
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned...* | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
* I recommend using more than enough interned_strings_buffer as buffers overflow error might delay server response.
To use all databases opcache.interned_strings_buffer should be a minimum of 160MB (170MB).
When choosing the amount of memory keep in mind opcache.memory_consumption includes opcache.interned_strings_buffer.
If OPcache memory is 230MB, interned_strings is 32MB, and medium DB is 69MB cached, we have a total of (230 -32 -69) = 129MB of OPcache for everything else.
Also, if you are going to use a subset of languages in addition to the main database, or multiple subsets, increase opcache.memory accordingly if you want them to be loaded instantly.
To cache all default databases comfortably you would want to set it at 1200MB.
Default composer install might not include these files. Use --prefer-source to include them.
For dev environment with composer "autoload-dev" (root only), the following will execute the tests
new NitotmEldTestsTestsAutoload();
Or, you can also run the tests executing the following file:
$ php efficient-language-detector/tests/tests.php # Update path
To run the accuracy benchmarks run the benchmark/bench.php file.
These are the ISO 639-1 codes that include the 60 languages. Plus 'und' for undetermined
It is the default ELD language format. outputFormat: 'ISO639_1'
am, ar, az, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, is, it, ja, ka, kn, ko, ku, lo, lt, lv, ml, mr, ms, nl, no, or, pa, pl, pt, ro, ru, sk, sl, sq, sr, sv, ta, te, th, tl, tr, uk, ur, vi, yo, zh
These are the 60 supported languages for Nito-ELD. outputFormat: 'FULL_TEXT'
Amharic, Arabic, Azerbaijani (Latin), Belarusian, Bulgarian, Bengali, Catalan, Czech, Danish, German, Greek, English, Spanish, Estonian, Basque, Persian, Finnish, French, Gujarati, Hebrew, Hindi, Croatian, Hungarian, Armenian, Icelandic, Italian, Japanese, Georgian, Kannada, Korean, Kurdish (Arabic), Lao, Lithuanian, Latvian, Malayalam, Marathi, Malay (Latin), Dutch, Norwegian, Oriya, Punjabi, Polish, Portuguese, Romanian, Russian, Slovak, Slovene, Albanian, Serbian (Cyrillic), Swedish, Tamil, Telugu, Thai, Tagalog, Turkish, Ukrainian, Urdu, Vietnamese, Yoruba, Chinese
ISO 639-1 codes with IETF BCP 47 script name tag. outputFormat: 'ISO639_1_BCP47'
am, ar, az-Latn, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, is, it, ja, ka, kn, ko, ku-Arab, lo, lt, lv, ml, mr, ms-Latn, nl, no, or, pa, pl, pt, ro, ru, sk, sl, sq, sr-Cyrl, sv, ta, te, th, tl, tr, uk, ur, vi, yo, zh
ISO 639-2/T codes (which are also valid 639-3) outputFormat: 'ISO639_2T'. Also available with BCP 47 ISO639_2T_BCP47
amh, ara, aze, bel, bul, ben, cat, ces, dan, deu, ell, eng, spa, est, eus, fas, fin, fra, guj, heb, hin, hrv, hun, hye, isl, ita, jpn, kat, kan, kor, kur, lao, lit, lav, mal, mar, msa, nld, nor, ori, pan, pol, por, ron, rus, slk, slv, sqi, srp, swe, tam, tel, tha, tgl, tur, ukr, urd, vie, yor, zho
If you wish to donate for open source improvements, hire me for private modifications, request alternative dataset training, or contact me, please use the following link: https://linktr.ee/nitotm