DeepKE
DeepKE 2.2.7
English | 简体中文
A Deep Learning Based Knowledge Extraction Toolkit
for Knowledge Graph Construction
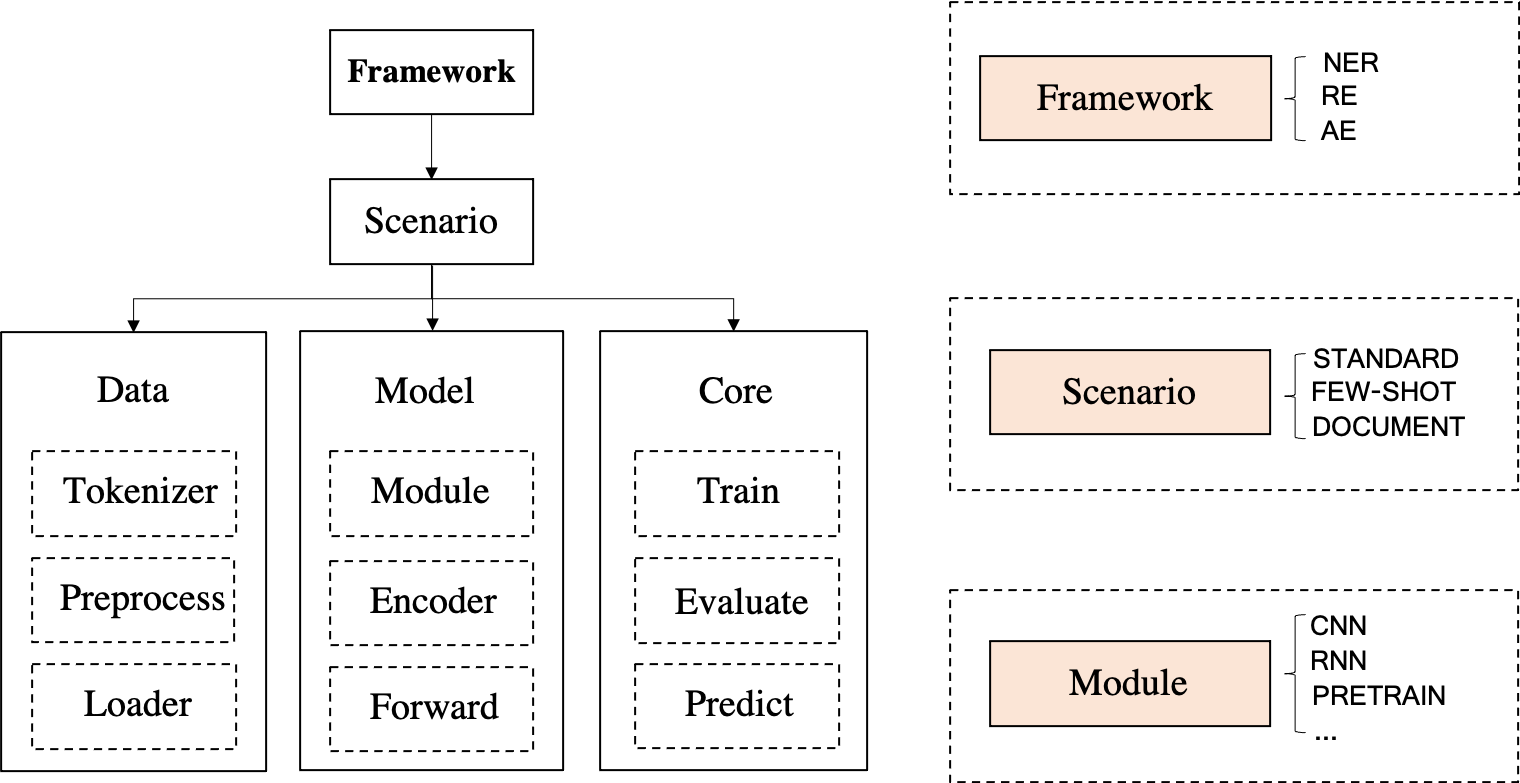
DeepKE is a knowledge extraction toolkit for knowledge graph construction supporting cnSchema,low-resource, document-level and multimodal scenarios for entity, relation and attribute extraction. We provide documents, online demo, paper, slides and poster for beginners.
\ in file paths;wisemodel or modescape.If you encounter any issues during the installation of DeepKE and DeepKE-LLM, please check Tips or promptly submit an issue, and we will assist you with resolving the problem!
April, 2024 We release a new bilingual (Chinese and English) schema-based information extraction model called OneKE based on Chinese-Alpaca-2-13B.Feb, 2024 We release a large-scale (0.32B tokens) high-quality bilingual (Chinese and English) Information Extraction (IE) instruction dataset named IEPile, along with two models trained with IEPile, baichuan2-13b-iepile-lora and llama2-13b-iepile-lora.Sep 2023 a bilingual Chinese English Information Extraction (IE) instruction dataset called InstructIE was released for the Instruction based Knowledge Graph Construction Task (Instruction based KGC), as detailed in here.June, 2023 We update DeepKE-LLM to support knowledge extraction with KnowLM, ChatGLM, LLaMA-series, GPT-series etc.Apr, 2023 We have added new models, including CP-NER(IJCAI'23), ASP(EMNLP'22), PRGC(ACL'21), PURE(NAACL'21), provided event extraction capabilities (Chinese and English), and offered compatibility with higher versions of Python packages (e.g., Transformers).Feb, 2023 We have supported using LLM (GPT-3) with in-context learning (based on EasyInstruct) & data generation, added a NER model W2NER(AAAI'22).Nov, 2022 Add data annotation instructions for entity recognition and relation extraction, automatic labelling of weakly supervised data (entity extraction and relation extraction), and optimize multi-GPU training.
Sept, 2022 The paper DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population has been accepted by the EMNLP 2022 System Demonstration Track.
Aug, 2022 We have added data augmentation (Chinese, English) support for low-resource relation extraction.
June, 2022 We have added multimodal support for entity and relation extraction.
May, 2022 We have released DeepKE-cnschema with off-the-shelf knowledge extraction models.
Jan, 2022 We have released a paper DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population
Dec, 2021 We have added dockerfile to create the enviroment automatically.
Nov, 2021 The demo of DeepKE, supporting real-time extration without deploying and training, has been released.
The documentation of DeepKE, containing the details of DeepKE such as source codes and datasets, has been released.
Oct, 2021 pip install deepke
The codes of deepke-v2.0 have been released.
Aug, 2019 The codes of deepke-v1.0 have been released.
Aug, 2018 The project DeepKE startup and codes of deepke-v0.1 have been released.
There is a demonstration of prediction. The GIF file is created by Terminalizer. Get the code.
In the era of large models, DeepKE-LLM utilizes a completely new environment dependency.
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
Please note that the requirements.txt file is located in the example/llm folder.
pip install deepke. Step1 Download the basic code
git clone --depth 1 https://github.com/zjunlp/DeepKE.gitStep2 Create a virtual environment using Anaconda and enter it.
conda create -n deepke python=3.8
conda activate deepkeInstall DeepKE with source code
pip install -r requirements.txt
python setup.py install
python setup.py developInstall DeepKE with pip (NOT recommended!)
pip install deepkeStep3 Enter the task directory
cd DeepKE/example/re/standardStep4 Download the dataset, or follow the annotation instructions to obtain data
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzMany types of data formats are supported,and details are in each part.
Step5 Training (Parameters for training can be changed in the conf folder)
We support visual parameter tuning by using wandb.
python run.pyStep6 Prediction (Parameters for prediction can be changed in the conf folder)
Modify the path of the trained model in predict.yaml.The absolute path of the model needs to be used,such as xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth.
python predict.pyStep1 Install the Docker client
Install Docker and start the Docker service.
Step2 Pull the docker image and run the container
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bashThe remaining steps are the same as Step 3 and onwards in Manual Environment Configuration.
python == 3.8
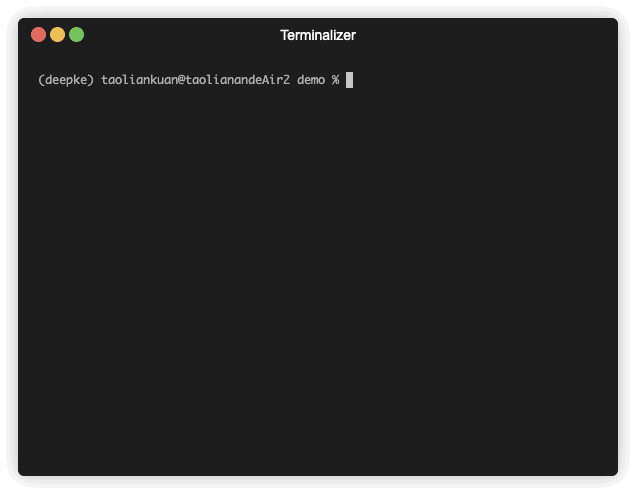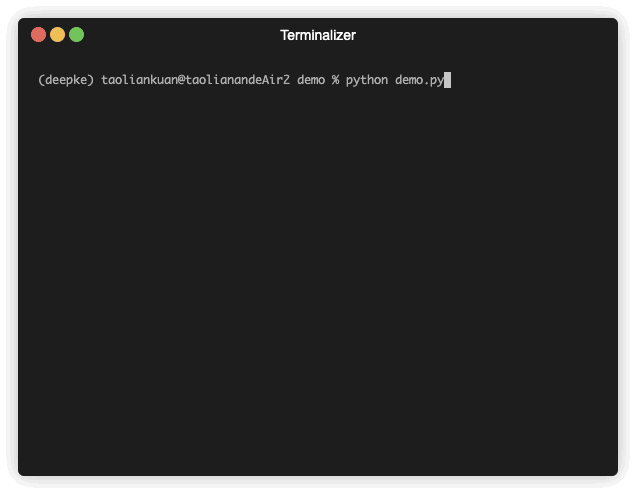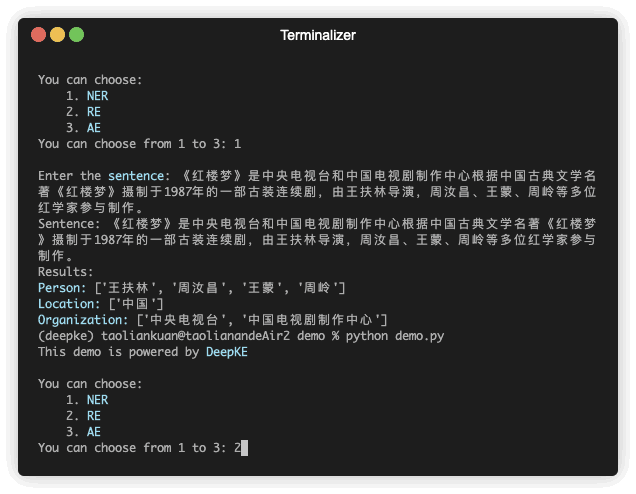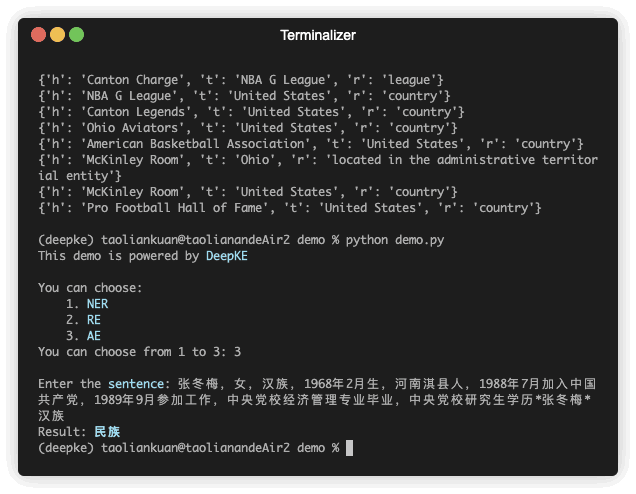
Named entity recognition seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, organizations, etc.
The data is stored in .txt files. Some instances as following (Users can label data based on the tools Doccano, MarkTool, or they can use the Weak Supervision with DeepKE to obtain data automatically):
| Sentence | Person | Location | Organization |
|---|---|---|---|
| 本报北京9月4日讯记者杨涌报道:部分省区人民日报宣传发行工作座谈会9月3日在4日在京举行。 | 杨涌 | 北京 | 人民日报 |
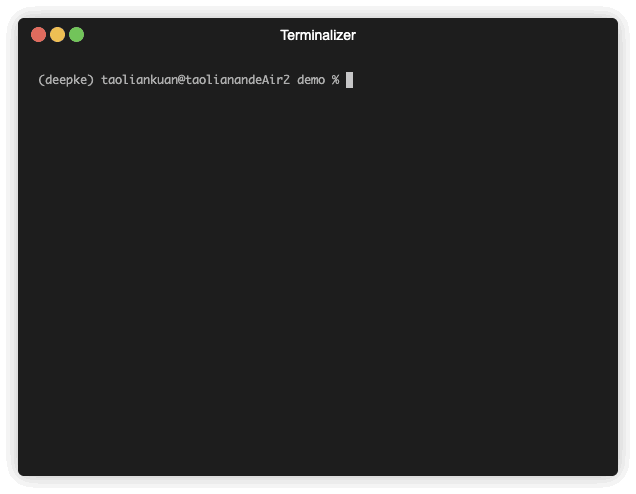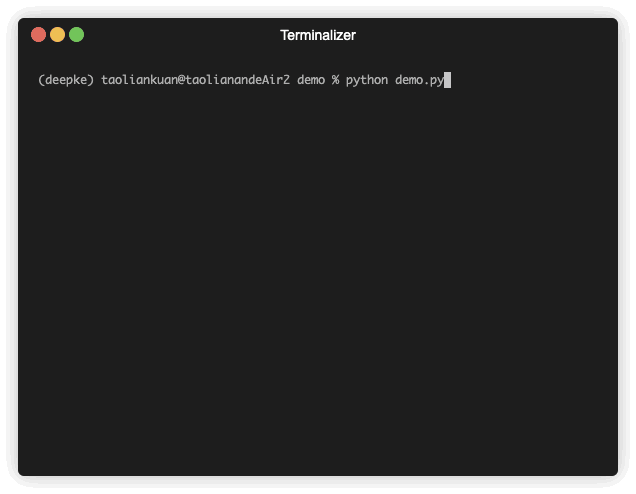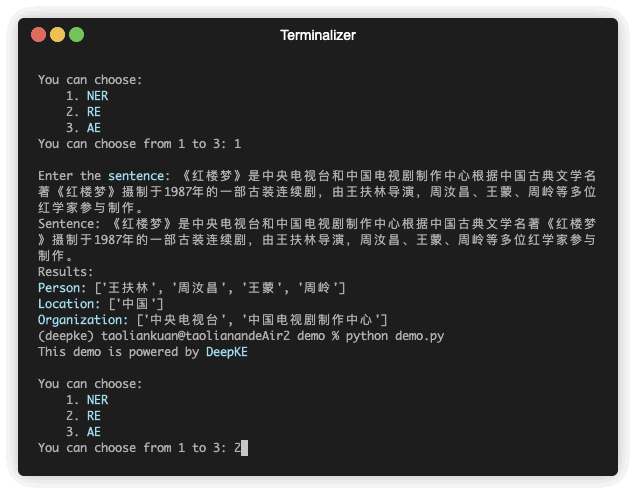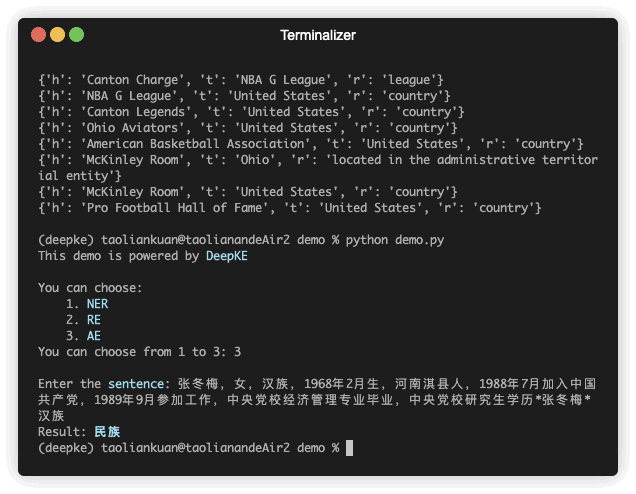
| 《红楼梦》由王扶林导演,周汝昌、王蒙、周岭等多位专家参与制作。 | 王扶林,周汝昌,王蒙,周岭 | ||
| 秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一。 | 秦始皇 | 陕西省,西安市 |
Read the detailed process in specific README
STANDARD (Fully Supervised)
We support LLM and provide the off-the-shelf model, DeepKE-cnSchema-NER, which will extract entities in cnSchema without training.
Step1 Enter DeepKE/example/ner/standard. Download the dataset.
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gzStep2 Training
The dataset and parameters can be customized in the data folder and conf folder respectively.
python run.pyStep3 Prediction
python predict.pyFEW-SHOT
Step1 Enter DeepKE/example/ner/few-shot. Download the dataset.
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gzStep2 Training in the low-resouce setting
The directory where the model is loaded and saved and the configuration parameters can be cusomized in the conf folder.
python run.py +train=few_shotUsers can modify load_path in conf/train/few_shot.yaml to use existing loaded model.
Step3 Add - predict to conf/config.yaml, modify loda_path as the model path and write_path as the path where the predicted results are saved in conf/predict.yaml, and then run python predict.py
python predict.pyMULTIMODAL
Step1 Enter DeepKE/example/ner/multimodal. Download the dataset.
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzWe use RCNN detected objects and visual grounding objects from original images as visual local information, where RCNN via faster_rcnn and visual grounding via onestage_grounding.
Step2 Training in the multimodal setting
data folder and conf folder respectively.load_path in conf/train.yamlas the path where the model trained last time was saved. And the path saving logs generated in training can be customized by log_dir.python run.pyStep3 Prediction
python predict.pyRelationship extraction is the task of extracting semantic relations between entities from a unstructured text.
The data is stored in .csv files. Some instances as following (Users can label data based on the tools Doccano, MarkTool, or they can use the Weak Supervision with DeepKE to obtain data automatically):
| Sentence | Relation | Head | Head_offset | Tail | Tail_offset |
|---|---|---|---|---|---|
| 《岳父也是爹》是王军执导的电视剧,由马恩然、范明主演。 | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》是在纵横中文网连载的一部小说,作者是龙马。 | 连载网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 提起杭州的美景,西湖总是第一个映入脑海的词语。 | 所在城市 | 西湖 | 8 | 杭州 | 2 |
!NOTE: If there are multiple entity types for one relation, entity types can be prefixed with the relation as inputs.
Read the detailed process in specific README
STANDARD (Fully Supervised)
We support LLM and provide the off-the-shelf model, DeepKE-cnSchema-RE, which will extract relations in cnSchema without training.
Step1 Enter the DeepKE/example/re/standard folder. Download the dataset.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzStep2 Training
The dataset and parameters can be customized in the data folder and conf folder respectively.
python run.pyStep3 Prediction
python predict.pyFEW-SHOT
Step1 Enter DeepKE/example/re/few-shot. Download the dataset.
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gzStep 2 Training
data folder and conf folder respectively.train_from_saved_model in conf/train.yamlas the path where the model trained last time was saved. And the path saving logs generated in training can be customized by log_dir.python run.pyStep3 Prediction
python predict.pyDOCUMENT
Step1 Enter DeepKE/example/re/document. Download the dataset.
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gzStep2 Training
data folder and conf folder respectively.train_from_saved_model in conf/train.yamlas the path where the model trained last time was saved. And the path saving logs generated in training can be customized by log_dir.python run.pyStep3 Prediction
python predict.pyMULTIMODAL
Step1 Enter DeepKE/example/re/multimodal. Download the dataset.
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzWe use RCNN detected objects and visual grounding objects from original images as visual local information, where RCNN via faster_rcnn and visual grounding via onestage_grounding.
Step2 Training
data folder and conf folder respectively.load_path in conf/train.yamlas the path where the model trained last time was saved. And the path saving logs generated in training can be customized by log_dir.python run.pyStep3 Prediction
python predict.pyAttribute extraction is to extract attributes for entities in a unstructed text.
The data is stored in .csv files. Some instances as following:
| Sentence | Att | Ent | Ent_offset | Val | Val_offset |
|---|---|---|---|---|---|
| 张冬梅,女,汉族,1968年2月生,河南淇县人 | 民族 | 张冬梅 | 0 | 汉族 | 6 |
| 诸葛亮,字孔明,三国时期杰出的军事家、文学家、发明家。 | 朝代 | 诸葛亮 | 0 | 三国时期 | 8 |
| 2014年10月1日许鞍华执导的电影《黄金时代》上映 | 上映时间 | 黄金时代 | 19 | 2014年10月1日 | 0 |
Read the detailed process in specific README
STANDARD (Fully Supervised)
Step1 Enter the DeepKE/example/ae/standard folder. Download the dataset.
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gzStep2 Training
The dataset and parameters can be customized in the data folder and conf folder respectively.
python run.pyStep3 Prediction
python predict.py.tsv files, some instances are as follows:| Sentence | Event type | Trigger | Role | Argument | |
|---|---|---|---|---|---|
| 据《欧洲时报》报道,当地时间27日,法国巴黎卢浮宫博物馆员工因不满工作条件恶化而罢工,导致该博物馆也因此闭门谢客一天。 | 组织行为-罢工 | 罢工 | 罢工人员 | 法国巴黎卢浮宫博物馆员工 | |
| 时间 | 当地时间27日 | ||||
| 所属组织 | 法国巴黎卢浮宫博物馆 | ||||
| 中国外运2019年上半年归母净利润增长17%:收购了少数股东股权 | 财经/交易-出售/收购 | 收购 | 出售方 | 少数股东 | |
| 收购方 | 中国外运 | ||||
| 交易物 | 股权 | ||||
| 美国亚特兰大航展13日发生一起表演机坠机事故,飞行员弹射出舱并安全着陆,事故没有造成人员伤亡。 | 灾害/意外-坠机 | 坠机 | 时间 | 13日 | |
| 地点 | 美国亚特兰 | ||||
Read the detailed process in specific README
STANDARD(Fully Supervised)
Step1 Enter the DeepKE/example/ee/standard folder. Download the dataset.
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipStep 2 Training
The dataset and parameters can be customized in the data folder and conf folder respectively.
python run.pyStep 3 Prediction
python predict.py1.Using nearest mirror, THU in China, will speed up the installation of Anaconda; aliyun in China, will speed up pip install XXX.
2.When encountering ModuleNotFoundError: No module named 'past',run pip install future .
3.It's slow to install the pretrained language models online. Recommend download pretrained models before use and save them in the pretrained folder. Read README.md in every task directory to check the specific requirement for saving pretrained models.
4.The old version of DeepKE is in the deepke-v1.0 branch. Users can change the branch to use the old version. The old version has been totally transfered to the standard relation extraction (example/re/standard).
5.If you want to modify the source code, it's recommended to install DeepKE with source codes. If not, the modification will not work. See issue
6.More related low-resource knowledge extraction works can be found in Knowledge Extraction in Low-Resource Scenarios: Survey and Perspective.
7.Make sure the exact versions of requirements in requirements.txt.
In next version, we plan to release a stronger LLM for KE.
Meanwhile, we will offer long-term maintenance to fix bugs, solve issues and meet new requests. So if you have any problems, please put issues to us.
Data-Efficient Knowledge Graph Construction, 高效知识图谱构建 (Tutorial on CCKS 2022) [slides]
Efficient and Robust Knowledge Graph Construction (Tutorial on AACL-IJCNLP 2022) [slides]
PromptKG Family: a Gallery of Prompt Learning & KG-related Research Works, Toolkits, and Paper-list [Resources]
Knowledge Extraction in Low-Resource Scenarios: Survey and Perspective [Survey][Paper-list]
Doccano、MarkTool、LabelStudio: Data Annotation Toolkits
LambdaKG: A library and benchmark for PLM-based KG embeddings
EasyInstruct: An easy-to-use framework to instruct Large Language Models
Reading Materials:
Data-Efficient Knowledge Graph Construction, 高效知识图谱构建 (Tutorial on CCKS 2022) [slides]
Efficient and Robust Knowledge Graph Construction (Tutorial on AACL-IJCNLP 2022) [slides]
PromptKG Family: a Gallery of Prompt Learning & KG-related Research Works, Toolkits, and Paper-list [Resources]
Knowledge Extraction in Low-Resource Scenarios: Survey and Perspective [Survey][Paper-list]
Related Toolkit:
Doccano、MarkTool、LabelStudio: Data Annotation Toolkits
LambdaKG: A library and benchmark for PLM-based KG embeddings
EasyInstruct: An easy-to-use framework to instruct Large Language Models
Please cite our paper if you use DeepKE in your work
@inproceedings{EMNLP2022_Demo_DeepKE,
author = {Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li},
editor = {Wanxiang Che and
Ekaterina Shutova},
title = {DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population},
booktitle = {{EMNLP} (Demos)},
pages = {98--108},
publisher = {Association for Computational Linguistics},
year = {2022},
url = {https://aclanthology.org/2022.emnlp-demos.10}
}Ningyu Zhang, Haofen Wang, Fei Huang, Feiyu Xiong, Liankuan Tao, Xin Xu, Honghao Gui, Zhenru Zhang, Chuanqi Tan, Qiang Chen, Xiaohan Wang, Zekun Xi, Xinrong Li, Haiyang Yu, Hongbin Ye, Shuofei Qiao, Peng Wang, Yuqi Zhu, Xin Xie, Xiang Chen, Zhoubo Li, Lei Li, Xiaozhuan Liang, Yunzhi Yao, Jing Chen, Yuqi Zhu, Shumin Deng, Wen Zhang, Guozhou Zheng, Huajun Chen
Community Contributors: thredreams, eltociear, Ziwen Xu, Rui Huang, Xiaolong Weng