Project Page | Paper | Model Card ?
Our follow-up work Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models (CVPRW 2024) presents a posterior sampling for better image generation and handles real-world mixed-degradation images similar to Real-ESRGAN.
[2024.04.16] Our follow-up paper "Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models" is on ArXiv now!
[2024.04.15] Updated a wild-IR model for real-world degradations and the posterior sampling for better image generation. The pretrained weights wild-ir.pth and wild-daclip_ViT-L-14.pt are also provided for wild-ir.
[2024.01.20] ??? Our DA-CLIP paper was accepted by ICLR 2024 ??? We further provide a more robust model in the model card.
[2023.10.25] Added dataset links for training and testing.
[2023.10.13] Added the Replicate demo and api. Thanks to @chenxwh!!! We updated the Hugging Face demo and online Colab demo. Thanks to @fffiloni and @camenduru !!! We also made a Model Card in Hugging Face ? and provided more examples for testing.
[2023.10.09] The pretrained weights of DA-CLIP and the Universal IR model are released in link1 and link2, respectively. In addition, we also provide a Gradio app file for the case that you want to test your own images.
We advise you first create a virtual environment with:
python3 -m venv .env
source .env/bin/activate
pip install -U pip
pip install -r requirements.txt
Get into the universal-image-restoration directory and run:
import torch
from PIL import Image
import open_clip
checkpoint = 'pretrained/daclip_ViT-B-32.pt'
model, preprocess = open_clip.create_model_from_pretrained('daclip_ViT-B-32', pretrained=checkpoint)
tokenizer = open_clip.get_tokenizer('ViT-B-32')
image = preprocess(Image.open("haze_01.png")).unsqueeze(0)
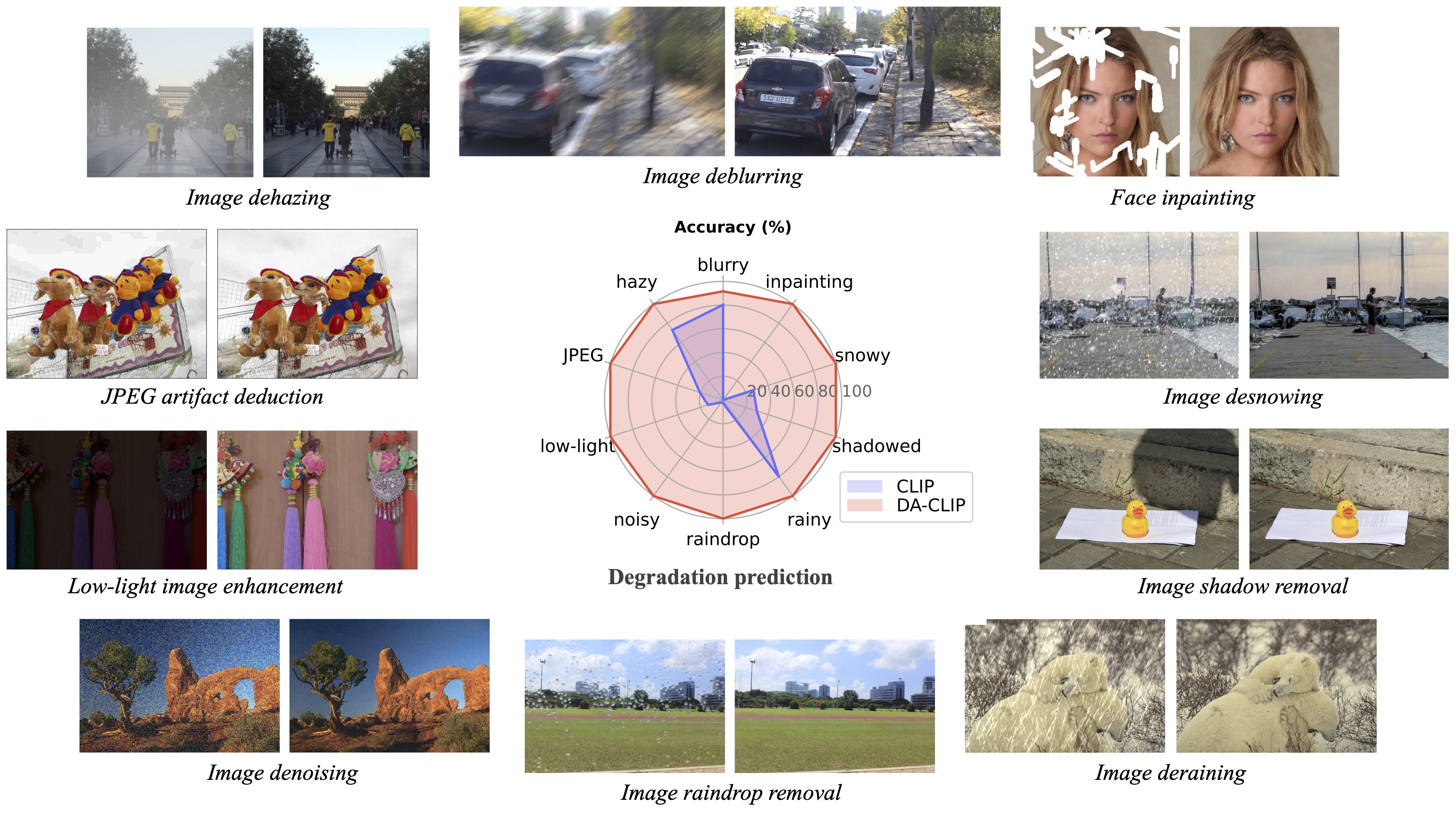
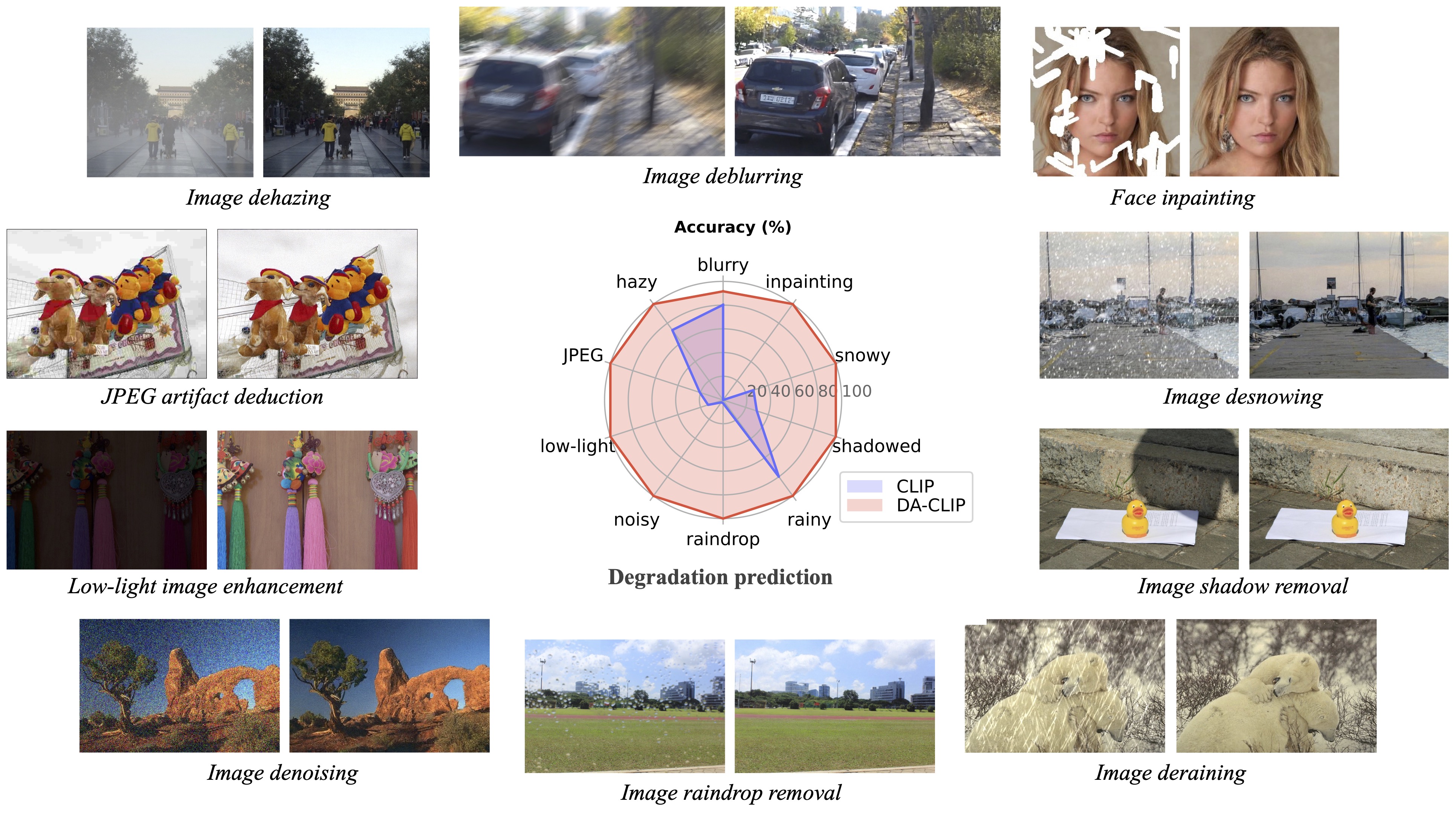
degradations = ['motion-blurry','hazy','jpeg-compressed','low-light','noisy','raindrop','rainy','shadowed','snowy','uncompleted']
text = tokenizer(degradations)
with torch.no_grad(), torch.cuda.amp.autocast():
text_features = model.encode_text(text)
image_features, degra_features = model.encode_image(image, control=True)
degra_features /= degra_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * degra_features @ text_features.T).softmax(dim=-1)
index = torch.argmax(text_probs[0])
print(f"Task: {task_name}: {degradations[index]} - {text_probs[0][index]}")Preparing the train and test datasets following our paper Dataset Construction section as:
#### for training dataset ####
#### (uncompleted means inpainting) ####
datasets/universal/train
|--motion-blurry
| |--LQ/*.png
| |--GT/*.png
|--hazy
|--jpeg-compressed
|--low-light
|--noisy
|--raindrop
|--rainy
|--shadowed
|--snowy
|--uncompleted
#### for testing dataset ####
#### (the same structure as train) ####
datasets/universal/val
...
#### for clean captions ####
datasets/universal/daclip_train.csv
datasets/universal/daclip_val.csvThen get into the universal-image-restoration/config/daclip-sde directory and modify the dataset paths in option files in options/train.yml and options/test.yml.
You can add more tasks or datasets to both train and val directories and add the degradation word to distortion.
| Degradation | motion-blurry | hazy | jpeg-compressed* | low-light | noisy* (same to jpeg) |
|---|---|---|---|---|---|
| Datasets | Gopro | RESIDE-6k | DIV2K+Flickr2K | LOL | DIV2K+Flickr2K |
| Degradation | raindrop | rainy | shadowed | snowy | uncompleted |
|---|---|---|---|---|---|
| Datasets | RainDrop | Rain100H: train, test | SRD | Snow100K | CelebaHQ-256 |
You should only extract the train datasets for training, and all validation datasets can be downloaded in the Google drive. For jpeg and noisy datasets, you can generate LQ images using this script.
See DA-CLIP.md for details.
The main code for training is in universal-image-restoration/config/daclip-sde and the core network for DA-CLIP is in universal-image-restoration/open_clip/daclip_model.py.
Put the pretrained DA-CLIP weights to pretrained directory and check the daclip path.
You can then train the model following below bash scripts:
cd universal-image-restoration/config/daclip-sde
# For single GPU:
python3 train.py -opt=options/train.yml
# For distributed training, need to change the gpu_ids in option file
python3 -m torch.distributed.launch --nproc_per_node=2 --master_port=4321 train.py -opt=options/train.yml --launcher pytorchThe models and training logs will save in log/universal-ir.
You can print your log at time by running tail -f log/universal-ir/train_universal-ir_***.log -n 100.
The same training steps can be used for image restoration in the wild (wild-ir).
| Model Name | Description | GoogleDrive | HuggingFace |
|---|---|---|---|
| DA-CLIP | Degradation-aware CLIP model | download | download |
| Universal-IR | DA-CLIP based universal image restoration model | download | download |
| DA-CLIP-mix | Degradation-aware CLIP model (add Gaussian blur + face inpainting and Gaussian blur + Rainy) | download | download |
| Universal-IR-mix | DA-CLIP based universal image restoration model (add robust training and mix-degradations) | download | download |
| Wild-DA-CLIP | Degradation-aware CLIP model in the wild (ViT-L-14) | download | download |
| Wild-IR | DA-CLIP based image restoration model in the wild | download | download |
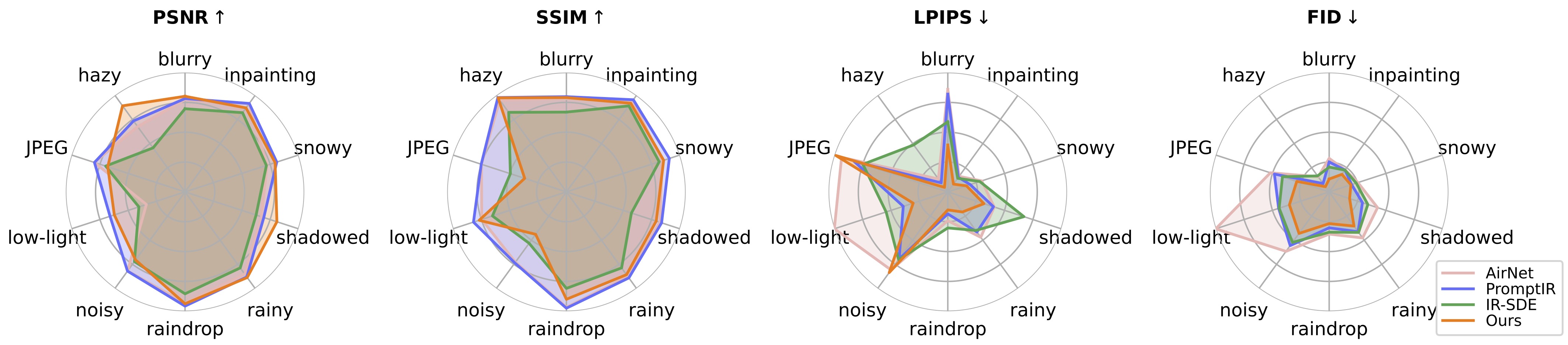
To evalute our method on image restoration, please modify the benchmark path and model path and run
cd universal-image-restoration/config/universal-ir
python test.py -opt=options/test.ymlHere we provide an app.py file for testing your own images. Before that, you need to download the pretrained weights (DA-CLIP and UIR) and modify the model path in options/test.yml. Then by simply running python app.py, you can open http://localhost:7860 to test the model. (We also provide several images with different degradations in the images dir). We also provide more examples from our test dataset in the google drive.
The same steps can be used for image restoration in the wild (wild-ir).



? In testing we found that the current pretrained model is still difficult to process some real-world images which might have distribution shifts with our training dataset (captured from different devices or with different resolutions or degradations). We regard it as a future work and will try to make our model more practical! We also encourage users who are interested in our work to train their own models with larger dataset and more degradation types.
? BTW, we also found that directly resizing input images will lead a poor performance for most tasks. We could try to add the resize step into the training but it always destroys the image quality due to interpolation.
? For the inpainting task our current model only supports face inpainting due to the dataset limitation. We provide our mask examples and you can use the generate_masked_face script to generate uncompleted faces.
Acknowledgment: Our DA-CLIP is based on IR-SDE and open_clip. Thanks for their code!
If you have any question, please contact: [email protected]
If our code helps your research or work, please consider citing our paper. The following are BibTeX references:
@article{luo2023controlling,
title={Controlling Vision-Language Models for Universal Image Restoration},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2310.01018},
year={2023}
}
@article{luo2024photo,
title={Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models},
author={Luo, Ziwei and Gustafsson, Fredrik K and Zhao, Zheng and Sj{"o}lund, Jens and Sch{"o}n, Thomas B},
journal={arXiv preprint arXiv:2404.09732},
year={2024}
}