
Xuan Ju1*, Yiming Gao1*, Zhaoyang Zhang1*#, Ziyang Yuan1, Xintao Wang1, Ailing Zeng, Yu Xiong, Qiang Xu, Ying Shan1
1ARC Lab, Tencent PCG 2The Chinese University of Hong Kong *Equal Contribution #Project Lead
Video datasets play a crucial role in video generation such as Sora. However, existing text-video datasets often fall short when it comes to handling long video sequences and capturing shot transitions. To address these limitations, we introduce MiraData, a video dataset designed specifically for long video generation tasks. Moreover, to better assess temporal consistency and motion intensity in video generation, we introduce MiraBench, which enhances existing benchmarks by adding 3D consistency and tracking-based motion strength metrics. You can find more details in our research papaer.
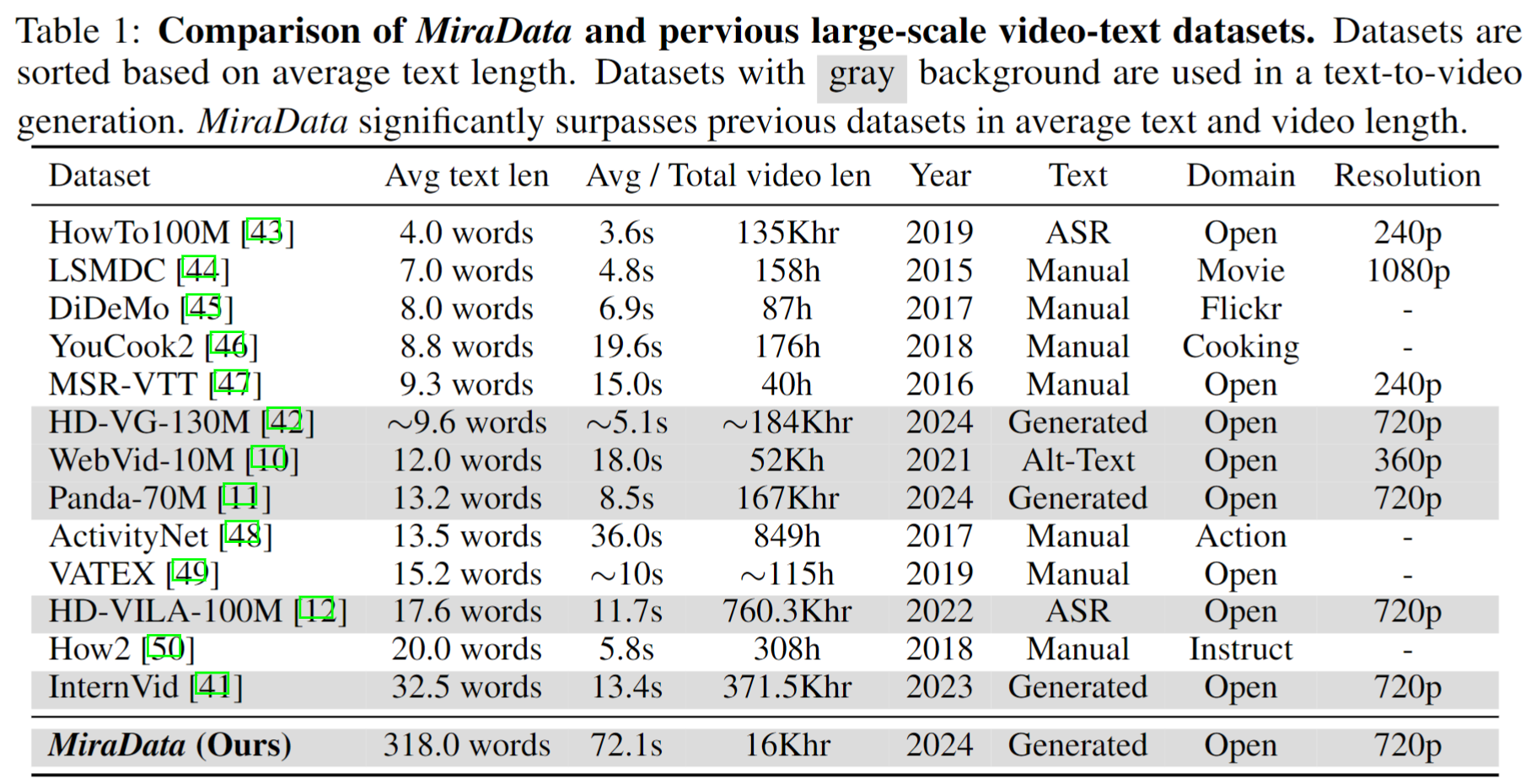
We release four versions of MiraData, containing 330K, 93K, 42K, 9K data.
The meta file for this version of MiraData is provided in Google Drive and HuggingFace Dataset. Additionally, for a better and quicker understanding of our meta file composition, we randomly sample a set of 100 video clips, which can be accessed here. The meta file contains the following index information:
{download_id}.{clip_id}
To download the videos and split them into clips, start by downloading the meta files from Google Drive or HuggingFace Dataset. Once you have the meta files, you can use the following scripts to download the video samples:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
We will remove the video samples from our dataset / Github / project webpage as long as you need it. Please contact to us for the request.
To collect the MiraData, we first manually select youtube channels in different scenarios and include videos from HD-VILA-100M, Videovo, Pixabay, and Pexels. Then, all the videos in corresponding channels are downloaded and splitted using PySceneDetect. We then used multiple models to stitch the short clips together and filter out low-quality videos. Following this, we selected video clips with long durations. Finally, we captioned all video clips using GPT-4V.

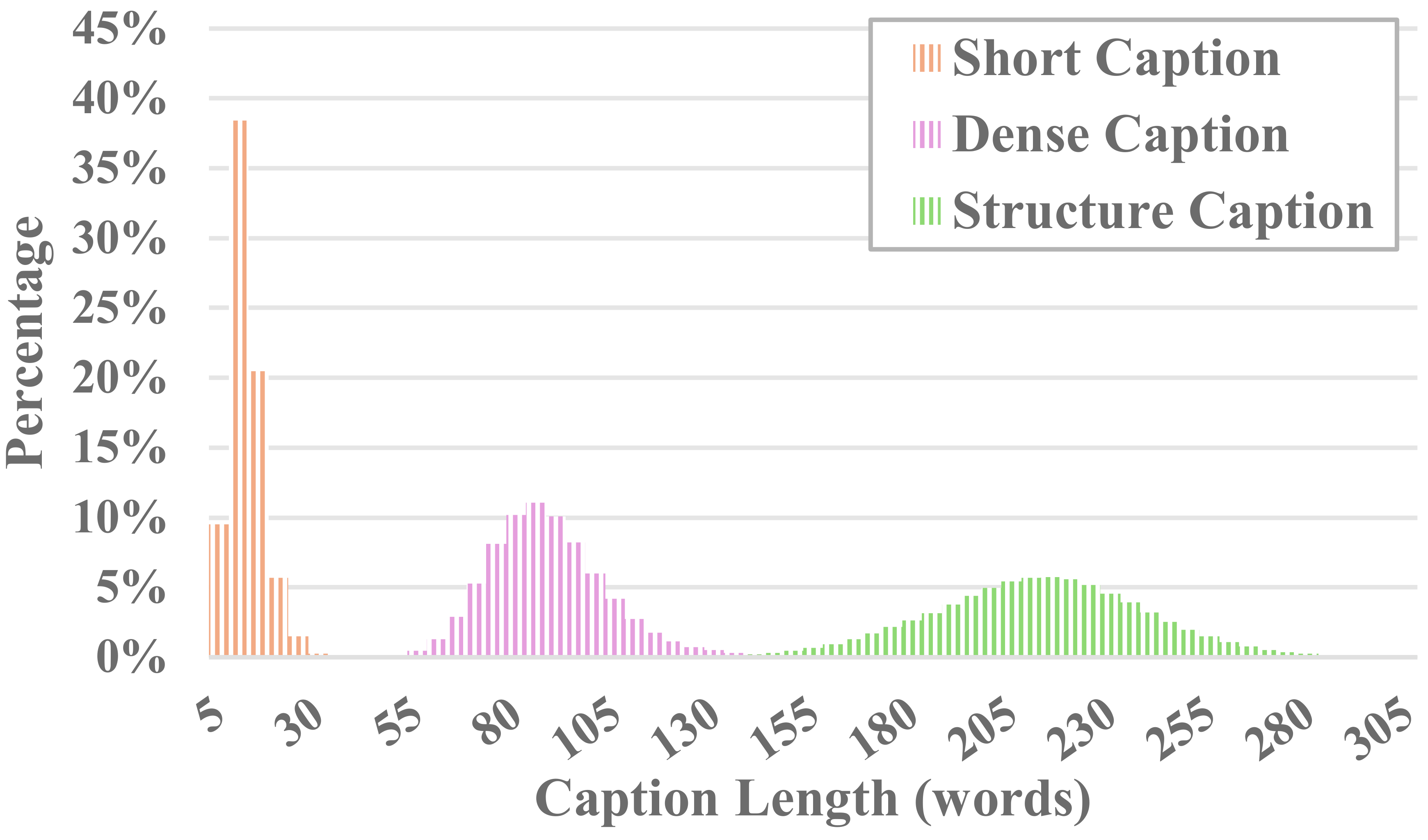
Each video in MiraData is accompanied by structured captions. These captions provide detailed descriptions from various perspectives, enhancing the richness of the dataset.
Six Types of Captions
We tested the existing open-source visual LLM methods and GPT-4V, and found that GPT-4V's captions show better accuracy and coherence in semantic understanding in terms of temporal sequence.
In order to balance annotation costs and caption accuracy, we uniformly sample 8 frames for each video and arrange them into a 2x4 grid of one large image. Then, we use the caption model of Panda-70M to annotate each video with a one-sentence caption, which serves as a hint for the main content, and input it into our fine-tuned prompt. By feeding the fine-tuned prompt and a 2x4 large image to GPT-4V, we can efficiently output captions for multiple dimensions in just one round of conversation. The specific prompt content can be found in the caption_gpt4v.py, and we welcome everyone to contribute to the more high-quality text-video data. ?

To evaluate long video generation, we design 17 evaluation metrics in MiraBench from 6 perspectives, including temporal consistency, temporal motion strength, 3D consistency, visual quality, text-video alignment, and distribution consistency. These metrics encompass most of the common evaluation standards used in previous video generation models and text-to-video benchmarks.
To evaluate generated videos, please first set up python environment through:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
Then, run evaluation through:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
You can follow the example in data/evaluation_example to evaluate your own generated videos.
Please see LICENSE.
If you find this project useful for your research, please cite our paper. ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
For any inquiries, please email [email protected].
MiraData is under the GPL-v3 Licence and is supported for commercial usage. If you need a commercial license for MiraData, please feel free to contact us.


