gpt neox
GPT-NeoX 2.0
This repository records EleutherAI's library for training large-scale language models on GPUs. Our current framework is based on NVIDIA's Megatron Language Model and has been augmented with techniques from DeepSpeed as well as some novel optimizations. We aim to make this repo a centralized and accessible place to gather techniques for training large-scale autoregressive language models, and accelerate research into large-scale training. This library is in widespread use in academic, industry, and government labs, including by researchers at Oak Ridge National Lab, CarperAI, Stability AI, Together.ai, Korea University, Carnegie Mellon University, and the University of Tokyo among others. Uniquely among similar libraries GPT-NeoX supports a wide variety of systems and hardwares, including launching via Slurm, MPI, and the IBM Job Step Manager, and has been run at scale on AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI, and others.
If you are not looking to train models with billions of parameters from scratch, this is likely the wrong library to use. For generic inference needs, we recommend you use the Hugging Face transformers library instead which supports GPT-NeoX models.
GPT-NeoX leverages many of the same features and technologies as the popular Megatron-DeepSpeed library but with substantially increased usability and novel optimizations. Major features include:
[9/9/2024] We now support preference learning via DPO, KTO, and reward modeling
[9/9/2024] We now support integration with Comet ML, a machine learning monitoring platform
[5/21/2024] We now support RWKV with pipeline parallelism!. See the PRs for RWKV and RWKV+pipeline
[3/21/2024] We now support Mixture-of-Experts (MoE)
[3/17/2024] We now support AMD MI250X GPUs
[3/15/2024] We now support Mamba with tensor parallelism! See the PR
[8/10/2023] We now support checkpointing with AWS S3! Activate with the s3_path config option (for more detail, see the PR)
[9/20/2023] As of #1035, we have deprecated Flash Attention 0.x and 1.x, and migrated support to Flash Attention 2.x. We don't believe this will cause problems, but if you have a specific use-case that requires old flash support using the latest GPT-NeoX, please raise an issue.
[8/10/2023] We have experimental support for LLaMA 2 and Flash Attention v2 supported in our math-lm project that will be upstreamed later this month.
[5/17/2023] After fixing some miscellaneous bugs we now fully support bf16.
[4/11/2023] We have upgraded our Flash Attention implementation to now support Alibi positional embeddings.
[3/9/2023] We have released GPT-NeoX 2.0.0, an upgraded version built on the latest DeepSpeed which will be regularly synced with going forward.
Prior to 3/9/2023, GPT-NeoX relied on DeeperSpeed, which was based on an old version of DeepSpeed (0.3.15). In order to migrate to the latest upstream DeepSpeed version while allowing users to access the old versions of GPT-NeoX and DeeperSpeed, we have introduced two versioned releases for both libraries:
This codebase has primarily developed and tested for Python 3.8-3.10, and PyTorch 1.8-2.0. This is not a strict requirement, and other versions and combinations of libraries may work.
To install the remaining basic dependencies, run:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometfrom the repository root.
Warning
Our codebase relies on DeeperSpeed, our fork of the DeepSpeed library with some added changes. We strongly recommend using Anaconda, a virtual machine, or some other form of environment isolation before continuing. Failure to do so may cause other repositories that rely on DeepSpeed to break.
We now support AMD GPUs (MI100, MI250X) through JIT fused-kernel compilation. Fused kernels will be built and loaded as needed. To avoid waiting during job launching, you can also do the following for manual pre-build:
python
from megatron.fused_kernels import load
load()This will automatically adapts building process over different GPU vendors (AMD, NVIDIA) without platform specific code changes. To further test fused kernels using pytest, use pytest tests/model/test_fused_kernels.py
To use Flash-Attention, install the additional dependencies in ./requirements/requirements-flashattention.txt and set the attention type in your configuration accordingly (see configs). This can provide significant speed-ups over regular attention on certain GPU architectures, including Ampere GPUs (such as A100s); see the repository for more details.
NeoX and Deep(er)Speed support training on multiple different nodes and you have the option of using a variety of different launchers to orchestrate multi-node jobs.
In general there needs to be a "hostfile" somewhere accessible with the format:
node1_ip slots=8
node2_ip slots=8where the first column contains the IP address for each node in your setup and the number of slots is the number of GPUs that node has access to. In your config you must pass in the path to the hostfile with "hostfile": "/path/to/hostfile". Alternatively the path to the hostfile can be in the environment variable DLTS_HOSTFILE.
pdsh is the default launcher, and if you're using pdsh then all you must do (besides ensuring that pdsh is installed in your environment) is set {"launcher": "pdsh"} in your config files.
If using MPI then you must specify the MPI library (DeepSpeed/GPT-NeoX currently supports mvapich, openmpi, mpich, and impi, though openmpi is the most commonly used and tested) as well as pass the deepspeed_mpi flag in your config file:
{
"launcher": "openmpi",
"deepspeed_mpi": true
}With your environment properly set up and the correct configuration files you can use deepy.py like a normal python script and start (for example) a training job with:
python3 deepy.py train.py /path/to/configs/my_model.yml
Using Slurm can be slightly more involved. Like with MPI, you must add the following to your config:
{
"launcher": "slurm",
"deepspeed_slurm": true
}If you do not have ssh access to the compute nodes in your Slurm cluster you need to add {"no_ssh_check": true}
There are many cases where the above default launching options are not sufficient
In these cases, you will need to modify the DeepSpeed multinode runner utility to support your usecase. Broadly, these enhancements fall under two categories:
In this case, you must add a new multinode runner class to deepspeed/launcher/multinode_runner.py and expose it as a configuration option in GPT-NeoX. Examples on how we did this for Summit JSRun are in this DeeperSpeed commit and this GPT-NeoX commit, respectively.
We have encountered many cases where we wish to modify the MPI/Slurm run command for an optimization or to debug (e.g. to modify the Slurm srun CPU binding or to tag MPI logs with the rank). In this case, you must modify the multinode runner class' run command under its get_cmd method (e.g. mpirun_cmd for OpenMPI). Examples on how we did this to provide optimized and rank-tagged run commands using Slurm and OpenMPI for the Stability cluster are in this DeeperSpeed branch
In general you will not be able to have a single fixed hostfile, so you need to have a script to generate one dynamically when your job starts. An example script to dynamically generate a hostfile using Slurm and 8 GPUs per node is:
#!/bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_$SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile &> /dev/null
# loop over the node names
for i in `scontrol show hostnames $SLURM_NODELIST`
do
# add a line to the hostfile
echo $i slots=$GPUS_PER_NODE >>$hostfile
done$SLURM_JOBID and $SLURM_NODELIST being environment variables Slurm will create for you. See the sbatch documentation for a full list of available Slurm environment variables set at job creation time.
Then you can create an sbatch script from which to kick off your GPT-NeoX job. A bare-bones sbatch script on a Slurm-based cluster with 8 GPUs per node would look like this:
#!/bin/bash
#SBATCH --job-name="neox"
#SBATCH --partition=your-partition
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=8
#SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES=`scontrol show hostnames "$SLURM_JOB_NODELIST"`
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
export MASTER_PORT=12802
export COUNT_NODE=`scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l`
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_$SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
You can then kick off a training run with sbatch my_sbatch_script.sh
We also provide a Dockerfile and docker-compose configuration if you prefer to run NeoX in a container.
Requirements to run the container are to have appropriate GPU drivers, an up-to-date installation of Docker, and nvidia-container-toolkit installed. To test if your installation is good you can use their "sample workload", which is:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Provided that will run, you need to export NEOX_DATA_PATH and NEOX_CHECKPOINT_PATH in your environment to specify your data directory and directory for storing and loading checkpoints:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
And then, from the gpt-neox directory, you can build the image and run a shell in a container with
docker compose run gpt-neox bash
After the build, you should be able to do this:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
For a long-running job, you should run
docker compose up -d
to run the container in detached mode, and then, in a separate terminal session, run
docker compose exec gpt-neox bash
You can then run any job you want from inside the container.
Concerns when running for a long time or in detached mode include
If you prefer to run the prebuilt container image from dockerhub, you can run the docker compose commands with -f docker-compose-dockerhub.yml instead, e.g.,
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
All functionality should be launched using deepy.py, a wrapper around the deepspeed launcher.
We currently offer three main functions:
train.py is used for training and finetuning models.eval.py is used to evaluate a trained model using the language model evaluation harness.generate.py is used to sample text from a trained model.which can be launched with:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]For example, to launch training you can run
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlFor more details on each entry point, see the Training and Finetuning, Inference and Evaluation respectively.
GPT-NeoX parameters are defined in a YAML configuration file which is passed to the deepy.py launcher. We have provided some example .yml files in configs, showing a diverse array of features and model sizes.
These files are generally complete, but non-optimal. For example, depending on your specific GPU configuration, you may need to change some settings such as pipe-parallel-size, model-parallel-size to increase or decrease the degree of parallelisation, train_micro_batch_size_per_gpu or gradient-accumulation-steps to modify batch size related settings, or the zero_optimization dict to modify how optimizer states are parallelised across workers.
For a more detailed guide to the features available and how to configure them, see the configuration README, and for documentation of every possible argument, see configs/neox_arguments.md.
GPT-NeoX includes multiple expert implementations for MoE. To select between them, specify moe_type of megablocks (default) or deepspeed.
Both are based on the DeepSpeed MoE parallelism framework, which supports tensor-expert-data parallelism. Both allow you to toggle between token-dropping and dropless (default, and this is what Megablocks was designed for). Sinkhorn routing to come soon!
For an example of a basic complete configuration, see configs/125M-dmoe.yml (for Megablocks dropless) or configs/125M-moe.yml.
Most MoE related configuration arguments are prefixed with moe. Some common configuration parameters and their defaults are as follows:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed can be further configured with the following:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
One MoE layer is present every expert_interval transformer layers including the first, so with 12 layers total:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
Experts would be in these layers:
0, 2, 4, 6, 8, 10
By default, we use expert-data parallelism, so any available tensor parallelism (model_parallel_size) will be used for expert routing. For instance, given the following:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
With 32 GPUs, the behavior will be look like:
expert_parallel_size == model_parallel_size.Setting enable_expert_tensor_parallelism enables tensor-expert-data (TED) parallelism. The way to interpret the above would then be:
expert_parallel_size == 1 or model_parallel_size == 1.So note that DP must be divisible by (MP * EP). For more details, see the TED paper.
Pipeline parallelism is not yet supported - coming soon!
Several preconfigured datasets are available, including most components from the Pile, as well as the Pile train set itself, for straightforward tokenization using the prepare_data.py entry point.
E.G, to download and tokenize the enwik8 dataset with the GPT2 Tokenizer, saving them to ./data you can run:
python prepare_data.py -d ./data
or a single shard of the pile (pile_subset) with the GPT-NeoX-20B tokenizer (assuming you have it saved at ./20B_checkpoints/20B_tokenizer.json):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
The tokenized data will be saved out to two files: [data-dir]/[dataset-name]/[dataset-name]_text_document.binand [data-dir]/[dataset-name]/[dataset-name]_text_document.idx. You will need to add the prefix that both these files share to your training configuration file under the data-path field. E.G:
"data-path": "./data/enwik8/enwik8_text_document",To prepare your own dataset for training with custom data, format it as one large jsonl-formatted file with each item in the list of dictionaries being a separate document. The document text should be grouped under one JSON key, i.e "text". Any auxiliary data stored in other fields will not be used.
Next make sure to download the GPT2 tokenizer vocab, and merge files from the following links:
Or use the 20B tokenizer (for which only a single Vocab file is needed):
(alternatively, you can provide any tokenizer file that can be loaded by Hugging Face's tokenizers library with the Tokenizer.from_pretrained() command)
You can now pretokenize your data using tools/datasets/preprocess_data.py, the arguments for which are detailed below:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
For example:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodYou would then run training with the following settings added to your configuration file:
"data-path": "data/mydataset_text_document",Training is launched using deepy.py, a wrapper around DeepSpeed's launcher, which launches the same script in parallel across many GPUs / nodes.
The general usage pattern is:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...You can pass in an arbitrary number of configs which will all be merged at runtime.
You can also optionally pass in a config prefix, which will assume all your configs are in the same folder and append that prefix to their path.
For example:
python ./deepy.py train.py -d configs 125M.yml local_setup.ymlThis will deploy the train.py script on all nodes with one process per GPU. The worker nodes and number of GPUs are specified in the /job/hostfile file (see parameter documentation), or can simply be passed in as the num_gpus arg if running on a single node setup.
Although this is not strictly necessary, we find it useful to define the model parameters in one config file (e.g configs/125M.yml) and the data path parameters in another (e.g configs/local_setup.yml).
GPT-NeoX-20B is a 20 billion parameter autoregressive language model trained on the Pile. Technical details about GPT-NeoX-20B can be found in the associated paper. The configuration file for this model is both available at ./configs/20B.yml and included in the download links below.
Slim weights - (No optimizer states, for inference or finetuning, 39GB)
To download from the command line to a folder named 20B_checkpoints, use the following command:
wget --cut-dirs=5 -nH -r --no-parent --reject "index.html*" https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsFull weights - (Including optimizer states, 268GB)
To download from the command line to a folder named 20B_checkpoints, use the following command:
wget --cut-dirs=5 -nH -r --no-parent --reject "index.html*" https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsWeights can be alternatively be downloaded using a BitTorrent client. Torrent files can be downloaded here: slim weights, full weights.
We additionally have 150 checkpoints saved throughout training, one every 1,000 steps. We are working on figuring out how to best serve these at scale, but in the meanwhile people interested in working with the partially trained checkpoints can email us at [email protected] to arrange access.
The Pythia Scaling Suite is a suite of models ranging from 70M parameters to 12B parameters trained on the Pile intended to promote research on interpretability and training dynamics of large language models. Further details about the project and links to the models can be found in the in the paper and on the project's GitHub.
The Polyglot Project is an effort to train powerful non-English pretrained language models to promote the accessibility of this technology to researchers outside the dominant powerhouses of machine learning. EleutherAI has trained and released 1.3B, 3.8B, and 5.8B parameter Korean language models, the largest of which outpreforms all other publicly available language models on Korean language tasks. Further details about the project and links to the models can be found here.
For most uses we recommend deploying models trained using the GPT-NeoX library via the Hugging Face Transformers library which is better optimized for inference.
We support three types of generation from a pretrained model:
All three types of text generation can be launched via python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml with the appropriate values set in configs/text_generation.yml.
GPT-NeoX supports evaluation on downstream tasks through the language model evaluation harness.
To evaluate a trained model on the evaluation harness, simply run:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... tasknwhere --eval_tasks is a list of evaluation tasks followed by spaces, e.g --eval_tasks lambada hellaswag piqa sciq. For details of all tasks available, refer to the lm-evaluation-harness repo.
GPT-NeoX is optimized heavily for training only, and GPT-NeoX model checkpoints are not compatible out of the box with other deep learning libraries. To make models easily loadable and shareable with end users, and for further exporting to various other frameworks, GPT-NeoX supports checkpoint conversion to the Hugging Face Transformers format.
Though NeoX supports a number of different architectural configurations, including AliBi positional embeddings, not all of these configurations map cleanly onto the supported configurations within Hugging Face Transformers.
NeoX supports export of compatible models into the following architectures:
Training a model which does not fit into one of these Hugging Face Transformers architectures cleanly will require writing custom modeling code for the exported model.
To convert a GPT-NeoX library checkpoint to Hugging Face-loadable format, run:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}Then to upload a model to the Hugging Face Hub, run:
huggingface-cli login
python ./tools/ckpts/upload.pyand input the requested information, including HF hub user token.
NeoX supplies several utilities for converting a pretrained model checkpoint into a format that can be trained within the library.
The following models or model families can be loaded in GPT-NeoX:
We provide two utilities for converting from two different checkpoint formats into a format compatible with GPT-NeoX.
To convert a Llama 1 or Llama 2 checkpoint distributed by Meta AI from its original file format (downloadable here or here) into the GPT-NeoX library, run
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
To convert from a Hugging Face model into a NeoX-loadable, run tools/ckpts/convert_hf_to_sequential.py. See documentation within that file for further options.
In addition to storing logs locally, we provide built-in support for two popular experiment monitoring frameworks: Weights & Biases, TensorBoard, and Comet
Weights & Biases to record our experiments is a machine learning monitoring platform. To use wandb to monitor your gpt-neox experiments:
wandb login—your runs will automatically be recorded../requirements/requirements-wandb.txt. An example config is provided in ./configs/local_setup_wandb.yml.wandb_group allows you to name the run group and wandb_team allows you to assign your runs to an organization or team account. An example config is provided in ./configs/local_setup_wandb.yml.We support using TensorBoard via the tensorboard-dir field. Dependencies required for TensorBoard monitoring can be found in and installed from ./requirements/requirements-tensorboard.txt.
Comet is a machine learning monitoring platform. To use comet to monitor your gpt-neox experiments:
comet login or passing export COMET_API_KEY=<your-key-here>
comet_ml and any dependency libraries via pip install -r requirements/requirements-comet.txt
use_comet: True. You can also customize where data is being logged with comet_workspace and comet_project. A full example config with comet enabled is provided in configs/local_setup_comet.yml.If you need to supply a hostfile for use with the MPI-based DeepSpeed launcher, you can set the environment variable DLTS_HOSTFILE to point to the hostfile.
We support profiling with Nsight Systems, the PyTorch Profiler, and PyTorch Memory Profiling.
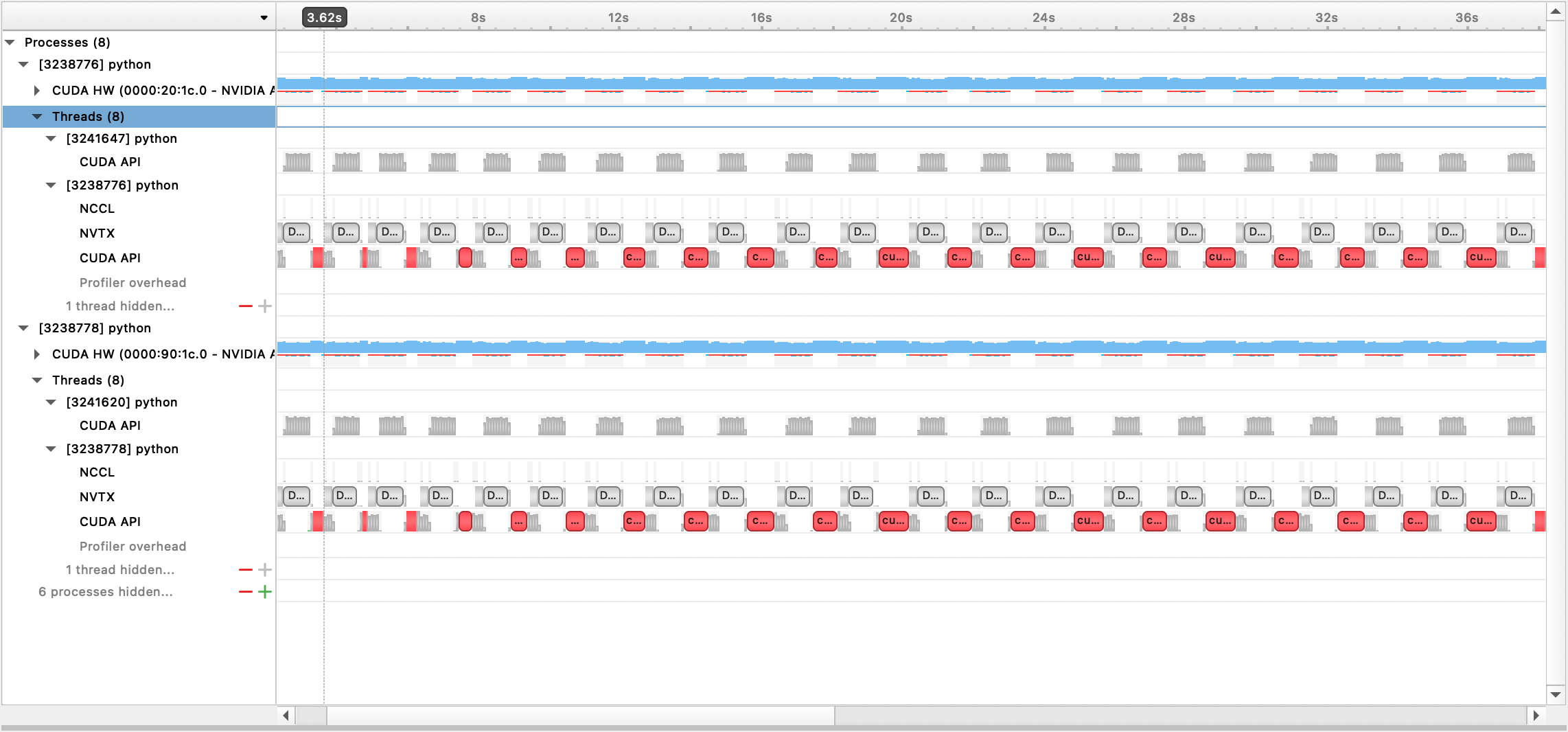
To use the Nsight Systems profiling, set config options profile, profile_step_start, and profile_step_stop (see here for argument usage, and here for a sample config).
To populate nsys metrics, launch training with:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
The generated output file can then by viewed with the Nsight Systems GUI:
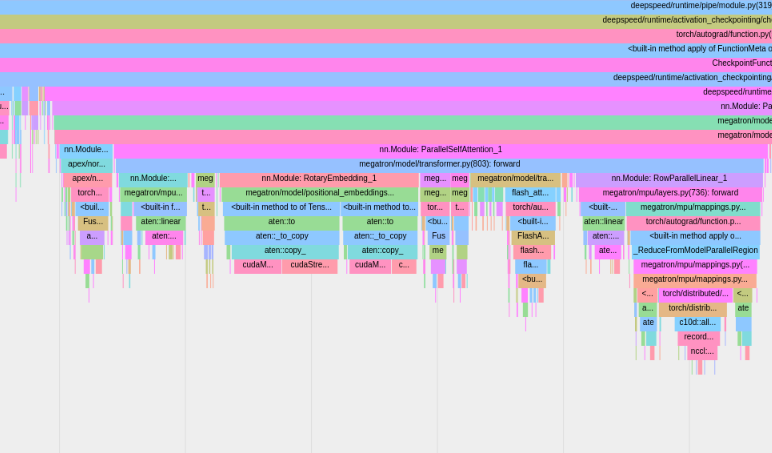
To use the built-in PyTorch profiler, set config options profile, profile_step_start, and profile_step_stop (see here for argument usage, and here for a sample config).
The PyTorch profiler will save traces to your tensorboard log directory. You can view these traces within
TensorBoard by following the steps here.
To use PyTorch Memory Profiling, set config options memory_profiling and memory_profiling_path (see here for argument usage, and here for a sample config).
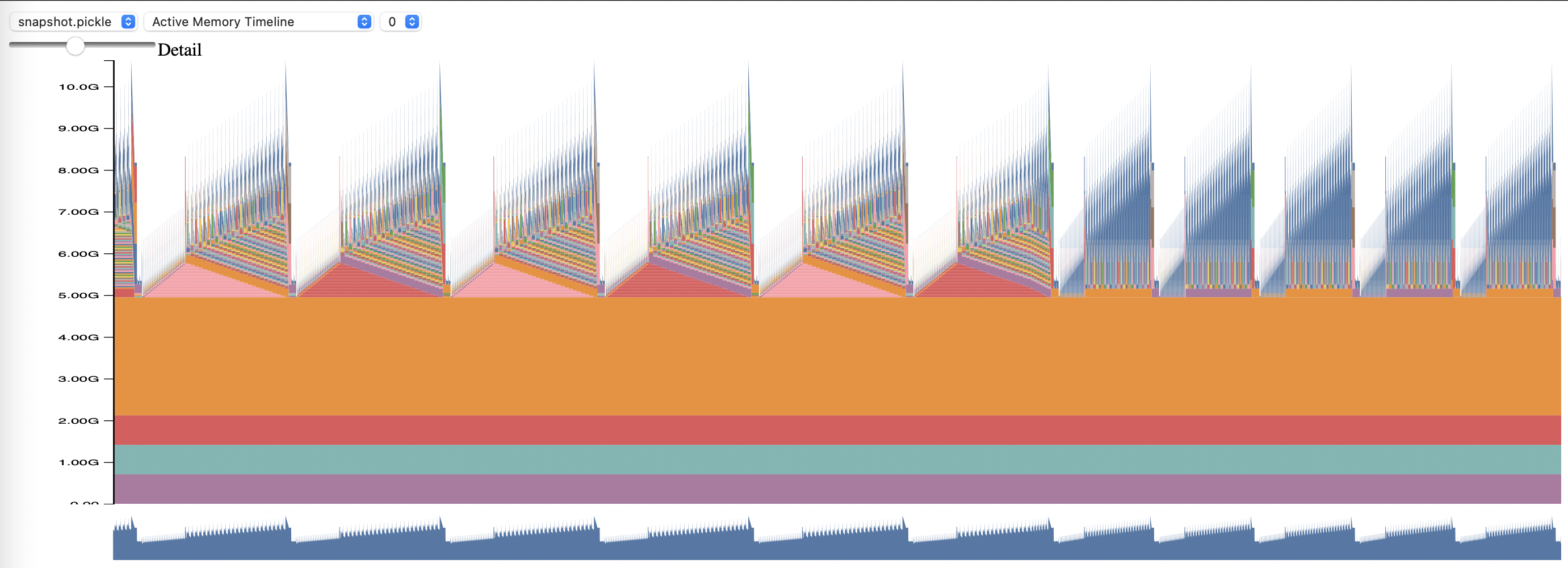
View the generated profile with the memory_viz.py script. Run with:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
The GPT-NeoX library was been widely adopted by academic and industry researchers and ported on to many HPC systems.
If you have found this library useful in your research, please reach out and let us know! We would love to add you to our lists.
EleutherAI and our collaborators have used it in the following publications:
The following publications by other research groups use this library:


