discoart
v0.12.1
One can also generate runnable Python code directly from the config:
from discoart.config import export_python
export_python(da)If you are a free-tier Google Colab user, one annoy thing is the lost of sessions from time to time. Or sometimes you just early stop the run as the first image is not good enough, and a keyboard interrupt will prevent .create() to return any result. Either case, you can easily recover the results by pulling the last session ID.
Find the session ID. It appears on top of the image.
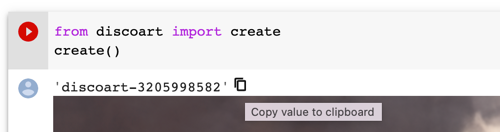
Pull the result via that ID on any machine at any time, not necessarily on Google Colab:
from docarray import DocumentArray
da = DocumentArray.pull('discoart-3205998582')Consider a Document as a self-contained data with config and image, one can use it as the initial state for the future run. Its .tags will be used as the initial parameters; .uri if presented will be used as the initial image.
from discoart import create
from docarray import DocumentArray
da = DocumentArray.pull('discoart-3205998582')
create(
init_document=da[0],
cut_ic_pow=0.5,
tv_scale=600,
cut_overview='[12]*1000',
cut_innercut='[12]*1000',
use_secondary_model=False,
)If you just want to initialize from a known DocArray ID, then simply:
from discoart import create
create(init_document='discoart-3205998582')You can set environment variables to control the meta-behavior of DiscoArt. The environment variables must be set before importing DiscoArt, either in Bash or in Python via os.environ.
DISCOART_LOG_LEVEL='DEBUG' # more verbose logs
DISCOART_OPTOUT_CLOUD_BACKUP='1' # opt-out from cloud backup
DISCOART_DISABLE_IPYTHON='1' # disable ipython dependency
DISCOART_DISABLE_RESULT_SUMMARY='1' # disable result summary after the run ends
DISCOART_DEFAULT_PARAMETERS_YAML='path/to/your-default.yml' # use a custom default parameters file
DISCOART_CUT_SCHEDULES_YAML='path/to/your-schedules.yml' # use a custom cut schedules file
DISCOART_MODELS_YAML='path/to/your-models.yml' # use a custom list of models file
DISCOART_OUTPUT_DIR='path/to/your-output-dir' # use a custom output directory for all images and results
DISCOART_CACHE_DIR='path/to/your-cache-dir' # use a custom cache directory for models and downloads
DISCOART_DISABLE_REMOTE_MODELS='1' # disable the listing of diffusion models on Github, remote diffusion models allows user to use latest models without updating the codebase.
DISCOART_REMOTE_MODELS_URL='https://yourdomain/models.yml' # use a custom remote URL for fetching models list
DISCOART_DISABLE_CHECK_MODEL_SHA='1' # disable checking local model SHA matches the remote model SHA
DISCOART_DISABLE_TQDM='1' # disable tqdm progress bar on diffusionDiscoArt provides two commands create and config that allows you to run DiscoArt from CLI.
python -m discoart create my.ymlwhich creates artworks from the YAML config file my.yml. You can also do:
cat config.yml | python -m discoart createSo how can I have my own my.yml and what does it look like? That's the second command:
python -m discoart config my.ymlwhich forks the default YAML config and export them to my.yml. Now you can modify it and run it with python -m discoart create command.
If no output path is specified, then python -m discoart config will print the default config to stdout.
To get help on a command, add --help at the end, e.g.:
python -m discoart create --helpusage: python -m discoart create [-h] [YAML_CONFIG_FILE]
positional arguments:
YAML_CONFIG_FILE The YAML config file to use, default is stdin.
optional arguments:
-h, --help show this help message and exit
Serving DiscoArt is super easy. Simply run the following command:
python -m discoart serveYou shall see:
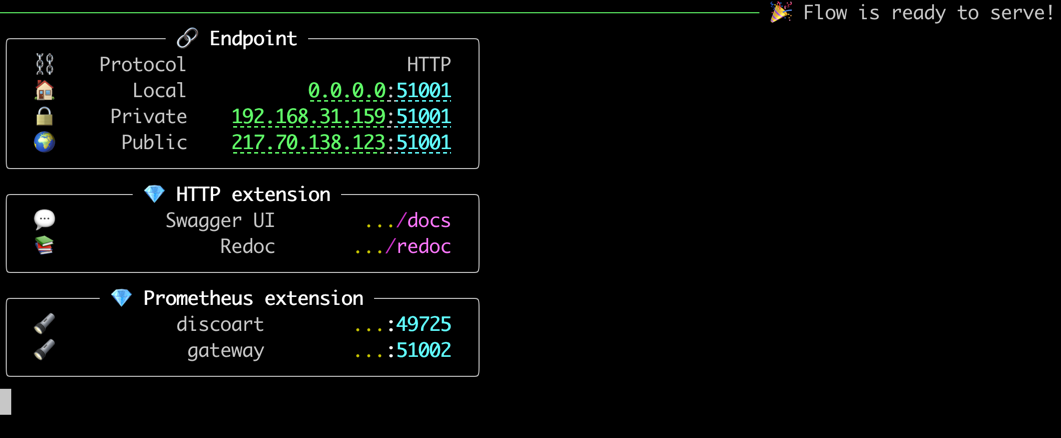
Now send request to the server via curl/Javascript, e.g.
curl
-X POST http://0.0.0.0:51001/post
-H 'Content-Type: application/json'
-d '{"execEndpoint":"/create", "parameters": {"text_prompts": ["A beautiful painting of a singular lighthouse", "yellow color scheme"]}}'That's it.
You can of course pass all parameters that accepted by create() function in the JSON.
We already know that create function is slow even on GPU it could take 10 minutes to finish an artwork. This means the after sending the above request, the client will have to wait 10 minutes for the response. There is nothing wrong with this behavior given that everything runs synchronously. However, in practice, client may expect a progress or intermediate results in the middle instead of waiting for the end.
/result endpoint is designed for this purpose. It will return the intermediate results as soon as they are available. All you need is to specify name_docarray in the request parameters as you specified in /create endpoint. Here is an example:
Let's create mydisco-123 by sending the following request to /create endpoint:
curl
-X POST http://0.0.0.0:51001/post
-H 'Content-Type: application/json'
-d '{"execEndpoint":"/create", "parameters": {"name_docarray": "mydisco-123", "text_prompts": ["A beautiful painting of a singular lighthouse", "yellow color scheme"]}}'Now that the above request is being processed on the server, you can periodically check mydisco-123 progress by sending the following request to /result endpoint:
curl
-X POST http://0.0.0.0:51001/post
-H 'Content-Type: application/json'
-d '{"execEndpoint":"/result", "parameters": {"name_docarray": "mydisco-123"}}'A JSON will be returned with up-to-date progress, with image as DataURI, loss, steps etc. The JSON Schema of Document/DocumentArray is described here.
Note, /result won't be blocked by /create thanks to the smart routing of Jina Gateway. To learn/play more about those endpoints, you can check ReDoc or the Swagger UI embedded in the server.
Send to /skip, to skip the current run and move to the next run as defined in n_batches:
curl
-X POST http://0.0.0.0:51001/post
-H 'Content-Type: application/json'
-d '{"execEndpoint":"/skip"}'Send to /stop, to stop the current run cancel all runs n_batches:
curl
-X POST http://0.0.0.0:51001/post
-H 'Content-Type: application/json'
-d '{"execEndpoint":"/stop"}'/create requestIt is possible to have an unblocked /create endpoint: the client request to /create will be immediately returned, without waiting for the results to be finished. You now have to fully rely on /result to poll the result.
To enable this feature:
flow.yml file to myflow.yml;floating: false to floating: true under discoart executor section;python -m discoart serve myflow.ymlBeware that the request velocity is now under your control. That is, if the client sends 10 /create requests in a second, then the server will start 10 create() in parallel! This can easily lead to OOM. Hence, the suggestion is only enabling this feature if you are sure that the client is not sending too many requests, e.g. you control the client request rate; or you are using DiscoArt behind a BFF (backend for frontend).
If you have multiple GPUs and you want to run multiple DiscoArt instances in parallel by leveraging GPUs in a time-multiplexed fashion, you can copy-paste the default flow.yml file and modify it as follows:
jtype: Flow
with:
protocol: http
monitoring: true
port: 51001
port_monitoring: 51002 # prometheus monitoring port
env:
JINA_LOG_LEVEL: debug
DISCOART_DISABLE_IPYTHON: 1
DISCOART_DISABLE_RESULT_SUMMARY: 1
executors:
- name: discoart
uses: DiscoArtExecutor
env:
CUDA_VISIBLE_DEVICES: RR0:3 # change this if you have multiple GPU
replicas: 3 # change this if you have larger VRAM
- name: poller
uses: ResultPollerHere replicas: 3 says spawning three DiscoArt instances, CUDA_VISIBLE_DEVICES: RR0:3 makes sure they use the first three GPUs in a round-robin fashion.
Name it as myflow.yml and then run
python -m discoart serve myflow.ymlThanks to Jina, there are tons of things you can customize! You can change the port number; change protocol to gRPC/Websockets; add TLS encryption; enable/disable Prometheus monitoring; you can also export it to Kubernetes deployment bundle simply via:
jina export kubernetes myflow.ymlFor more features and YAML configs, please check out Jina docs.
To switch from HTTP to gRPC gateway is simple:
jtype: Flow
with:
protocol: grpc
...and then restart the server.
There are multiple advantages of using gRPC gateway:
In general, if you are using the DiscoArt server behind a BFF (backend for frontend), or your DiscoArt server does not directly serve HTTP traffic from end-users, then you should use gRPC protocol.
To communicate with a gRPC DiscoArt server, one can use a Jina Client:
# !pip install jina
from jina import Client
c = Client(host='grpc://0.0.0.0:51001')
da = c.post(
'/create',
parameters={
'name_docarray': 'mydisco-123',
'text_prompts': [
'A beautiful painting of a singular lighthouse',
'yellow color scheme',
],
},
)
# check intermediate results
da = c.post('/result', parameters={'name_docarray': 'mydisco-123'})To use an existing Document/DocumentArray as init Document for create:
from jina import Client
c = Client(host='grpc://0.0.0.0:51001')
old_da = create(...)
da = c.post(
'/create',
old_da, # this can be a DocumentArray or a single Document
parameters={
'width_height': [1024, 768],
},
)This equals to run create(init_document=old_da, width_height=[1024, 768]) on the server. Note:
init_document.init_document is a DocumentArray, then the first Document in the array will be used as the init Document.Though not recommended, it is also possible to use Google Colab to host DiscoArt server. Please check out the following tutorials:
We provide a prebuilt Docker image for running DiscoArt out of the box. To update Docker image to latest version:
docker pull jinaai/discoart:latestThe default entrypoint is starting a Jupyter notebook
# docker build . -t jinaai/discoart # if you want to build yourself
docker run -p 51000:8888 -v $(pwd):/home/jovyan/ -v $HOME/.cache:/root/.cache --gpus all jinaai/discoartNow you can visit http://127.0.0.1:51000 to access the notebook
You can use it on Windows Subsystem for Linux (WSL), Check the official guide here.
# Make sure you install Windows 11 or Windows 10, version 21H2
docker run -p 8888:8888 -v $HOME/.cache:/root/.cache --gpus all jinaai/discoart# docker build . -t jinaai/discoart # if you want to build yourself
docker run --entrypoint "python" -p 51001:51001 -v $(pwd):/home/jovyan/ -v $HOME/.cache:/root/.cache --gpus all jinaai/discoart -m discoart serveYour DiscoArt server is now running at http://127.0.0.1:51001.
Docker images are built on every release, so one can lock it to a specific version, say 0.5.1:
docker run -p 51000:8888 -v $(pwd):/home/jovyan/ -v $HOME/.cache:/root/.cache --gpus all jinaai/discoart:0.5.1Next is create.
? If you are already a DD user: you are ready to go! There is no extra learning, DiscoArt respects the same parameter semantics as DD5.6. So just unleash your creativity! Read more about their differences here.
You can always do from discoart import cheatsheet; cheatsheet() to check all new/modified parameters.
? If you are a DALL·E Flow or new user: you may want to take step by step, as Disco Diffusion works in a very different way than DALL·E. It is much more advanced and powerful: e.g. Disco Diffusion can take weighted & structured text prompts; it can initialize from a image with controlled noise; and there are way more parameters one can tweak. Impatient prompt like "armchair avocado" will give you nothing but confusion and frustration. I highly recommend you to check out the following resources before trying your own prompt:
DiscoArt is backed by Jina AI and licensed under MIT License. We are actively hiring AI engineers, solution engineers to build the next neural search ecosystem in open-source.


