Awesome Attention Heads
vey on LLM attention heads
Important
About this repo. This is a platform to get the latest research on different kinds of LLM's Attention Heads. Also, we released a survey based on these fantastic works.
If you want to cite our work, here is our bibtex entry: CITATION.bib.
If you only want to see the related paper list, please jump directly to here.
If you want to contribute to this repo, refer to here.
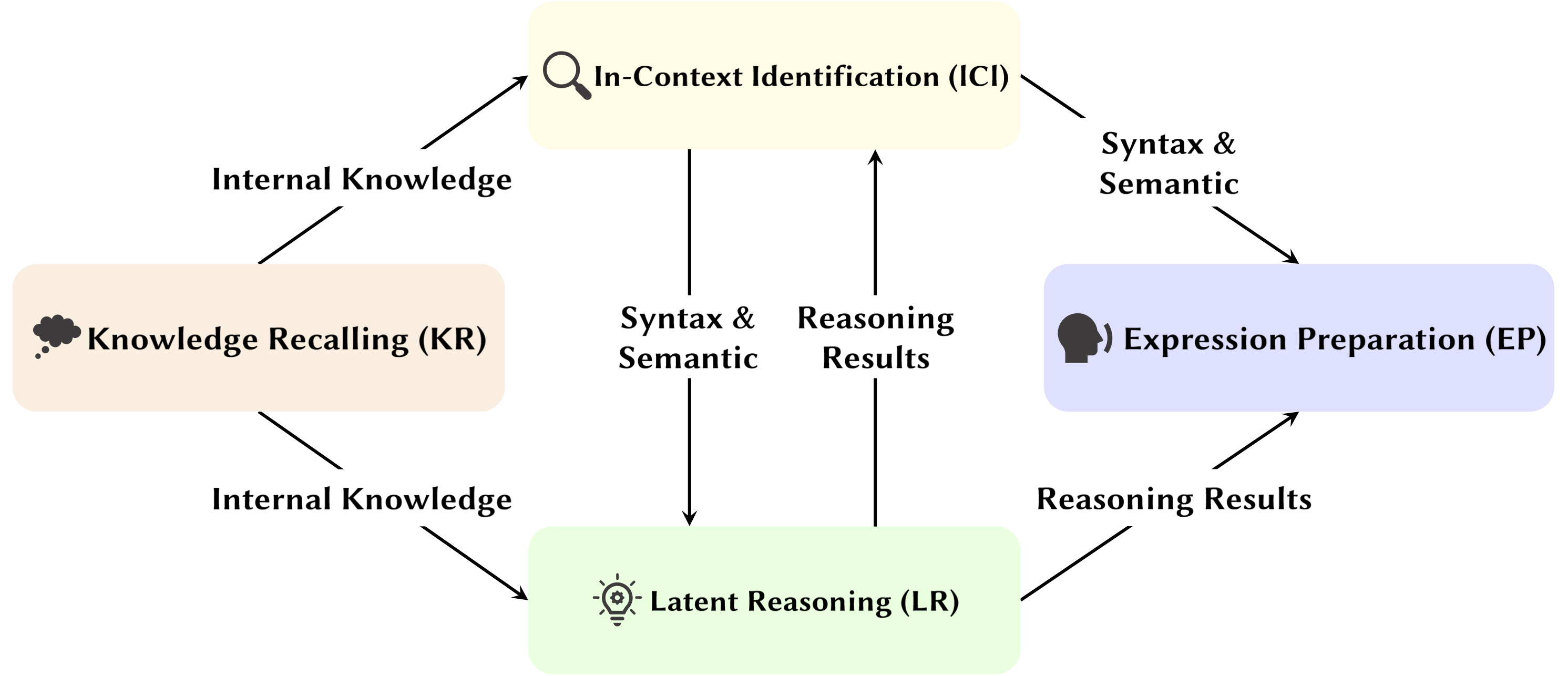
With the development of Large Language Model (LLMs), their underlying network structure, the Transformer, is being extensively studied. Researching the Transformer structure helps us enhance our understanding of this "black box" and improve model interpretability. Recently, there has been an increasing body of work suggesting that the model contains two distinct partitions: attention mechanisms used for behavior, inference, and analysis, and Feed-Forward Networks (FFN) for knowledge storage. The former is crucial for revealing the functional capabilities of the model, leading to a series of studies exploring various functions within attention mechanisms, which we have termed Attention Head Mining.
In this survey, we delve into the potential mechanisms of how attention heads in LLMs contribute to the reasoning process.
Highlights:
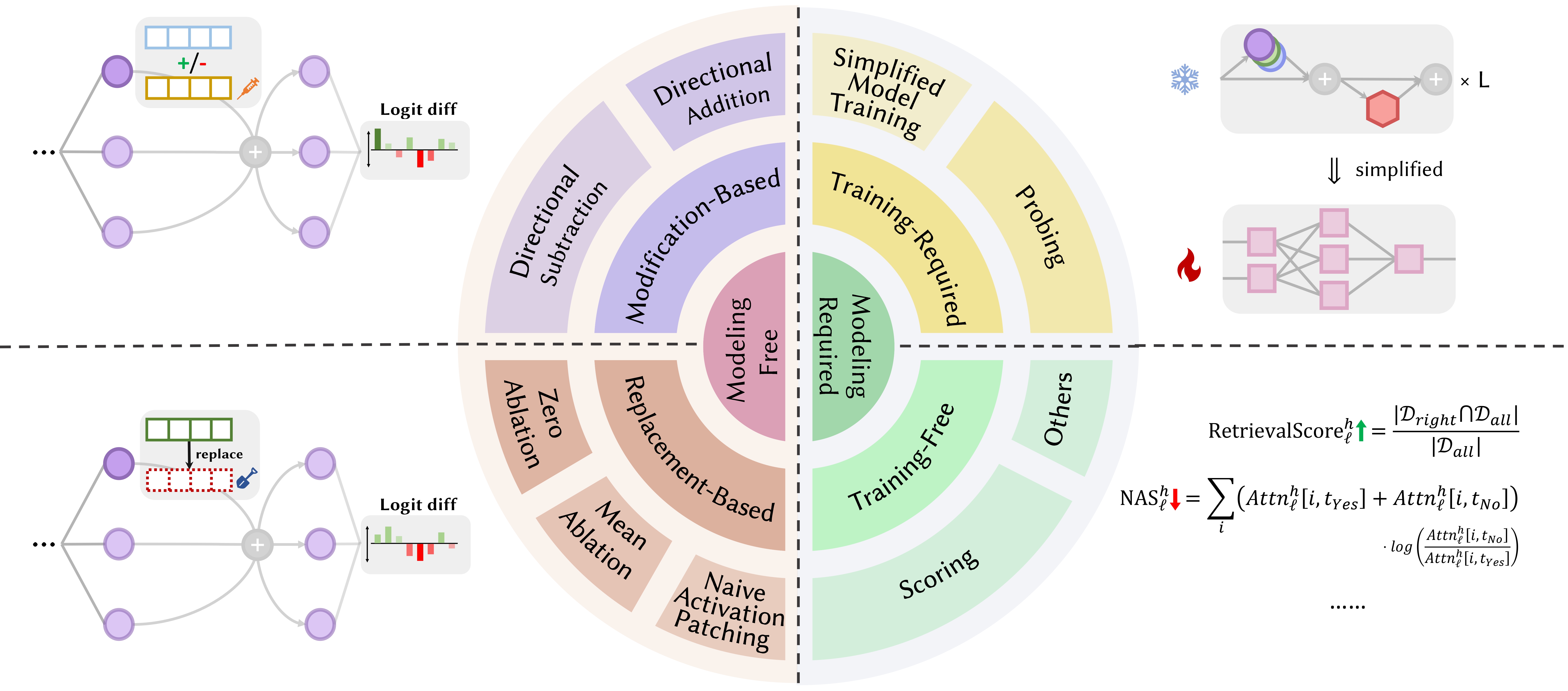
Papers below are ordered by publication date:
Year 2024
| Date | Paper & Summary | Tags | Links |
| 2024-11-15 | SEEKR: Selective Attention-Guided Knowledge Retention for Continual Learning of Large Language Models | ||
|
• Proposes SEEKR, a selective attention-guided knowledge retention method for continual learning in LLMs, focusing on key attention heads for efficient distillation. • Evaluated on continual learning benchmarks TRACE and SuperNI. • SEEKR achieved comparable or better performance with only 1% of replay data compared to other methods. |
|||
| 2024-11-06 | How Transformers Solve Propositional Logic Problems: A Mechanistic Analysis | ||
|
• Identifies specific attention circuits in transformers that solve propositional logic problems, focusing on "planning" and "reasoning" mechanisms. • Analyzed small transformers and Mistral-7B, using activation patching to uncover reasoning pathways. • Found distinct attention heads specializing in rule location, fact processing, and decision-making in logical reasoning. |
|||
| 2024-11-01 | Attention Tracker: Detecting Prompt Injection Attacks in LLMs | ||
|
• Proposed Attention Tracker, a simple yet effective training-free guard that detects prompt injection attacks based on identified Important Heads. • Identified the important heads using merely a small set of LLM-generated random sentences combined with a naive ignore attack. • Attention Tracker is effective on both small and large LMs, addressing a significant limitation of previous training-free detection methods. |
|||
| 2024-10-28 | Arithmetic Without Algorithms: Language Models Solve Math With a Bag of Heuristics | ||
|
• Identified a subset of the model (a circuit) that explains most of the model’s behavior for basic arithmetic logic and examine its functionality. • Analyzed attention patterns using two-operand arithmetic prompts with Arabic numerals and the four basic operators (+, −, ×, ÷). • For addition, subtraction, and division, 6 attention heads yield high faithfulness (97% on average), whereas multiplication requires 20 heads to exceed 90% faithfulness. |
|||
| 2024-10-21 | A Psycholinguistic Evaluation of Language Models' Sensitivity to Argument Roles | ||
|
• Observed subject head in a more generalized setting. • Analysed attention patterns under the condition of swap-arguments and replace-argument. • Despite being able to distinguish roles, models may struggle to use argument role information correctly, as the issue lies in how this information is encoded into verb representations, resulting in weaker role sensitivity. |
|||
| 2024-10-17 | Active-Dormant Attention Heads: Mechanistically Demystifying Extreme-Token Phenomena in LLMs | ||
|
• Demonstrated that extreme-token phenomena arise from an active-dormant mechanism in attention heads, coupled with a mutual-reinforcement mechanism during pretraining. • Using simple transformers trained on the Bigram-Backcopy (BB) task to analyze extreme token phenomena and extend it to pre-trained LLMs. • Many of the static and dynamic properties of extreme-token phenomena predicted by the BB task align with observations in pretrained LLMs. |
|||
| 2024-10-17 | On the Role of Attention Heads in Large Language Model Safety | ||
|
• Proposed a novel metric which tailored for multi-head attention, the Safety Head ImPortant Score (Ships), to assess the individual heads’ contributions to model safety. • Conducted analyses on the functionality of these safety attention heads, exploring their characteristics and mechanisms. • Certain attention heads are crucial for safety, safety heads overlap across fine-tuned models, and ablating these heads minimally impacts helpfulness. |
|||
| 2024-10-14 | DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads | ||
|
• Introduced DuoAttention, a framework that reduces both LLM’s decoding and pre-filling memory and latency without compromising its long-context abilities, based on the discovery of Retrieval Heads and Streaming Heads within LLM. • Test the framework's impact on LLM’s performance in both short-context and long-context tasks, as well as its inference efficiency. • By applying a full KV cache only to retrieval heads, DuoAttention significantly reduces memory usage and latency for both decoding and pre-filling in long-context applications. |
|||
| 2024-10-14 | Locking Down the Finetuned LLMs Safety | ||
|
• Introduced SafetyLock, a novel and efficient method for maintaining the safety of fine-tuned large
language models across various risk levels and attack scenarios, based on the discovery of Safety Heads within LLM. • Evaluate the effectiveness of the SafetyLock in enhancing model safety and inference efficiency. • By applying intervention vectors to safety heads, SafetyLock can modify the model’s internal activations towards harmlessness during inference, achieving precise safety alignment with minimal impact on response. |
|||
| 2024-10-11 | The Same But Different: Structural Similarities and Differences in Multilingual Language Modeling | ||
|
• Conducted an in-depth study of the specific components that multilingual models rely on when performing tasks that require language-specific morphological processes. • Investigate the functional differences of internal model components when performing tasks in English and Chinese. • Copy head has a similarly high activation frequency in both languages whereas the past tense head is only frequently activated in English. |
|||
| 2024-10-08 | Round and Round We Go! What makes Rotary Positional Encodings useful? | ||
|
• Provided an in-depth analysis of the internals of a trained Gemma 7B model to understand how RoPE is being used at a mechanical level. • Understood the usage of different frequencies in the queries and keys. • Found that the highest frequencies in RoPE are cleverly used by Gemma 7B to construct special ‘positional’ attention heads(Diagonal heads, Previous-token head), while the low frequencies are used by Apostrophe head. |
|||
| 2024-10-06 | Revisiting In-context Learning Inference Circuit in Large Language Models | ||
|
• Proposed a comprehensive 3-step inference circuit to characterize the inference process of ICL. • Divide ICL into three stages: Summarize, Semantics Merge, and Feature Retrieval and Copy, analyzing the role each stage plays in ICL and its operational mechanism. • Found that before Induction heads, Forerunner Token Heads first merge the demonstration text representations from the forerunner token into their corresponding label tokens, selectively based on the compatibility between the demonstration and label semantics. |
|||
| 2024-10-01 | Sparse Attention Decomposition Applied to Circuit Tracing | ||
|
• Introduces Sparse Attention Decomposition, using SVD on attention head matrices to trace communication paths in GPT-2 models. • Applied to circuit tracing in GPT-2 small for the Indirect Object Identification (IOI) task. • Identified sparse, functionally significant communication signals between attention heads, improving interpretability. |
|||
| 2024-09-09 | Unveiling Induction Heads: Provable Training Dynamics and Feature Learning in Transformers | ||
|
• The paper introduces a generalized induction head mechanism, explaining how transformer components collaborate to perform in-context learning (ICL) on n-gram Markov chains. • It analyzes a two-attention-layer transformer with gradient flow to predict tokens in Markov chains. • Gradient flow converges, enabling ICL through a learned feature-based induction head mechanism. |
|||
| 2024-08-16 | A Mechanistic Interpretation of Syllogistic Reasoning in Auto-Regressive Language Models | ||
|
• The study introduces a mechanistic interpretation of syllogistic reasoning in LMs, identifying content-independent reasoning circuits. • Circuit discovery for reasoning and investigating belief bias contamination in attention heads. • Identified a necessary reasoning circuit transferable across syllogistic schemes, but susceptible to contamination by pre-trained world knowledge. |
|||
| 2024-08-01 | Enhancing Semantic Consistency of Large Language Models through Model Editing: An Interpretability-Oriented Approach | ||
|
• Introduces a cost-effective model editing approach focusing on attention heads to enhance semantic consistency in LLMs without extensive parameter changes. • Analyzed attention heads, injected biases, and tested on NLU and NLG datasets. • Achieved notable improvements in semantic consistency and task performance, with strong generalization across additional tasks. |
|||
| 2024-07-31 | Correcting Negative Bias in Large Language Models through Negative Attention Score Alignment | ||
|
• Introduced Negative Attention Score (NAS) to quantify and correct negative bias in language models. • Identified negatively biased attention heads and proposed Negative Attention Score Alignment (NASA) for fine-tuning. • NASA effectively reduced the precision-recall gap while preserving generalization in binary decision tasks. |
|||
| 2024-07-29 | Detecting and Understanding Vulnerabilities in Language Models via Mechanistic Interpretability | ||
|
• Introduces a method using Mechanistic Interpretability (MI) to detect and understand vulnerabilities in LLMs, particularly adversarial attacks. • Analyzes GPT-2 Small for vulnerabilities in predicting 3-letter acronyms. • Successfully identifies and explains specific vulnerabilities in the model related to the task. |
|||
| 2024-07-22 | RazorAttention: Efficient KV Cache Compression Through Retrieval Heads | ||
|
• Introduced RazorAttention, a training-free KV cache compression technique using retrieval heads and compensation tokens to preserve critical token information. • Evaluated RazorAttention on large language models (LLMs) for efficiency. • Achieved over 70% KV cache size reduction with no noticeable performance impact. |
|||
| 2024-07-21 | Answer, Assemble, Ace: Understanding How Transformers Answer Multiple Choice Questions | ||
|
• The paper introduces vocabulary projection and activation patching to localize hidden states that predict the correct MCQA answers. • Identified key attention heads and layers responsible for answer selection in transformers. • Middle-layer attention heads are crucial for accurate answer prediction, with a sparse set of heads playing unique roles. |
|||
| 2024-07-09 | Induction Heads as an Essential Mechanism for Pattern Matching in In-context Learning | ||
|
• The article identifies induction heads as crucial for pattern matching in in-context learning (ICL). • Evaluated Llama-3-8B and InternLM2-20B on abstract pattern recognition and NLP tasks. • Ablating induction heads reduces ICL performance by up to ~32%, bringing it close to random for pattern recognition. |
|||
| 2024-07-02 | Interpreting Arithmetic Mechanism in Large Language Models through Comparative Neuron Analysis | ||
|
• Introduces Comparative Neuron Analysis (CNA) to map arithmetic mechanisms in attention heads of large language models. • Analyzed arithmetic ability, model pruning for arithmetic tasks, and model editing to reduce gender bias. • Identified specific neurons responsible for arithmetic, enabling performance improvements and bias mitigation through targeted neuron manipulation. |
|||
| 2024-07-01 | Steering Large Language Models for Cross-lingual Information Retrieval | ||
|
• Introduces Activation Steered Multilingual Retrieval (ASMR), using steering activations to guide LLMs for improved cross-lingual information retrieval. • Identified attention heads in LLMs affecting accuracy and language coherence, and applied steering activations. • ASMR achieved state-of-the-art performance on CLIR benchmarks like XOR-TyDi QA and MKQA. |
|||
| 2024-06-25 | How Transformers Learn Causal Structure with Gradient Descent | ||
|
• Provided an explanation of how transformers learn causal structures through gradient-based training algorithms. • Analyzed the performance of two-layer transformers on a task called random sequences with causal structure. • Gradient descent on a simplified two-layer transformer learns to solve this task by encoding the latent causal graph in the first attention layer. As a special case, when sequences are generated from in-context Markov chains, transformers learn to develop an induction head. |
|||
| 2024-06-21 | MoA: Mixture of Sparse Attention for Automatic Large Language Model Compression | ||
|
• The paper introduces Mixture of Attention (MoA), which tailors distinct sparse attention configurations for different heads and layers, optimizing memory, throughput, and accuracy-latency trade-offs. • MoA profiles models, explores attention configurations, and improves LLM compression. • MoA increases effective context length by 3.9×, while reducing GPU memory usage by 1.2-1.4×. |
|||
| 2024-06-19 | On the Difficulty of Faithful Chain-of-Thought Reasoning in Large Language Models | ||
|
• Introduced novel strategies for in-context learning, fine-tuning, and activation editing to improve Chain-of-Thought (CoT) reasoning faithfulness in LLMs. • Tested these strategies across multiple benchmarks to evaluate their effectiveness. • Found only limited success in enhancing CoT faithfulness, highlighting the challenge in achieving truly faithful reasoning in LLMs. |
|||
| 2024-06-04 | Iteration Head: A Mechanistic Study of Chain-of-Thought | ||
|
• Introduces "iteration heads," specialized attention heads that enable iterative reasoning in transformers for Chain-of-Thought (CoT) tasks. • Analysis of attention mechanisms, tracking CoT emergence, and testing CoT skills' transferability between tasks. • Iteration heads effectively support CoT reasoning, improving model interpretability and task performance. |
|||
| 2024-06-03 | LoFiT: Localized Fine-tuning on LLM Representations | ||
|
• Introduces Localized Fine-tuning on LLM Representations (LoFiT), a two-step framework to identify important attention heads of a given task and learn task-specific offset vectors to intervene on the representations of the identified heads. • Identified sparse sets of important attention heads for improving downstream accuracy on truthfulness and reasoning. • LoFiT outperformed other representation intervention methods and achieved comparable performance to PEFT methods on TruthfulQA, CLUTRR, and MQuAKE, despite only intervening on 10% of the total attention heads in LLMs. |
|||
| 2024-05-28 | Knowledge Circuits in Pretrained Transformers | ||
|
• Introduced "knowledge circuits" in transformers, revealing how specific knowledge is encoded through interaction among attention heads, relation heads, and MLPs. • Analyzed GPT-2 and TinyLLAMA to identify knowledge circuits; evaluated knowledge editing techniques. • Demonstrated how knowledge circuits contribute to model behaviors like hallucinations and in-context learning. |
|||
| 2024-05-23 | Linking In-context Learning in Transformers to Human Episodic Memory | ||
|
• Links in-context learning in Transformer models to human episodic memory, highlighting similarities between induction heads and the contextual maintenance and retrieval (CMR) model. • Analysis of Transformer-based LLMs to demonstrate CMR-like behavior in attention heads. • CMR-like heads emerge in intermediate layers, mirroring human memory biases. |
|||
| 2024-05-07 | How does GPT-2 Predict Acronyms? Extracting and Understanding a Circuit via Mechanistic Interpretability | ||
|
• First mechanistic interpretability study on GPT-2 for predicting multi-token acronyms using attention heads. • Identified and interpreted a circuit of 8 attention heads responsible for acronym prediction. • Demonstrated that these 8 heads (~5% of total) concentrate the acronym prediction functionality. |
|||
| 2024-05-02 | Interpreting and Improving Large Language Models in Arithmetic Calculation | ||
|
• Introduces a detailed investigation of LLMs' inner mechanisms through mathematical tasks, following the 'identify-analyze-finetune' pipeline. • Analyzed the model's ability to perform arithmetic tasks involving two operands, such as addition, subtraction, multiplication, and division. • Found that LLMs frequently involve a small fraction (< 5%) of attention heads, which play a pivotal role in focusing on operands and operators during calculation processes. |
|||
| 2024-05-02 | What needs to go right for an induction head? A mechanistic study of in-context learning circuits and their formation | ||
|
• Introduced an optogenetics-inspired causal framework to study induction head (IH) formation in transformers. • Analyzed IH emergence in transformers using synthetic data and identified three underlying subcircuits responsible for IH formation. • Discovered that these subcircuits interact to drive IH formation, coinciding with a phase change in model loss. |
|||
| 2024-04-24 | Retrieval Head Mechanistically Explains Long-Context Factuality | ||
|
• Identified "retrieval heads" in transformer models responsible for retrieving information across long contexts. • Systematic investigation of retrieval heads across various models, including analysis of their role in chain-of-thought reasoning. • Pruning retrieval heads leads to hallucination, while pruning non-retrieval heads doesn't affect retrieval ability. |
|||
| 2024-03-27 | Non-Linear Inference Time Intervention: Improving LLM Truthfulness | ||
|
• Introduced Non-Linear Inference Time Intervention (NL-ITI), enhancing LLM truthfulness by multi-token probing and intervention without fine-tuning. • Evaluated NL-ITI on multiple-choice datasets, including TruthfulQA. • Achieved a 16% relative improvement in MC1 accuracy on TruthfulQA over baseline ITI. |
|||
| 2024-02-28 | How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning | ||
|
• Provided an in-depth analysis of CoT-mediated reasoning in LLMs in terms of the neural functional components. • Dissected CoT-based reasoning on fictional reasoning as a composition of a fixed number of subtasks that require decision-making, copying, and inductive reasoning, analyzing their mechanism separately. • Found that attention heads perform information movement between ontologically related (or negatively related) tokens, resulting in distinctly identifiable representations for these token pairs. |
|||
| 2024-02-28 | Cutting Off the Head Ends the Conflict: A Mechanism for Interpreting and Mitigating Knowledge Conflicts in Language Models | ||
|
• Introduces the PH3 method to prune conflicting attention heads, mitigating knowledge conflicts in language models without parameter updates. • Applied PH3 to control LMs' reliance on internal memory vs. external context and tested its effectiveness on open-domain QA tasks. • PH3 improved internal memory usage by 44.0% and external context usage by 38.5%. |
|||
| 2024-02-27 | Information Flow Routes: Automatically Interpreting Language Models at Scale | ||
|
• Introduces "Information Flow Routes" using attribution for graph-based interpretation of language models, avoiding activation patching. • Experiments with Llama 2, identifying key attention heads and behavior patterns across different domains and tasks. • Uncovered specialized model components; identified consistent roles for attention heads, such as handling tokens of the same part of speech. |
|||
| 2024-02-20 | Identifying Semantic Induction Heads to Understand In-Context Learning | ||
|
• Identifies and studies "semantic induction heads" in large language models (LLMs) that correlate with in-context learning abilities. • Analyzed attention heads for encoding syntactic dependencies and knowledge graph relations. • Certain attention heads enhance output logits by recalling relevant tokens, crucial for understanding in-context learning in LLMs. |
|||
| 2024-02-16 | The Evolution of Statistical Induction Heads: In-Context Learning Markov Chains | ||
|
• Introduces a Markov Chain sequence modeling task to analyze how in-context learning (ICL) capabilities emerge in transformers, forming "statistical induction heads." • Empirical and theoretical investigation of multi-phase training in transformers on Markov Chain tasks. • Demonstrates phase transitions from unigram to bigram predictions, influenced by transformer layer interactions. |
|||
| 2024-02-11 | Summing Up the Facts: Additive Mechanisms Behind Factual Recall in LLMs | ||
|
• Identifies and explains the "additive motif" in factual recall, where LLMs use multiple independent mechanisms that constructively interfere to recall facts. • Extended direct logit attribution to analyze attention heads and unpacked the behavior of mixed heads. • Demonstrated that factual recall in LLMs results from the sum of multiple, independently insufficient contributions. |
|||
| 2024-02-05 | How do Large Language Models Learn In-Context? Query and Key Matrices of In-Context Heads are Two Towers for Metric Learning | ||
|
• Introduces the concept that query and key matrices in in-context heads operate as "two towers" for metric learning, facilitating similarity computation between label features. • Analyzed in-context learning mechanisms; identified specific attention heads crucial for ICL. • Reduced ICL accuracy from 87.6% to 24.4% by intervening in only 1% of these heads. |
|||
| 2024-01-23 | In-Context Language Learning: Architectures and Algorithms | ||
|
• Introduction of "n-gram heads," specialized Transformer attention heads, enhancing in-context language learning (ICLL) through input-conditional token prediction. • Evaluated neural models on regular languages from random finite automata. • Hard-wiring n-gram heads improved perplexity by 6.7% on the SlimPajama dataset. |
|||
| 2024-01-16 | The mechanistic basis of data dependence and abrupt learning in an in-context classification task | ||
|
• The paper models the mechanistic basis of in-context learning (ICL) via the abrupt formation of induction heads in attention-only networks. • Simulated ICL tasks using simplified input data and a two-layer attention-based network. • Induction head formation drives the abrupt transition to ICL, traced through nested non-linearities. |
|||
| 2024-01-16 | Circuit Component Reuse Across Tasks in Transformer Language Models | ||
|
• The paper demonstrates that specific circuits in GPT-2 can generalize across different tasks, challenging the notion that such circuits are task-specific. • It examines the reuse of circuits from the Indirect Object Identification (IOI) task in the Colored Objects task. • Adjusting four attention heads boosts accuracy from 49.6% to 93.7% in the Colored Objects task. |
|||
| 2024-01-16 | Successor Heads: Recurring, Interpretable Attention Heads In The Wild | ||
|
• The paper introduces "Successor Heads," attention heads in LLMs that increment tokens with natural orderings, like days or numbers. • It analyzes the formation of successor heads across various model sizes and architectures, such as GPT-2 and Llama-2. • Successor heads are found in models ranging from 31M to 12B parameters, revealing abstract, recurring numeric representations. |
|||
| 2024-01-16 | Function Vectors in Large Language Models | ||
|
• The article introduces "Function Vectors (FVs)," compact, causal representations of tasks within autoregressive transformer models. • FVs were tested across diverse in-context learning (ICL) tasks, models, and layers. • FVs can be summed to create vectors that trigger new, complex tasks, demonstrating internal vector composition. |
|||
| Date | Paper & Summary | Tags | Links |
| 2023-12-23 | Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level | ||
|
• Investigated how early MLP layers in Pythia 2.8B encode factual recall using distributed circuits, focusing on superposition and multi-token embeddings. • Explored factual lookup in MLP layers, tested hypotheses on detokenization and hashing mechanisms. • Factual recall functions like a distributed look-up table without easily interpretable internal mechanisms. |
|||
| 2023-11-07 | Towards Interpretable Sequence Continuation: Analyzing Shared Circuits in Large Language Models | ||
|
• Demonstrated the existence of shared circuits for similar sequence continuation tasks. • Analyzed and compared circuits for similar sequence continuation tasks, which include increasing sequences of Arabic numerals, number words, and months. • Semantically related sequences rely on shared circuit subgraphs with analogous roles and the finding of similar sub-circuits across models with analogous functionality. |
|||
| 2023-10-23 | Linear Representations of Sentiment in Large Language Models | ||
|
• The paper identifies a linear direction in activation space that captures sentiment representation in Large Language Models (LLMs). • They isolated this sentiment direction and tested it on tasks including Stanford Sentiment Treebank. • Ablating this sentiment direction leads to a 76% reduction in classification accuracy, highlighting its importance. |
|||
| 2023-10-06 | Copy Suppression: Comprehensively Understanding an Attention Head | ||
|
• The paper introduces the concept of copy suppression in a GPT-2 Small attention head (L10H7), which reduces naive token copying, enhancing model calibration. • The paper investigates and explains the mechanism of copy suppression and its role in self-repair. • 76.9% of L10H7's impact in GPT-2 Small is explained, making it the most comprehensive description of an attention head's role. |
|||
| 2023-09-22 | Inference-Time Intervention: Eliciting Truthful Answers from a Language Model | ||
|
• Introduced Inference-Time Intervention (ITI) to enhance LLM truthfulness by adjusting model activations in select attention heads. • Improved LLaMA model performance on the TruthfulQA benchmark. • ITI increased Alpaca model's truthfulness from 32.5% to 65.1%. |
|||
| 2023-09-22 | Birth of a Transformer: A Memory Viewpoint | ||
|
• The paper presents a memory-based perspective on transformers, highlighting associative memories in weight matrices and their gradient-driven learning. • Empirical analysis of training dynamics on a simplified transformer model with synthetic data. • Discovery of rapid global bigram learning and the slower emergence of an "induction head" for in-context bigrams. |
|||
| 2023-09-13 | Sudden Drops in the Loss: Syntax Acquisition, Phase Transitions, and Simplicity Bias in MLMs | ||
|
• Identifies Syntactic Attention Structure (SAS) as a naturally emerging property in masked language models (MLMs) and its role in syntax acquisition. • Analyzes SAS during training and manipulates it to study its causal effect on grammatical capabilities. • SAS is necessary for grammar development, but briefly suppressing it improves model performance. |
|||
| 2023-07-18 | Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla | ||
|
• Scalable circuit analysis applied to a 70B Chinchilla language model for understanding multiple-choice question answering. • Logit attribution, attention pattern visualization, and activation patching to identify and categorize key attention heads. • Identified "Nth item in an enumeration" feature in attention heads, though it's only a partial explanation. |
|||
| 2023-02-02 | Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small | ||
|
• The paper introduces a detailed explanation of how GPT-2 small performs indirect object identification (IOI) using a large circuit involving 28 attention heads grouped into 7 classes. • They reverse-engineered the IOI task in GPT-2 small using causal interventions and projections. • The study demonstrates that mechanistic interpretability of large language models is feasible. |
|||
| Date | Paper & Summary | Tags | Links |
| 2022-03-08 | In-context Learning and Induction Heads | ||
|
• The paper identifies "induction heads" in Transformer models, which enable in-context learning by recognizing and copying patterns in sequences. • Analyzes attention patterns and induction heads across various layers in different Transformer models. • Found that induction heads are crucial for enabling Transformers to generalize and perform in-context learning tasks effectively. |
|||
| 2021-12-22 | A Mathematical Framework for Transformer Circuits | ||
|
• Introduces a mathematical framework to reverse-engineer small attention-only transformers, focusing on understanding attention heads as independent, additive components. • Analyzed zero, one, and two-layer transformers to identify the role of attention heads in information movement and composition. • Discovered "induction heads," crucial for in-context learning in two-layer transformers. |
|||
| 2021-05-18 | The Heads Hypothesis: A Unifying Statistical Approach Towards Understanding Multi-Headed Attention in BERT | ||
|
• The paper proposes a novel method called "Sparse Attention" that reduces the computational complexity of attention mechanisms by selectively focusing on important tokens. • The method was evaluated on machine translation and text classification tasks. • The sparse attention model achieves comparable accuracy to dense attention while significantly reducing computational cost. |
|||
| 2021-04-01 | Have Attention Heads in BERT Learned Constituency Grammar? | ||
|
• The study introduces a syntactic distance method to analyze constituency grammar in BERT and RoBERTa attention heads. • Constituency grammar was extracted and analyzed pre- and post-fine-tuning on SMS and NLI tasks. • NLI tasks increase constituency grammar inducing ability, while SMS tasks decrease it in upper layers. |
|||
| 2019-11-27 | Do Attention Heads in BERT Track Syntactic Dependencies? | ||
|
• The paper investigates whether individual attention heads in BERT capture syntactic dependencies, using attention weights to extract dependency relations. • Analyzed BERT's attention heads using maximum attention weights and maximum spanning trees, comparing them to Universal Dependency trees. • Some attention heads track specific syntactic dependencies better than baselines, but no head performs holistic parsing significantly better. |
|||
| 2019-11-01 | Adaptively Sparse Transformers | ||
|
• Introduced the adaptively sparse Transformer using alpha-entmax to allow flexible, context-dependent sparsity in attention heads. • Applied to machine translation datasets to assess interpretability and head diversity. • Achieved diverse attention distributions and improved interpretability without compromising accuracy. |
|||
| 2019-08-01 | What does BERT look at? An Analysis of BERT’s Attention | ||
|
• The paper introduces methods to analyze BERT's attention mechanisms, revealing patterns that align with linguistic structures like syntax and coreference. • Analysis of attention heads, identification of syntactic and coreferential patterns, and development of an attention-based probing classifier. • BERT's attention heads capture substantial syntactic information, particularly in tasks like identifying direct objects and coreference. |
|||
| 2019-07-01 | Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned | ||
|
• The paper introduces a novel pruning method for multi-head self-attention that selectively removes less important heads without major performance loss. • Analysis of individual attention heads, identification of their specialized roles, and application of a pruning method on the Transformer model. • Pruning 38 out of 48 heads in the encoder led to only a 0.15 BLEU score drop. |
|||
| 2018-11-01 | An Analysis of Encoder Representations in Transformer-Based Machine Translation | ||
|
• This paper analyzes the internal representations of Transformer encoder layers, focusing on syntactic and semantic information learned by self-attention heads. • Probing tasks, dependency relation extraction, and a transfer learning scenario. • Lower layers capture syntax, while higher layers encode more semantic information. |
|||
| 2016-03-21 | Incorporating Copying Mechanism in Sequence-to-Sequence Learning | ||
|
• Introduces a copying mechanism into sequence-to-sequence models to allow direct copying of input tokens, improving handling of rare words. • Applied to machine translation and summarization tasks. • Achieved substantial improvements in translation accuracy, especially on rare word translation, compared to standard sequence-to-sequence models. |
|||
Issue Template:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


