AudioNotes
1.0.0
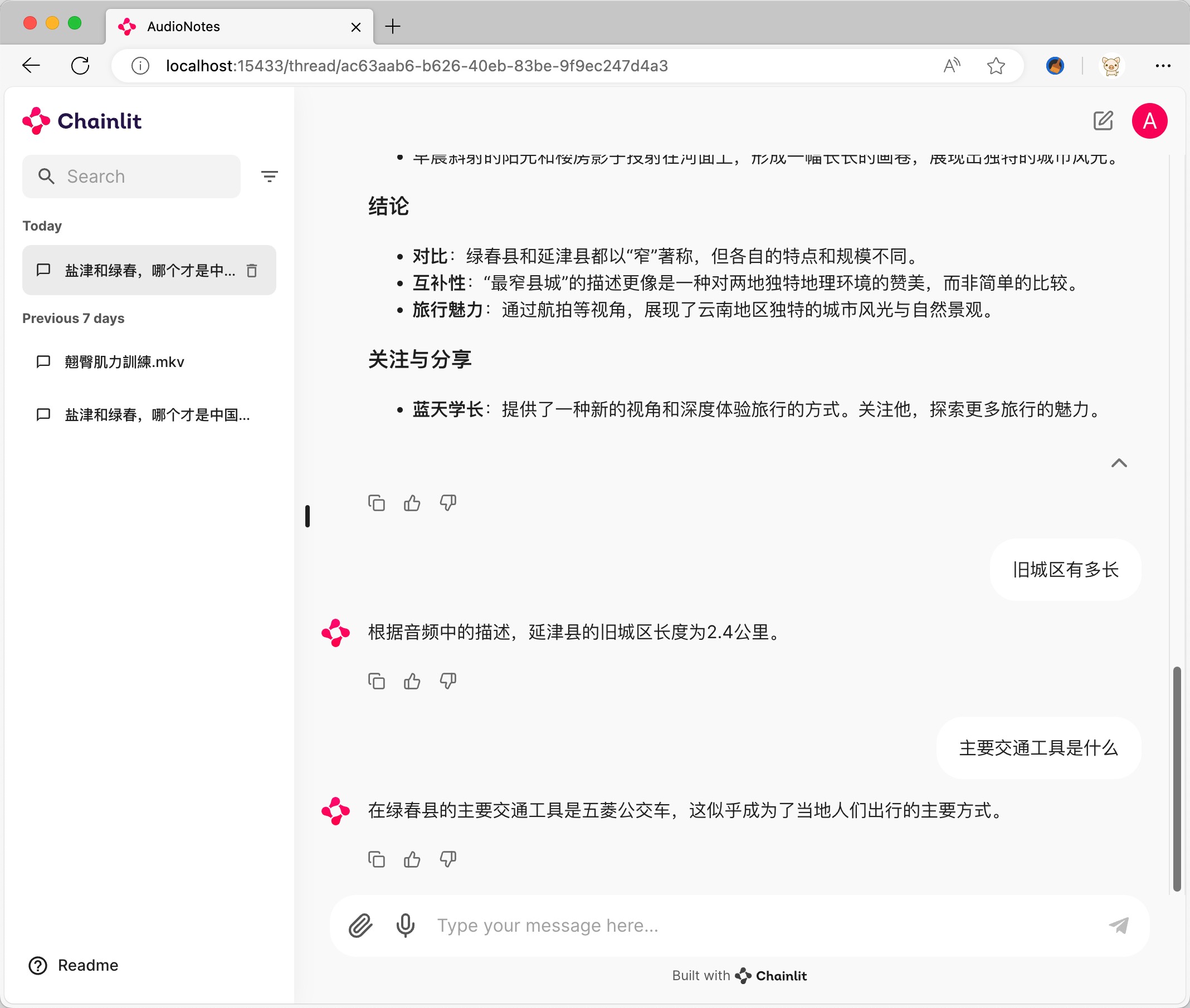
It can quickly extract the content of audio and video, and call a large model to organize it into a structured markdown note for easy and quick reading.
FunASR: https://github.com/modelscope/FunASR
Qwen2: https://ollama.com/library/qwen2
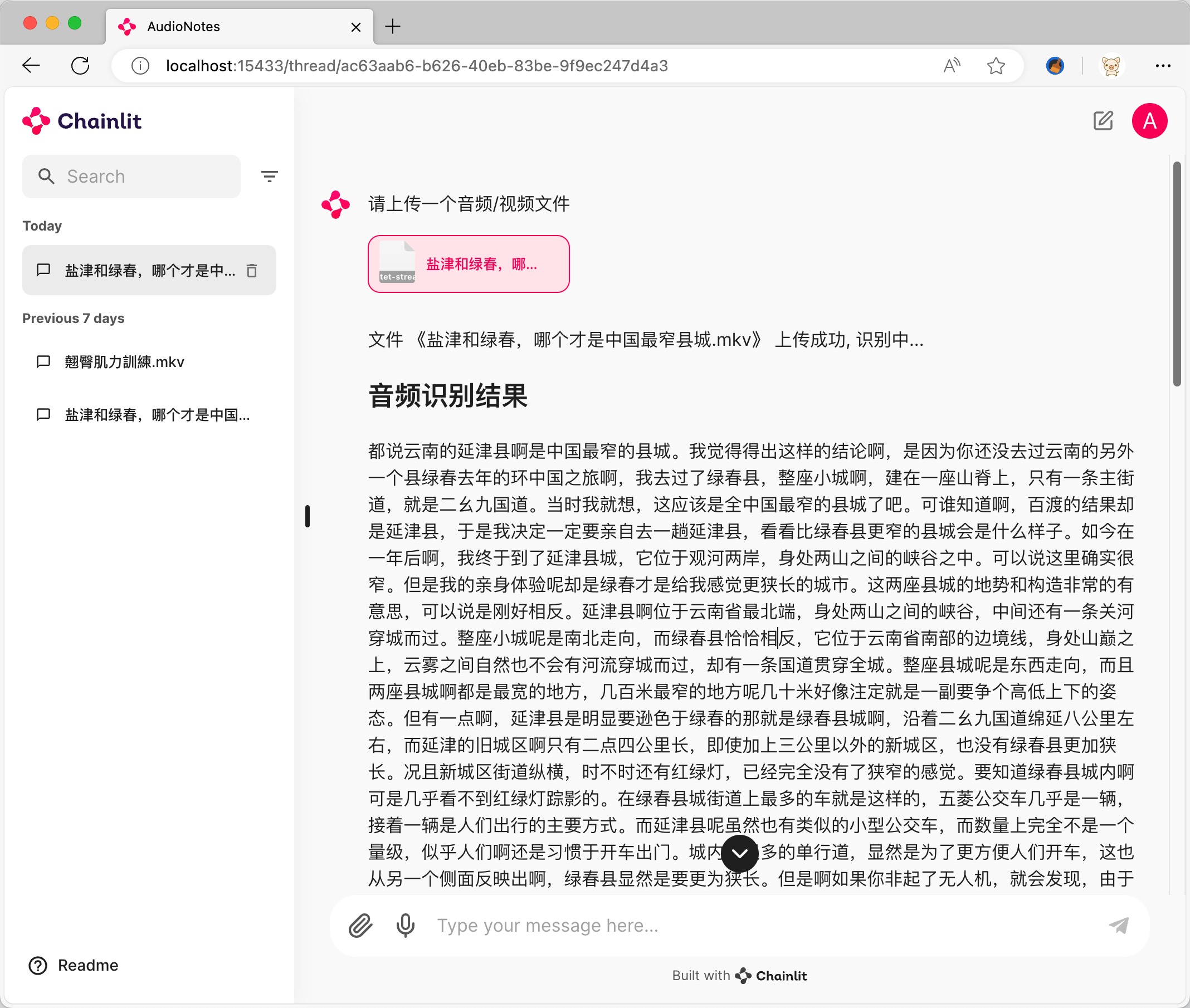
Download the Ollama installation package corresponding to the system and install it.
https://ollama.com/download
I take阿里的千问2 7b as an example https://ollama.com/library/qwen2
ollama pull qwen2:7bThere are two deployment methods, one is to deploy using Docker and the other is to deploy locally.
curl -fsSL https://github.com/harry0703/AudioNotes/raw/main/docker-compose.yml -o docker-compose.yml
docker-compose upAfter docker starts, visit http://localhost:15433/
The login account is admin and the password is admin (can be modified in the docker-compose.yml file)
An accessible postgresql database is required
conda create -n AudioNotes python=3.10 -y
conda activate AudioNotes
git clone https://github.com/harry0703/AudioNotes.git
cd AudioNotes
pip install -r requirements.txt Rename .env.example to .env and modify related configuration information
chainlit run main.pyAfter the service is started, visit http://localhost:8000/
The login account is admin and the password is admin (can be modified in the .env file)


