gcp_cloud_status_dataset
1.0.0
This is a simple Bigquery Dataset which contains Google Cloud Service Health (CSH) events.
You can use this to query for events and filter the incidents you are interested.
Its triggered every minute. If there is no update to an existing outage or a new outage not detected, no new row is inserted.
You can also use this together with the Asset Inventory API to correlate events in a given location/region with the assets that maybe impacted.
Anyway, the existing CSH dashboard provides the data in various formats like RSS and JSON and while you can issue simple queries and filters using jq
curl -s https://status.cloud.google.com/incidents.json | jq -r '.[] | select(.service_name == "Google Compute Engine")'however, its just not in a form thats easy to use.
So, instead of raw json, how about in a bigquery table you or anyone can use...
Here's the dataset:
To use this, first add the following project to the UI gcp-status-log. Once thats done, any query you issue will use the this dataset but bill your project for your own usage.
(i.,e i'm just providing the data...the query you run is what you'll pay for)
NOTE: this repository, dataset and code is NOT supported by google. caveat emptor
bq query --nouse_legacy_sql '
SELECT
DISTINCT(id), service_name,severity,external_desc, begin,`end` , modified
FROM
gcp-status-log.status_dataset.status
WHERE
service_name = "Google Compute Engine"
ORDER BY
modified
'
+----------------------+-----------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+---------------------+---------------------+---------------------+
| id | service_name | severity | external_desc | begin | end | modified |
+----------------------+-----------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+---------------------+---------------------+---------------------+
| pxD6QciVMd9gLQGcREbV | Google Compute Engine | medium | Requests to and from Google Compute Instances in us-west2 may see increase traffic loss when using the instance's public IP | 2021-05-05 02:11:10 | 2021-05-05 04:54:57 | 2021-05-05 04:54:57 |
| LGFBxyLwbh92E47fAzJ5 | Google Compute Engine | medium | Mutliregional Price for E2 Free Tier core is set incorrectly | 2021-08-01 07:00:00 | 2021-08-04 23:18:00 | 2021-08-05 17:35:12 |
| gwKjX9Lukav15SaFPbBF | Google Compute Engine | medium | us-central1, europe-west1, us-west1, asia-east1: Issue with Local SSDs on Google Compute Engine. | 2021-09-01 02:35:00 | 2021-09-03 03:55:00 | 2021-09-07 21:39:46 |
| rjF86FbooET3FDpMV9w1 | Google Compute Engine | medium | Increased VM failure rates in a subset of Google Cloud zones | 2021-09-17 15:00:00 | 2021-09-17 18:25:00 | 2021-09-20 23:33:53 |
| ZoUf49v2qbJ9xRK63kaM | Google Compute Engine | medium | Some Users might have received credit cards deemed invalid email erroneously. | 2021-11-13 07:14:48 | 2021-11-13 08:29:30 | 2021-11-13 08:29:30 |
| SjJ3FN51MAEJy7cZmoss | Google Compute Engine | medium | Global: pubsub.googleapis.com autoscaling not worked as expected | 2021-12-07 09:56:00 | 2021-12-14 00:59:00 | 2021-12-14 19:59:08 |
+----------------------+-----------------------+----------+-----------------------------------------------------------------------------------------------------------------------------+---------------------+---------------------+---------------------+
...and thats the limit of my skills with BQ. If you have any suggested queries you wrote, pls send me a note in github issues
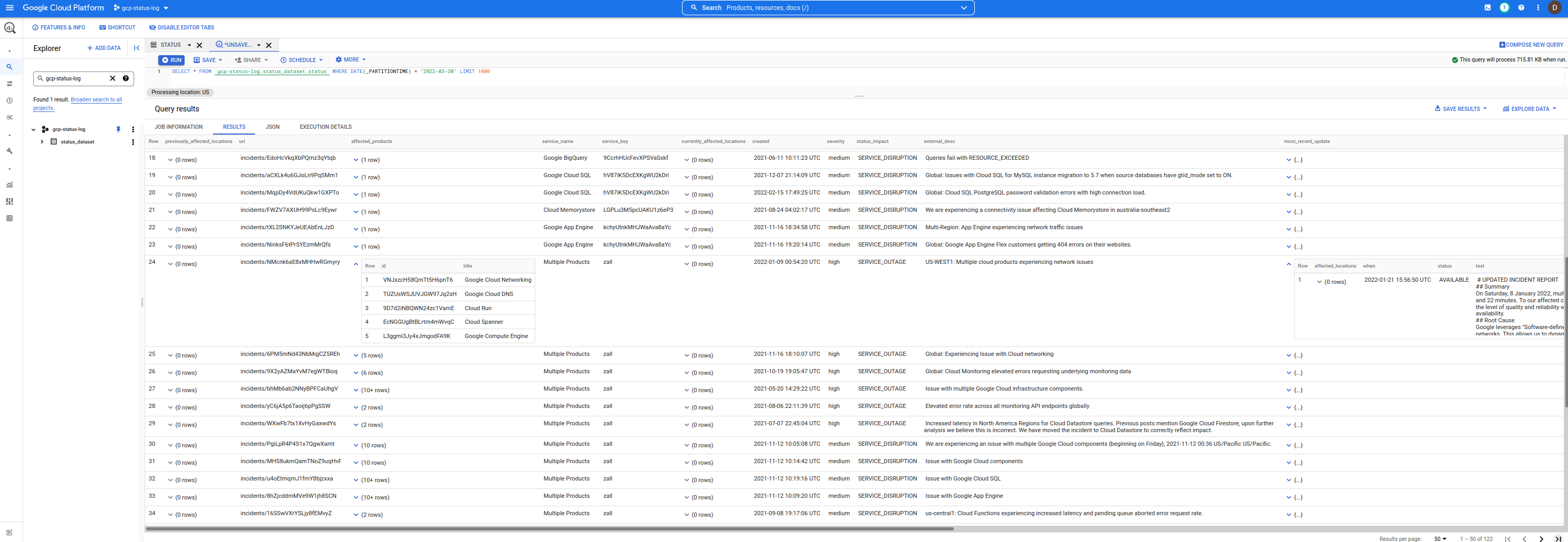
The Schema used here is pretty much the same format as provided by the JSON output of the dashboard shown in incidents.schema.json.
The only difference is each row in BQ is an individual incident as opposed to all incidents encapsulated into a single JSON per the provided schema above.
In addition, this schema has two new columns:
insert_timestamp: this is a TIMESTAMP when the row/event was insertedsnapshot_hash: this is the base64encoded hash of the incident.json file as it was downloaded.You can see the example schema here in this repo.
bq show --format=prettyjson --schema gcp-status-log:status_dataset.status
For everyone else, you can setup the whole thing on your own using a combination of
Cloud Scheduler -> Cloud Run -> BigQUeryWhat the following sets up is:
Cloud Scheduler securely invokes a Cloud Run serviceCloud Run downloads a file from a GCS bucket that holds the hash of the JSON CSH file last inserted
Cloud Run downloads and parses the JSON CSH dataCloud Run inserts the CSH events into BigQuery
ofcourse this scheme depends on the JSON CSH file remaining with the same hash value if there are no updates (eg., it does not include a freshness timestamp for its own updates)
export PROJECT_ID=`gcloud config get-value core/project`
export PROJECT_NUMBER=`gcloud projects describe $PROJECT_ID --format='value(projectNumber)'`
gcloud services enable containerregistry.googleapis.com
run.googleapis.com
bigquery.googleapis.com
cloudscheduler.googleapis.com
storage.googleapis.com
## create the datasets. We are using DAY partitioning
bq mk -d --data_location=US status_dataset
bq mk --table status_dataset.status schema.json
## create service accounts for cloud run and scheduler
gcloud iam service-accounts create schedulerunner --project=$PROJECT_ID
gcloud iam service-accounts create cloudrunsvc --project=$PROJECT_ID
bq add-iam-policy-binding
--member=serviceAccount:cloudrunsvc@$PROJECT_ID.iam.gserviceaccount.com
--role=roles/bigquery.admin status_dataset.status
gcloud projects add-iam-policy-binding $PROJECT_ID
--member="serviceAccount:cloudrunsvc@$PROJECT_ID.iam.gserviceaccount.com"
--role="roles/bigquery.jobUser"
# create a gcs bucket to store hash of the incidents json file
# the first value of the hash will force a reload of the incidents.json file
gsutil mb -l us-central1 gs://$PROJECT_ID-status-hash
echo -n "foo" > /tmp/hash.txt
gsutil cp /tmp/hash.txt gs://$PROJECT_ID-status-hash/
gsutil iam ch serviceAccount:cloudrunsvc@$PROJECT_ID.iam.gserviceaccount.com:roles/storage.admin gs://$PROJECT_ID-status-hash/
## you may also need to allow your users access to the dataset https://cloud.google.com/bigquery/docs/dataset-access-controls
## build and deploy the cloud run image
docker build -t gcr.io/$PROJECT_ID/gstatus .
docker push gcr.io/$PROJECT_ID/gstatus
gcloud run deploy gcp-status --image gcr.io/$PROJECT_ID/gstatus
--service-account cloudrunsvc@$PROJECT_ID.iam.gserviceaccount.com
--set-env-vars "BQ_PROJECTID=$PROJECT_ID" --no-allow-unauthenticated
export RUN_URL=`gcloud run services describe gcp-status --region=us-central1 --format="value(status.address.url)"`
## allow cloud scheduler to call cloud run
gcloud run services add-iam-policy-binding gcp-status --region=us-central1
--member=serviceAccount:schedulerunner@$PROJECT_ID.iam.gserviceaccount.com --role=roles/run.invoker
## deploy cloud scheduler
gcloud scheduler jobs create http status-scheduler-$region --http-method=GET --schedule "*/5 * * * *"
--attempt-deadline=420s --time-zone="Pacific/Tahiti" --location=us-central1
--oidc-service-account-email=schedulerunner@$PROJECT_ID.iam.gserviceaccount.com
--oidc-token-audience=$RUN_URL --uri=$RUN_URL[wait 5mins]
You can also combine the bq events with asset inventory data to help narrow if an event is impacting your service.
For example, if you know there is an event in us-central1-a that is impacting GCE instances, you can issue a search query restricting the
list of potential assets:
$ gcloud organizations list
DISPLAY_NAME ID DIRECTORY_CUSTOMER_ID
esodemoapp2.com 673202286123 C023zwabc
$ gcloud asset search-all-resources --scope='organizations/673202286123'
--query="location:us-central1-a"
--asset-types="compute.googleapis.com/Instance" --format="value(name)"
//compute.googleapis.com/projects/in-perimeter-gcs/zones/us-central1-a/instances/in-perimeter
//compute.googleapis.com/projects/ingress-vpcsc/zones/us-central1-a/instances/ingress
//compute.googleapis.com/projects/fabled-ray-104117/zones/us-central1-a/instances/instance-1
//compute.googleapis.com/projects/fabled-ray-104117/zones/us-central1-a/instances/nginx-vm-1
//compute.googleapis.com/projects/clamav-241815/zones/us-central1-a/instances/instance-1
//compute.googleapis.com/projects/fabled-ray-104117/zones/us-central1-a/instances/windows-1
You an also query IAM roles and permissions around the world using:
The source events are JSON so you could also potentially load each event into BQ using BQ Native Support for JSON DataType.
This maybe a TODO and a sample workflow maybe like this:
export PROJECT_ID=`gcloud config get-value core/project`
export PROJECT_NUMBER=`gcloud projects describe $PROJECT_ID --format='value(projectNumber)'`
bq mk --table status_dataset.json_dataset events:JSON
curl -o incidents.json -s https://status.cloud.google.com/incidents.json
cat incidents.json | jq -c '.[] | .' | sed 's/"/""/g' | awk '{ print """$0"""}' - > items.json
bq load --source_format=CSV status_dataset.json_dataset items.json
bq show status_dataset.json_dataset
$ bq show status_dataset.json_dataset
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Labels
----------------- ----------------- ------------ ------------- ------------ ------------------- ------------------ --------
08 Apr 09:39:48 |- events: json 125 822184 Then to query, you can reference each filed directly:
$ bq query --nouse_legacy_sql '
SELECT events["id"] as id, events["number"] as number, events["begin"] as begin
FROM `status_dataset.json_dataset`
LIMIT 10
'
+------------------------+------------------------+-----------------------------+
| id | number | begin |
+------------------------+------------------------+-----------------------------+
| "ukkfXQc8CEeFZbSTYQi7" | "14166479295409213890" | "2022-03-31T19:15:00+00:00" |
| "RmPhfQT9RDGwWLCXS2sC" | "3617221773064871579" | "2022-03-31T18:07:00+00:00" |
| "B1hD4KAtcxiyAWkcANfV" | "17742360388109155603" | "2022-03-31T15:30:00+00:00" |
| "4rRjbE16mteQwUeXPZwi" | "8134027662519725646" | "2022-03-29T21:00:00+00:00" |
| "2j8xsJMSyDhmgfJriGeR" | "5259740469836333814" | "2022-03-28T22:30:00+00:00" |
| "MtMwhU6SXrpBeg5peXqY" | "17330021626924647123" | "2022-03-25T07:00:00+00:00" |
| "R9vAbtGnhzo6n48SnqTj" | "2948654908633925955" | "2022-03-22T22:30:00+00:00" |
| "aA3kbJm5nwvVTKnYbrWM" | "551739384385711524" | "2022-03-18T22:20:00+00:00" |
| "LuGcJVjNTeC5Sb9pSJ9o" | "5384612291846020564" | "2022-03-08T18:07:00+00:00" |
| "Hko5cWSXxGSsxfiSpg4n" | "6491961050454270833" | "2022-02-22T05:45:00+00:00" |
+------------------------+------------------------+-----------------------------+
The corresponding modification to Cloud Run would involve creating CSV formatted load (since as of 4/8/22, CSV legacy loader is supported)
var rlines []string
for _, event := range events {
event.InsertTimestamp = now
event.SnapshotHash = sha256Value
strEvent, err := json.Marshal(event)
if err != nil {
fmt.Printf("Error Marshal Event %v", err)
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
// for JSON Datatype
// https://cloud.google.com/bigquery/docs/reference/standard-sql/json-data
line := strings.Replace(string(strEvent), """, """", -1)
line = fmt.Sprintf(""%s"", line)
rlines = append(rlines, line)
}
dataString := strings.Join(rlines, "n")
rolesSource := bigquery.NewReaderSource(strings.NewReader(dataString))
rolesSource.SourceFormat = bigquery.CSVAnyway, JSON Datatype is just a TODO and i'm not sure if its necessary at the moment
Why did i pick tahiti time again for the scheduler?
Why not, see for yourself:



