DreamerGPT
1.0.0
 DreamerGPT: fine tuning of Chinese language model instructions
DreamerGPT: fine tuning of Chinese language model instructions? DreamerGPT is a Chinese large language model instruction fine-tuning project initiated by Xu Hao, Chi Huixuan, Bei Yuanchen, and Liu Danyang.
Read in English version .

 1. Project introduction
1. Project introductionThe goal of this project is to promote the application of Chinese large language models in more vertical field scenarios.
Our goal is to make large models smaller and help everyone train and have a personalized expert assistant in their own vertical field. He can be a psychological counselor, a code assistant, a personal assistant, or It is your own language tutor, which means that DreamerGPT is a language model that has the best possible results, the lowest training cost, and is more optimized for Chinese. The DreamerGPT project will continue to open up iterative language model hot-start training (including LLaMa, BLOOM), command training, reinforcement learning, vertical field fine-tuning, and will continue to iterate reliable training data and evaluation targets. Due to limited project personnel and resources, the current V0.1 version is optimized for Chinese LLaMa for LLaMa-7B and LLaMa-13B, adding Chinese features, language alignment and other capabilities. Currently, there are still deficiencies in long dialogue capabilities and logical reasoning. Please see the next version of the update for more iteration plans.
The following is a quantization demo based on 8b (the video is not accelerated). Currently, inference acceleration and performance optimization are also being iterated:
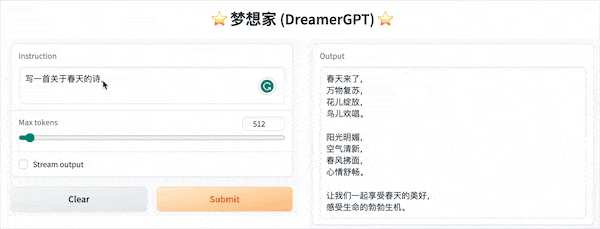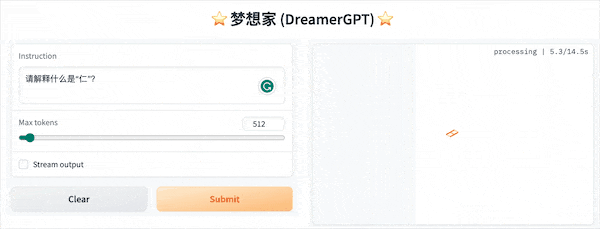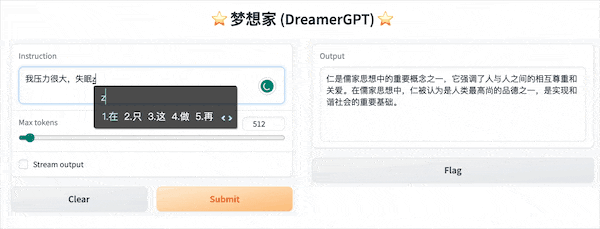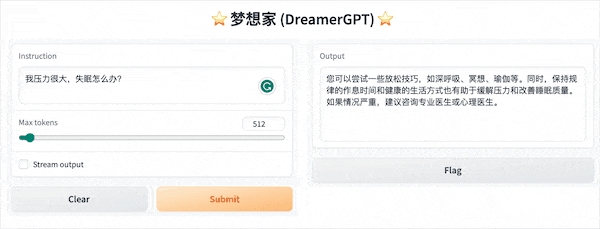
More demo displays:
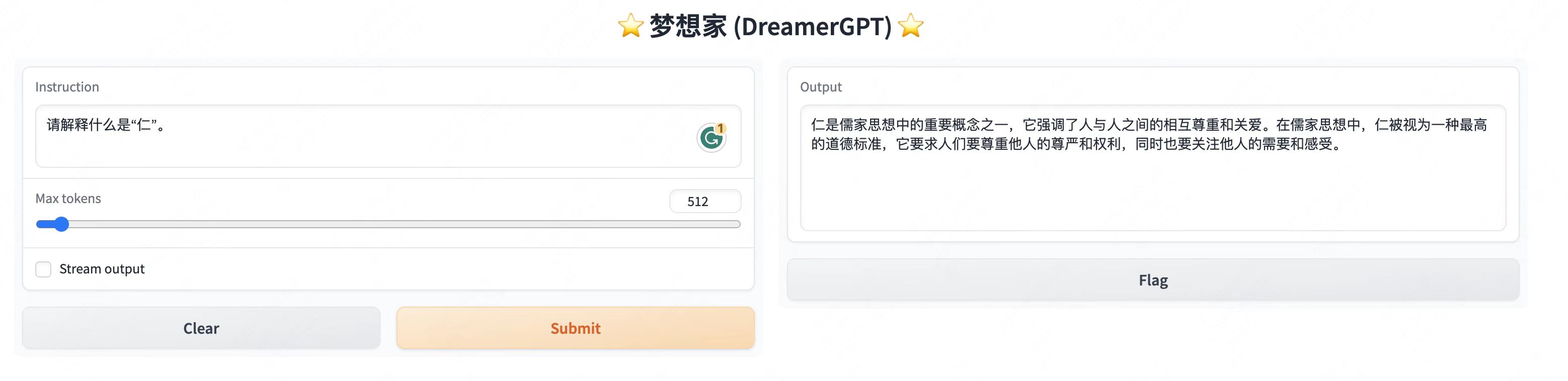

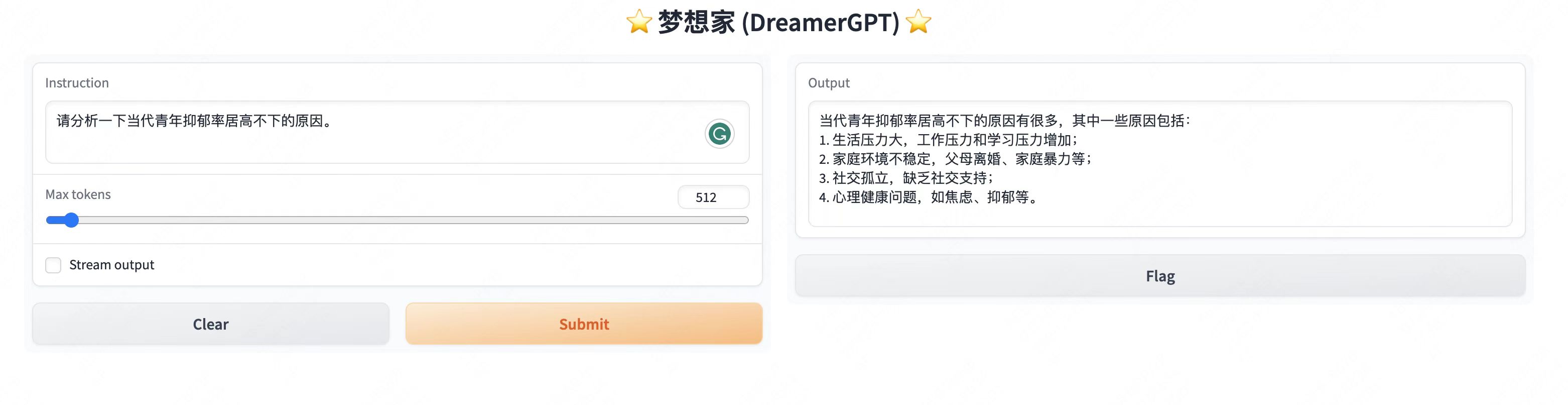
 2. Latest update
2. Latest update  [2023/06/17] Update V0.2 version: LLaMa firefly incremental training version, BLOOM-LoRA version (
[2023/06/17] Update V0.2 version: LLaMa firefly incremental training version, BLOOM-LoRA version ( finetune_bloom.py , generate_bloom.py ).
[2023/04/23] Officially open source Chinese command fine-tuning large model Dreamer (DreamerGPT) , currently providing V0.1 version download experience
Existing models (continuous incremental training, more models to be updated):
| Model name | training data= | Weight download |
|---|---|---|
| V0.2 | --- | --- |
| D13b-3-3 | D13b-2-3 + firefly-train-1 | [HuggingFace] |
| D7b-5-1 | D7b-4-1 + firefly-train-1 | [HuggingFace] |
| V0.1 | --- | --- |
| D13b-1-3-1 | Chinese-alpaca-lora-13b-hot start + COIG-part1, COIG-translate + PsyQA-5 | [Google Drive] [HuggingFace] |
| D13b-2-2-2 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1, COIG-translate | [Google Drive] [HuggingFace] |
| D13b-2-3 | Chinese-alpaca-lora-13b-hot start + firefly-train-0 + COIG-part1, COIG-translate + PsyQA-5 | [Google Drive] [HuggingFace] |
| D7b-4-1 | Chinese-alpaca-lora-7b-hotstart+firefly-train-0 | [Google Drive] [HuggingFace] |
Preview of model evaluation
 3. Model and data preparation
3. Model and data preparationModel weight download:
The data is uniformly processed into the following json format:
{
" instruction " : " ... " ,
" input " : " ... " ,
" output " : " ... "
}Data download and preprocessing script:
| data | type |
|---|---|
| Alpaca-GPT4 | English |
| Firefly (preprocessed into multiple copies, format alignment) | Chinese |
| COIG | Chinese, code, Chinese and English |
| PsyQA (preprocessed into multiple copies, format aligned) | Chinese psychological counseling |
| BELLE | Chinese |
| baize | Chinese conversation |
| Couplets (preprocessed into multiple copies, format aligned) | Chinese |
Note: The data comes from the open source community and can be accessed through links.
 4. Training code and scripts
4. Training code and scriptsCode and script introduction:
finetune.py : Instructions to fine-tune hot start/incremental training codegenerate.py : inference/test codescripts/ : run scriptsscripts/rerun-2-alpaca-13b-2.sh , see scripts/README.md for explanation of each parameter.  5. How to use
5. How to usePlease refer to Alpaca-LoRA for details and related questions.
pip install -r requirements.txtWeight fusion (taking alpaca-lora-13b as an example):
cd scripts/
bash merge-13b-alpaca.shParameter meaning (please modify the relevant path yourself):
--base_model , llama original weight--lora_model , chinese-llama/alpaca-lora weight--output_dir , path to output fusion weightsTake the following training process as an example to show the running script.
| start | f1 | f2 | f3 |
|---|---|---|---|
| Chinese-alpaca-lora-13b-hot start, experiment number: 2 | Data: firefly-train-0 | Data: COIG-part1, COIG-translate | Data: PsyQA-5 |
cd scripts/
# 热启动f1
bash run-2-alpaca-13b-1.sh
# 增量训练f2
bash rerun-2-alpaca-13b-2.sh
bash rerun-2-alpaca-13b-2-2.sh
# 增量训练f3
bash rerun-2-alpaca-13b-3.shExplanation of important parameters (please modify the relevant paths yourself):
--resume_from_checkpoint '前一次执行的LoRA权重路径'--train_on_inputs False--val_set_size 2000 If the data set itself is relatively small, it can be appropriately reduced, such as 500, 200Note that if you want to directly download the fine-tuned weights for inference, you can ignore 5.3 and proceed directly to 5.4.
For example, I want to evaluate the results of fine-tuning rerun-2-alpaca-13b-2.sh :
1. Web version interaction:
cd scripts/
bash generate-2-alpaca-13b-2.sh2. Batch inference and save results:
cd scripts/
bash save-generate-2-alpaca-13b-2.shExplanation of important parameters (please modify the relevant paths yourself):
--is_ui False : Whether it is a web version, the default is True--test_input_path 'xxx.json' : input instruction pathtest.json in the corresponding LoRA weight directory by default.  6. Evaluation report
6. Evaluation report There are currently 8 types of test tasks in the evaluation samples (numerical ethics and Duolun dialogue to be evaluated), each category has 10 samples, and the 8-bit quantified version is scored according to the interface calling GPT-4/GPT 3.5 (non-quantified version has a higher score), each sample is scored in a range of 0-10. See test_data/ for evaluation samples.
以下是五个类似 ChatGPT 的系统的输出。请以 10 分制为每一项打分,并给出解释以证明您的分数。输出结果格式为:System 分数;System 解释。
Prompt:xxxx。
答案:
System1:xxxx。
System2:xxxx。
System3:xxxx。
System4:xxxx。
System5:xxxx。Note: The scoring is for reference only. (Compared to GPT 3.5) GPT 4’s scoring is more accurate and more informative.
| Test tasks | Detailed example | Number of samples | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Total score for each item | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Trivia | 01qa.json | 10 | 80* | 78 | 78 | 68 | 95 |
| translate | 02translate.json | 10 | 77* | 77* | 77* | 64 | 86 |
| text generation | 03generate.json | 10 | 56 | 65* | 55 | 61 | 91 |
| sentiment analysis | 04analyse.json | 10 | 91 | 91 | 91 | 88* | 88* |
| reading comprehension | 05understanding.json | 10 | 74* | 74* | 74* | 76.5 | 96.5 |
| Chinese characteristics | 06chinese.json | 10 | 69* | 69* | 69* | 43 | 86 |
| code generation | 07code.json | 10 | 62* | 62* | 62* | 57 | 96 |
| Ethics, Refusal to Answer | 08alignment.json | 10 | 87* | 87* | 87* | 71 | 95.5 |
| mathematical reasoning | (to be evaluated) | -- | -- | -- | -- | -- | -- |
| Multiple rounds of dialogue | (to be evaluated) | -- | -- | -- | -- | -- | -- |
| Test tasks | Detailed example | Number of samples | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Total score for each item | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Trivia | 01qa.json | 10 | 65 | 64 | 63 | 67* | 89 |
| translate | 02translate.json | 10 | 79 | 81 | 82 | 89* | 91 |
| text generation | 03generate.json | 10 | 65 | 73* | 63 | 71 | 92 |
| sentiment analysis | 04analyse.json | 10 | 88* | 91 | 88* | 85 | 71 |
| reading comprehension | 05understanding.json | 10 | 75 | 77 | 76 | 85* | 91 |
| Chinese characteristics | 06chinese.json | 10 | 82* | 83 | 82* | 40 | 68 |
| code generation | 07code.json | 10 | 72 | 74 | 75* | 73 | 96 |
| Ethics, Refusal to Answer | 08alignment.json | 10 | 71* | 70 | 67 | 71* | 94 |
| mathematical reasoning | (to be evaluated) | -- | -- | -- | -- | -- | -- |
| Multiple rounds of dialogue | (to be evaluated) | -- | -- | -- | -- | -- | -- |
Overall, the model has good performance in translation , sentiment analysis , reading comprehension , etc.
Two people scored manually and then took the average.
| Test tasks | Detailed example | Number of samples | D13b-1-3-1 | D13b-2-2-2 | D13b-2-3 | D7b-4-1 | ChatGPT |
|---|---|---|---|---|---|---|---|
| Total score for each item | --- | 80 | 100 | 100 | 100 | 100 | 100 |
| Trivia | 01qa.json | 10 | 83* | 82 | 82 | 69.75 | 96.25 |
| translate | 02translate.json | 10 | 76.5* | 76.5* | 76.5* | 62.5 | 84 |
| text generation | 03generate.json | 10 | 44 | 51.5* | 43 | 47 | 81.5 |
| sentiment analysis | 04analyse.json | 10 | 89* | 89* | 89* | 85.5 | 91 |
| reading comprehension | 05understanding.json | 10 | 69* | 69* | 69* | 75.75 | 96 |
| Chinese characteristics | 06chinese.json | 10 | 55* | 55* | 55* | 37.5 | 87.5 |
| code generation | 07code.json | 10 | 61.5* | 61.5* | 61.5* | 57 | 88.5 |
| Ethics, Refusal to Answer | 08alignment.json | 10 | 84* | 84* | 84* | 70 | 95.5 |
| numerical ethics | (to be evaluated) | -- | -- | -- | -- | -- | -- |
| Multiple rounds of dialogue | (to be evaluated) | -- | -- | -- | -- | -- | -- |
 7. Next version update content
7. Next version update contentTODO List:
 Limitations, Usage Restrictions and Disclaimers
Limitations, Usage Restrictions and DisclaimersThe SFT model trained based on current data and basic models still has the following problems in terms of effectiveness:
Factual instructions may lead to incorrect answers that go against the facts.
Harmful instructions cannot be properly identified, which may lead to discriminatory, harmful, and unethical remarks.
The model's capabilities still need to be improved in some scenarios involving reasoning, coding, multiple rounds of dialogue, etc.
Based on the limitations of the above model, we require that the content of this project and subsequent derivatives generated by this project can only be used for academic research purposes and not for commercial purposes or uses that cause harm to society. The project developer does not assume any harm, loss or legal liability caused by the use of this project (including but not limited to data, models, codes, etc.).
 Quote
QuoteIf you use the code, data or models of this project, please cite this project.
@misc{DreamerGPT,
author = {Hao Xu, Huixuan Chi, Yuanchen Bei and Danyang Liu},
title = {DreamerGPT: Chinese Instruction-tuning for Large Language Model.},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/DreamerGPT/DreamerGPT}},
}
 Contact us
Contact usThere are still many shortcomings in this project. Please leave your suggestions and questions and we will try our best to improve this project.
Email: [email protected]


