datalens
1.0.0
This is a personal experiment that uses LLMs to rank unstructured job data based on user-defined criteria. Traditional job search platforms rely on rigid filtering systems, but many users lack such concrete criteria. Datalens lets you define your preferences in a more natural way and then rates each job postings based on the relevance.
Some criteria might be more important than others, so "must criteria" are weighted twice as much as normal ones.
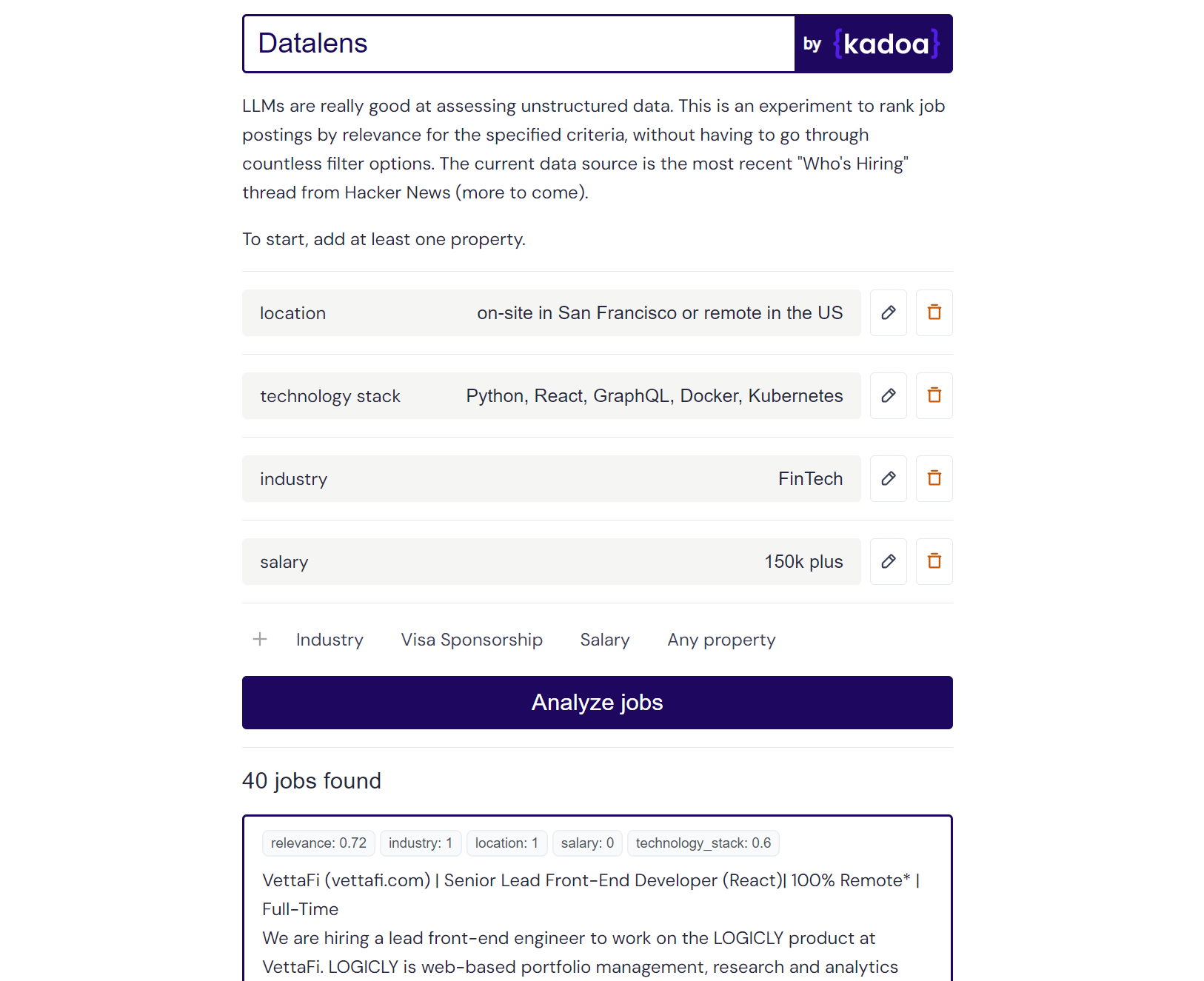
Claude-2 example result:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
You can add any job data source you like. I've pre-configured it with the most recent "Who's Hiring" thread from Hacker News, but you can add your own sources.
Add new job sources by updating sources_config.json. Example:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
I've used my own tool Kadoa to fetch the job data from the company pages, but you can use any other traditional scraping method.
Here are some ready-made public endpoints for getting the all job postings from these companies (updated daily):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
Let me know if should add any other companies. Also, happy to give you trial access to Kadoa.
The relevance scoring works best with gpt-4-0613 which returns granular scores between 0-1. claude-2 works quite well too if you have access to it.
gpt-3.5-turbo-0613 can be used, but it often returns binary scores of 0 or 1 for criteria, lacking the nuance to distinguish between partial and full matches.
The default model is gpt-3.5-turbo-0613 for cost reasons. You can switch from GPT to Claude by replacing use_claude with use_openai.
Running this script continuously can result in high API usage so please use it responsibly. I'm logging the cost for each GPT call.
To run the app, you need:
Copy the .env.example file and fill it out.
Run the Flask server:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
Navigate to the client directory and install Node dependencies:
cd client
npm install
Run the Next.js client:
cd client
npm run dev


