ShapeGPT
1.0.0

Project Page • Arxiv Paper • Demo • FAQ • Citation
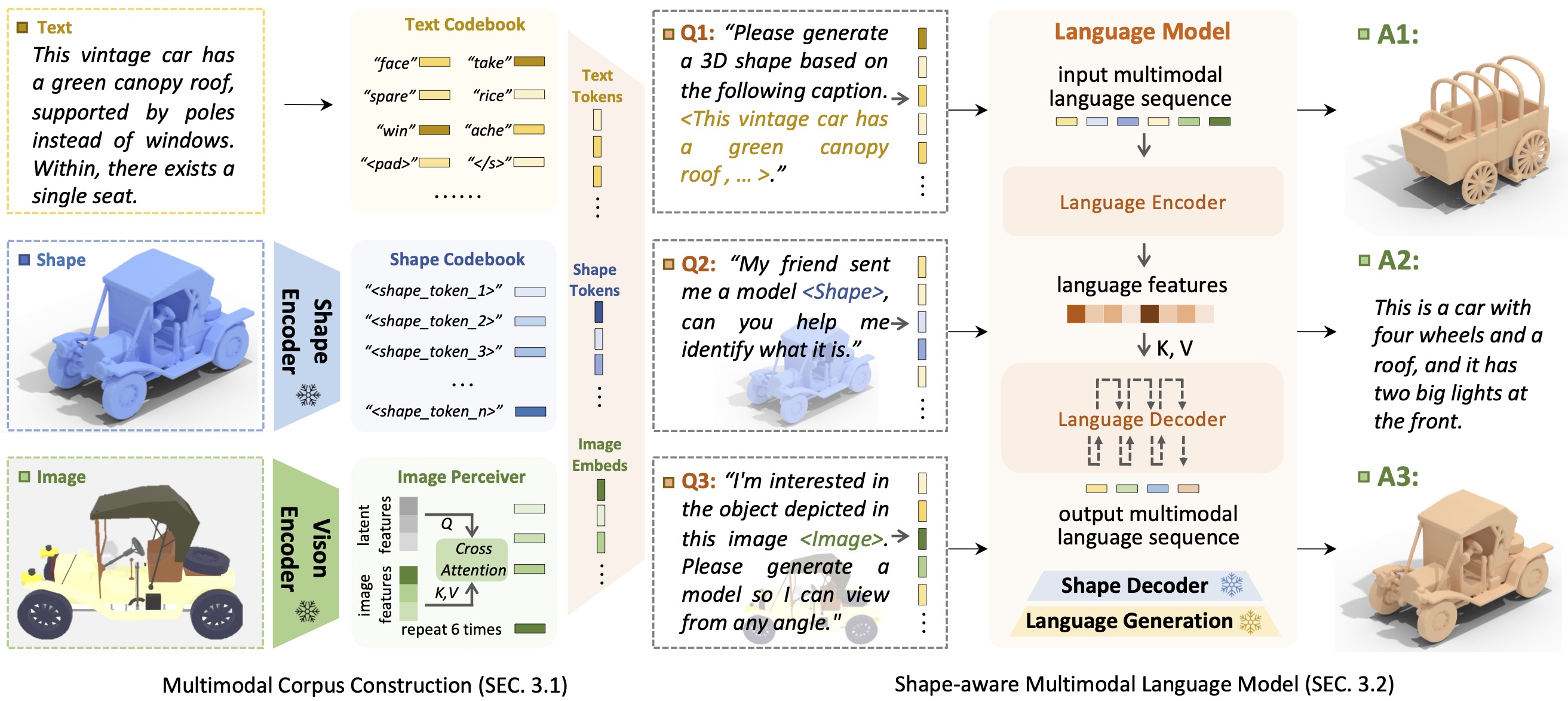
Intro ShapeGPTShapeGPT is a unified and user-friendly shape-centric multi-modal language model to establish a multi-modal corpus and develop shape-aware language models on multiple shape tasks.
The advent of large language models, enabling flexibility through instruction-driven approaches, has revolutionized many traditional generative tasks, but large models for 3D data, particularly in comprehensively handling 3D shapes with other modalities, are still under-explored. By achieving instruction-based shape generations, versatile multimodal generative shape models can significantly benefit various fields like 3D virtual construction and network-aided design. In this work, we present ShapeGPT, a shape-included multi-modal framework to leverage strong pre-trained language models to address multiple shape-relevant tasks. Specifically, ShapeGPT employs a word-sentence-paragraph framework to discretize continuous shapes into shape words, further assembles these words for shape sentences, as well as integrates shape with instructional text for multi-modal paragraphs. To learn this shape-language model, we use a three-stage training scheme, including shape representation, multimodal alignment, and instruction-based generation, to align shape-language codebooks and learn the intricate correlations among these modalities. Extensive experiments demonstrate that ShapeGPT achieves comparable performance across shape-relevant tasks, including text-to-shape, shape-to-text, shape completion, and shape editing.
If you find our code or paper helps, please consider citing:
@misc{yin2023shapegpt,
title={ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model},
author={Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen},
year={2023},
eprint={2311.17618},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Thanks to T5 model, Motion-GPT, Perceiver-IO and SDFusion, our code is partially borrowing from them. Our approach is inspired by Unified-IO, Michelangelo, ShapeCrafter, Pix2Vox, and 3DShape2VecSet.
This code is distributed under an MIT LICENSE.
Note that our code depends on other libraries, including PyTorch3D and PyTorch Lightning, and uses datasets which each have their own respective licenses that must also be followed.


