Darwin
1.0.0
Organization: University of New South Wales(UNSW) AI4Science & GreenDynamics AI
Darwin is an open-source project dedicated to pretrain and fine-tune the LLaMA model on scientific literature and datasets. Specifically designed for the scientific domain with an emphasis on materials science, chemistry, and physics, Darwin integrates structured and unstructured scientific knowledge to enhance the efficacy of language models in scientific research.
Usage and License Notices: Darwin is licensed and intended for research use only. The dataset is licensed under CC BY NC 4.0, allowing non-commercial use. Models trained using this dataset should not be used outside of research purposes. The weight diff is also under CC BY NC 4.0 license
[2024.11.20]
Key Achievements
Model Performance Insights
Data Strategies and Insights
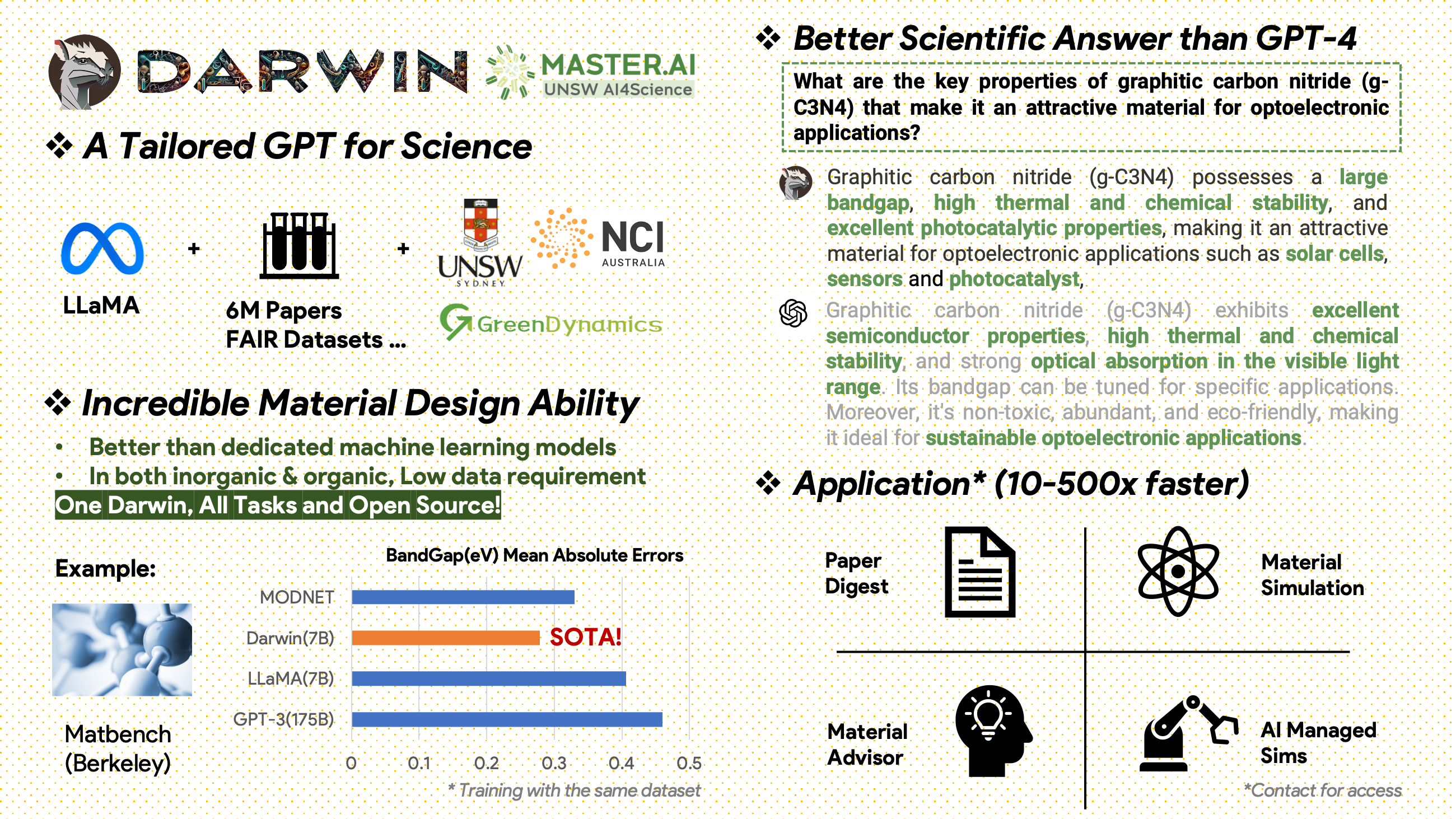
[2024.02.15] SOTA in MatBench by Material Projects: DARWIN is the SOTA model in experimental bandgap prediction tasks and metallic classification tasks, better than Fine-tuned GPT3.5 and dedicated ML models. https://matbench.materialsproject.org/Leaderboards%20Per-Task/matbench_v0.1_matbench_expt_gap/
☆ [2023.09.15]Google Colab Version available: Try our DARWIN with Google Colab: inference.ipynb
Darwin, based on the 7B LLaMA model, is trained on over 100,000 instruction-following data points generated by the Darwin Scientific Instruction Generator (SIG) from various scientific FAIR datasets and a literature corpus. By focusing on the factual correctness of the model's responses, Darwin represents a significant stride towards leveraging Large Language Models (LLMs) for scientific discovery. Preliminary human evaluations indicate that Darwin 7B outperforms GPT-4 in scientific Q&A and fine-tuned GPT-3 in solving chemistry problems (like gptChem).
We are actively developing Darwin for more advanced scientific domain experiments, and we're also integrating Darwin with LangChain to solve more complex scientific tasks (like a private research assistant for personal computers).
Please note, Darwin is still under development, and many limitations need to be addressed. Most importantly, we have yet to fine-tune Darwin for maximum safety. We encourage users to report any concerning behavior to help improve the model's safety and ethical considerations.
DEMO LINK
First install the requirements:
pip install -r requirements.txtDownload the checkpoints of the Darwin-7B Weights from onedrive. Once you've downloaded the model, you can try our demo:
python inference.py <your path to darwin-7b>Please note, the inference requires at least 10GB of GPU memory for Darwin 7B.
To further fine-tune our Darwin-7b with different datasets, below is a command that works on a machine with 4 A100 80G GPUs.
torchrun --nproc_per_node=8 --master_port=1212 train.py
--model_name_or_path <your path to darwin-7b>
--data_path <your path to dataset>
--bf16 True
--output_dir <your output dir>
--num_train_epochs 3
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 500
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type "cosine"
--logging_steps 1
--fsdp "full_shard auto_wrap"
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer'
--tf32 FalseOur data comes from two primary sources:
A raw literature corpus containing 6.0M papers on materials science, chemistry, and physics was published after 2000. The publishers include ACS, RSC, Springer Nature, Wiley, and Elsevier. We thank them for their support.
FAIR Datasets - We've collected data from 16 FAIR Datasets.
We developed Darwin-SIG to generate scientific instructions. It can memorize long texts from full literature texts (average ~5000 words) and generate question-and-answer (Q&A) data based on scientific literature keywords (from web of science API)
Note: You could also use GPT3.5 or GPT-4 for generation, but these options might be costly.
Please be aware that we can't share the training dataset due to agreements with the publishers.
This project is a collaborative effort by the following:
UNSW & GreenDynamics: Tong Xie, Shaozhou Wang
UNSW: Imran Razzak, Cody Huang
USYD & DARE Centre: Clara Grazian
GreenDynamics: Yuwei Wan,Yixuan Liu
Bram Hoex and Wenjie Zhang from UNSW Engineering advised all.
If you use the data or code from this repository in your work, please cite it accordingly.
DAWRIN Foundational Large Language Model & Semi-Self Instruct Fine Tuning
@misc{xie2023darwin,
title={DARWIN Series: Domain Specific Large Language Models for Natural Science},
author={Tong Xie and Yuwei Wan and Wei Huang and Zhenyu Yin and Yixuan Liu and Shaozhou Wang and Qingyuan Linghu and Chunyu Kit and Clara Grazian and Wenjie Zhang and Imran Razzak and Bram Hoex},
year={2023},
eprint={2308.13565},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Fine-tuned GPT-3 & LLaMA for Material Discovery (Single Task Training)
@article{xie2023large,
title={Large Language Models as Master Key: Unlocking the Secrets of Materials Science},
author={Xie, Tong and Wan, Yuwei and Zhou, Yufei and Huang, Wei and Liu, Yixuan and Linghu, Qingyuan and Wang, Shaozhou and Kit, Chunyu and Grazian, Clara and Zhang, Wenjie and others},
journal={Available at SSRN 4534137},
year={2023}
}
This project has referred to the following open-source projects:
Special thanks to NCI Australia for their HPC support.
We continuously expand Darwin's development Team. Join us on this exciting journey of advancing scientific research with AI!
For PhD or PostDoc positions, please get in touch with [email protected] or [email protected] for details.
For other positions, please visit www.greendynamics.com.au


