multimedia gpt
1.0.0
Multimedia GPT connects your OpenAI GPT with vision and audio. You can now send images, audio recordings, and pdf documents using your OpenAI API key, and get a response in both text and image formats. We are currently adding support for videos. All is made possible by a prompt manager inspired and built upon Microsoft Visual ChatGPT.
In addition to all of the vision foundation models mentioned in Microsoft Visual ChatGPT, Multimedia GPT supports OpenAI Whisper and OpenAI DALLE! This means that you no longer need your own GPUs for voice recognition and image generation (although you still can!)
The base chat model can be configured as any OpenAI LLM, including ChatGPT and GPT-4. We default to text-davinci-003.
You are welcome to fork this project and add models that's suitable for your own use case. A simple way to do this is through llama_index. You will have to create a new class for your model in model.py, and add a runner method run_<model_name> in multimedia_gpt.py. See run_pdf for an example.
In this demo, ChatGPT is fed with a recording of a person telling the story of Cinderella.
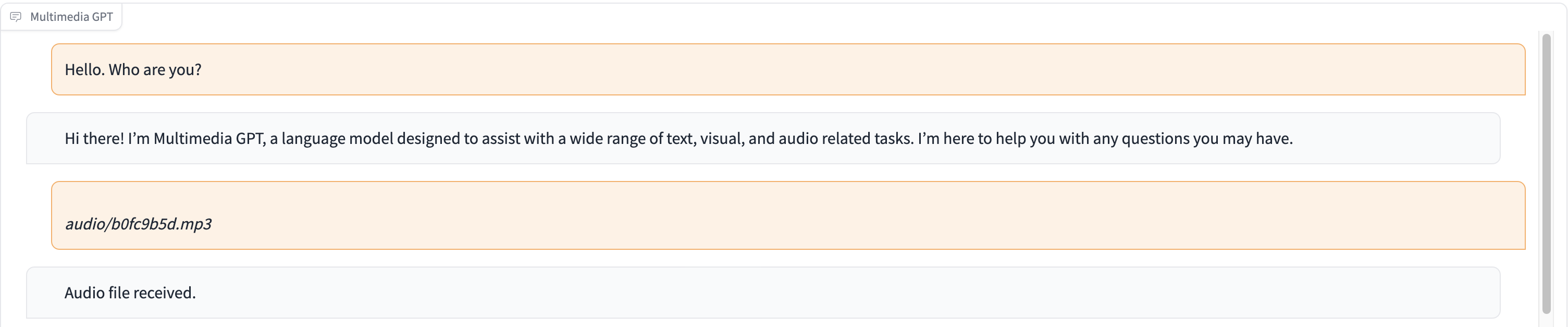
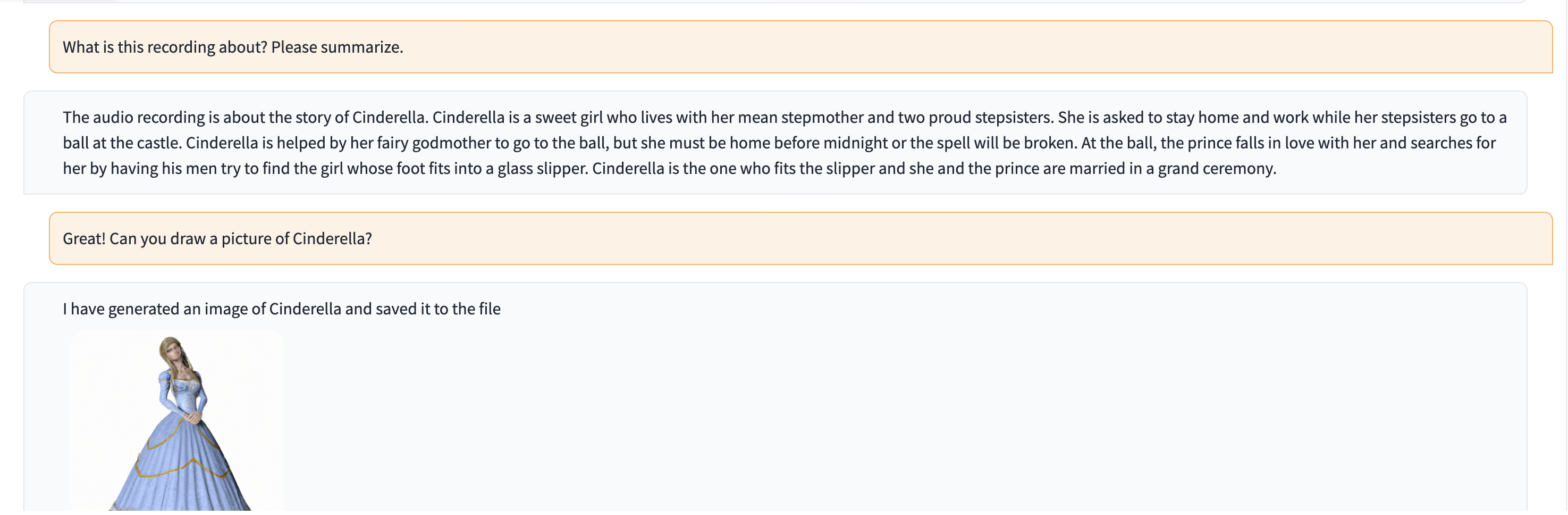
# Clone this repository
git clone https://github.com/fengyuli2002/multimedia-gpt
cd multimedia-gpt
# Prepare a conda environment
conda create -n multimedia-gpt python=3.8
conda activate multimedia-gptt
pip install -r requirements.txt
# prepare your private OpenAI key (for Linux / MacOS)
echo "export OPENAI_API_KEY='yourkey'" >> ~/.zshrc
# prepare your private OpenAI key (for Windows)
setx OPENAI_API_KEY “<yourkey>”
# Start Multimedia GPT!
# You can specify the GPU/CPU assignment by "--load", the parameter indicates which foundation models to use and
# where it will be loaded to. The model and device are separated by '_', different models are separated by ','.
# The available Visual Foundation Models can be found in models.py
# For example, if you want to load ImageCaptioning to cuda:0 and whisper to cpu
# (whisper runs remotely, so it doesn't matter where it is loaded to)
# You can use: "ImageCaptioning_cuda:0,Whisper_cpu"
# Don't have GPUs? No worry, you can run DALLE and Whisper on cloud using your API key!
python multimedia_gpt.py --load ImageCaptioning_cpu,DALLE_cpu,Whisper_cpu
# Additionally, you can configure the which OpenAI LLM to use by the "--llm" tag, such as
python multimedia_gpt.py --llm text-davinci-003
# The default is gpt-3.5-turbo (ChatGPT). This project is an experimental work and will not be deployed to a production environment. Our goal is to explore the power of prompting.


