paxml
paxml release 1.4.0
Pax is a framework to configure and run machine learning experiments on top of Jax.
We refer to this page for more exhaustive documentation about starting a Cloud TPU project. The following command is sufficient to create a Cloud TPU VM with 8 cores from a corp machine.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT=<your-project>
export ACCELERATOR=v4-8
export TPU_NAME=paxml
#create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone=$ZONE --version=$VERSION
--project=$PROJECT
--accelerator-type=$ACCELERATORIf you are using TPU Pod slices, please refer to this guide. Run all the commands from a local machine using gcloud with the --worker=all option:
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone=$ZONE
--worker=all --command="<commmands>"The following quickstart sections assume you run on a single-host TPU, so you can ssh to the VM and run the commands there.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone=$ZONEAfter ssh-ing the VM, you can install the paxml stable release from PyPI, or the dev version from github.
For installing the stable release from PyPI (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.htmlIf you encounter issues with transitive dependencies and you are using the native Cloud TPU VM environment, please navigate to the corresponding release branch rX.Y.Z and download paxml/pip_package/requirements.txt. This file includes the exact versions of all transitive dependencies needed in the native Cloud TPU VM environment, in which we build/test the corresponding release.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtFor installing the dev version from github, and for the ease of editing code:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install "jax[tpu]" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html# example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs://<your-bucket>
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs://<your-bucket>
--pmap_use_tensorstore=TruePlease visit our docs folder for documentations and Jupyter Notebook tutorials. Please see the following section for instructions of running Jupyter Notebooks on a Cloud TPU VM.
You can run the example notebooks in the TPU VM in which you just installed paxml.
####Steps to enable a notebook in a v4-8
ssh in TPU VM with port forwarding
gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
install jupyter notebook on the TPU vm and downgrade markupsafe
pip install notebook
pip install markupsafe==2.0.1
export jupyter path
export PATH=/home/$USER/.local/bin:$PATH
scp the example notebooks to your TPU VM
gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
start jupyter notebook from the TPU VM and note the token generated by jupyter notebook
jupyter notebook --no-browser --port=8080
then in your local browser go to: http://localhost:8080/ and enter the token provided
Note: In case you need to start using a second notebook while the first notebook is still occupying the TPUs, you can run
pkill -9 python3
to free up the TPUs.
Note: NVIDIA has released an updated version of Pax with H100 FP8 support and broad GPU performance improvements. Please visit the NVIDIA Rosetta repository for more details and usage instructions.
The Profile Guided Latency Estimator (PGLE) workflow measures the actual running time of compute and collectives, the the profile information is fed back into XLA compiler for a better scheduling decision.
The Profile Guided Latency Estimator can be used manually or automatically. In the auto mode JAX will collect profile information and recompile a module in a single run. While in manual mode you need to run a task twice, the first time to collect and save profiles and the second to compile and run with provided data.
The auto PGLE can be turned on by setting the following environment variables:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
Or in the JAX this can be set as the following:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
You can control amount of reruns used to collect profile data by changing JAX_PGLE_PROFILING_RUNS.
Increasing this parameter would lead to better profile information, but it will also increase the
amount of non-optimized training steps.
The JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY parameters allows to use host callbacks with the auto PGLE.
Decreasing the JAX_PGLE_AGGREGATION_PERCENTILE parameter might help in case when performance between steps is too noisy to filter out a non-relevant measures.
Attention: Auto PGLE doesn't work for pre-compiled modules. Since JAX need to recompile the module during execution the auto PGLE will not work neither for AoT nor for the following case:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
If you still want to use a manual Profile Guided Latency Estimator the workflow in XLA/GPU is:
You could do so by setting:
export XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"import os
from etils import epath
import jax
from jax.experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax.profiler.start_trace(profile_dir)
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax.profiler.stop_trace()
profile_dir = epath.Path(profile_dir)
directories = profile_dir.glob('plugins/profile/*/')
directories = [d for d in directories if d.is_dir()]
rundir = directories[-1]
logging.info('rundir: %s', rundir)
# Post process the profile
fdo_profile = exp_profiler.get_profiled_instructions_proto(os.fspath(rundir))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir.parent.mkdir(parents=True, exist_ok=True)
dump_dir.write_bytes(fdo_profile)After this step, you will get a profile.pb file under the rundir printed in the code.
You need to pass the profile.pb file to the --xla_gpu_pgle_profile_file_or_directory_path flag.
export XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb"To enable logging in the XLA and check if the profile is good, set the logging level to include INFO:
export TF_CPP_MIN_LOG_LEVEL=0Run the real workflow, if you found these loggings in the running log, it means the profiler is used in the latency hiding scheduler:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax runs on Jax, you can find details on running Jax jobs on Cloud TPU here, also you can find details on running Jax jobs on a Cloud TPU pod here
If you run into dependency errors, please refer to the requirements.txt file in the branch corresponding to the stable release you are installing.
For e.g., for the stable release 0.4.0 use branch r0.4.0 and refer to the requirements.txt for the exact versions of the dependencies used for the stable release.
Here are some sample convergence runs on c4 dataset.
You can run a 1B params model on c4 dataset on TPU v4-8using the config C4Spmd1BAdam4Replicasfrom c4.py as follows:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
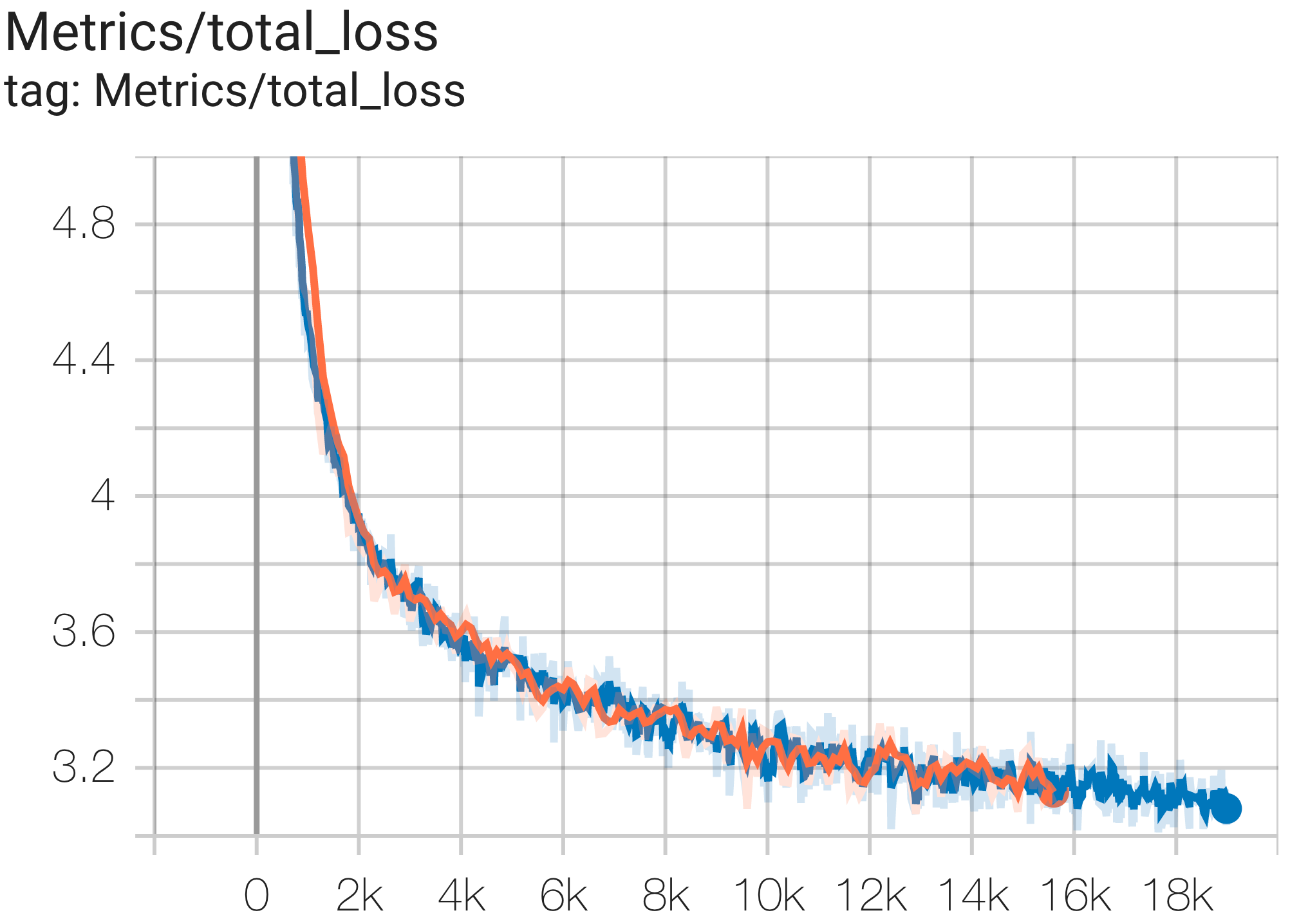
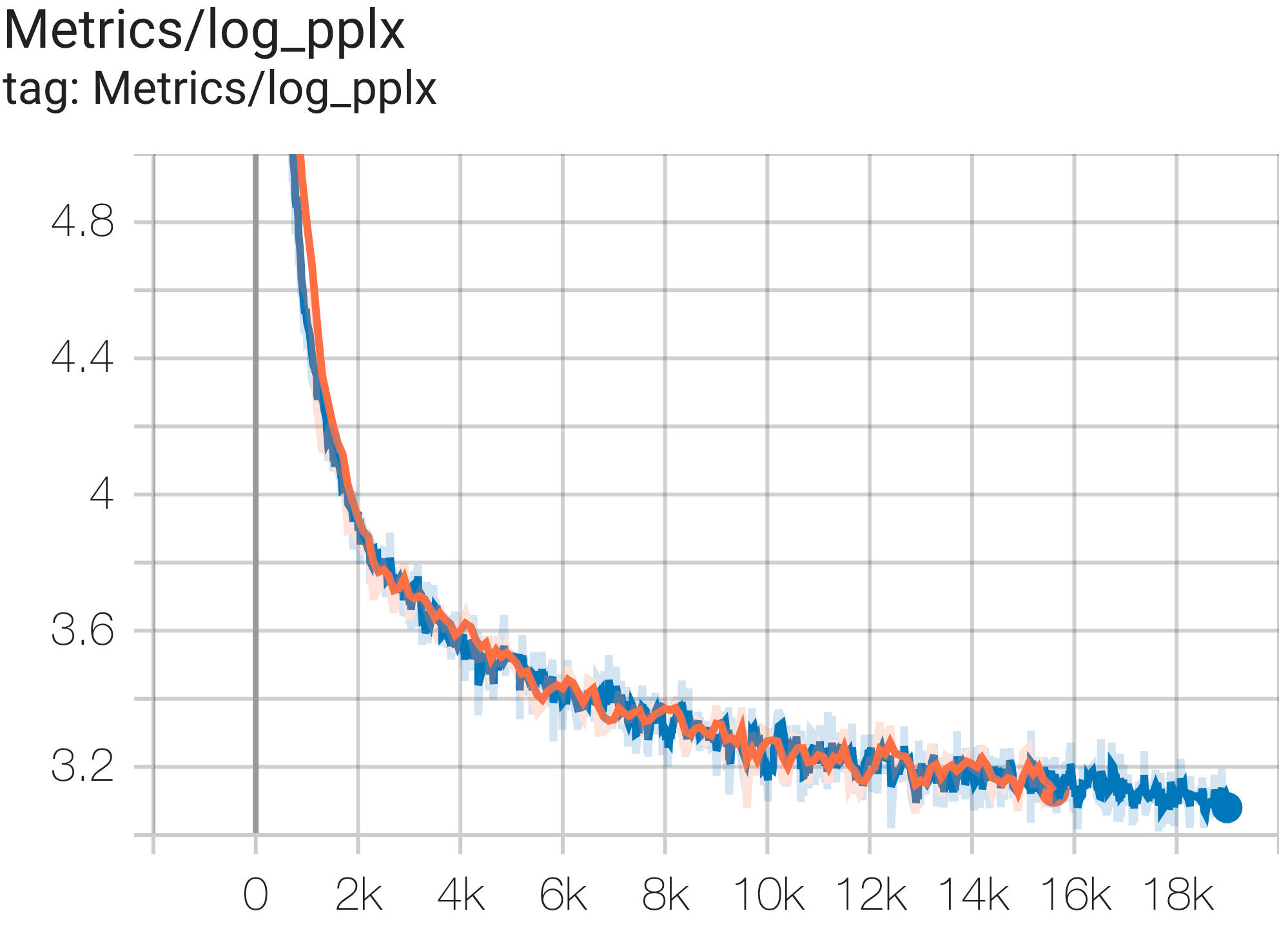
--job_log_dir=gs://<your-bucket>You can observe loss curve and log perplexity graph as follows:
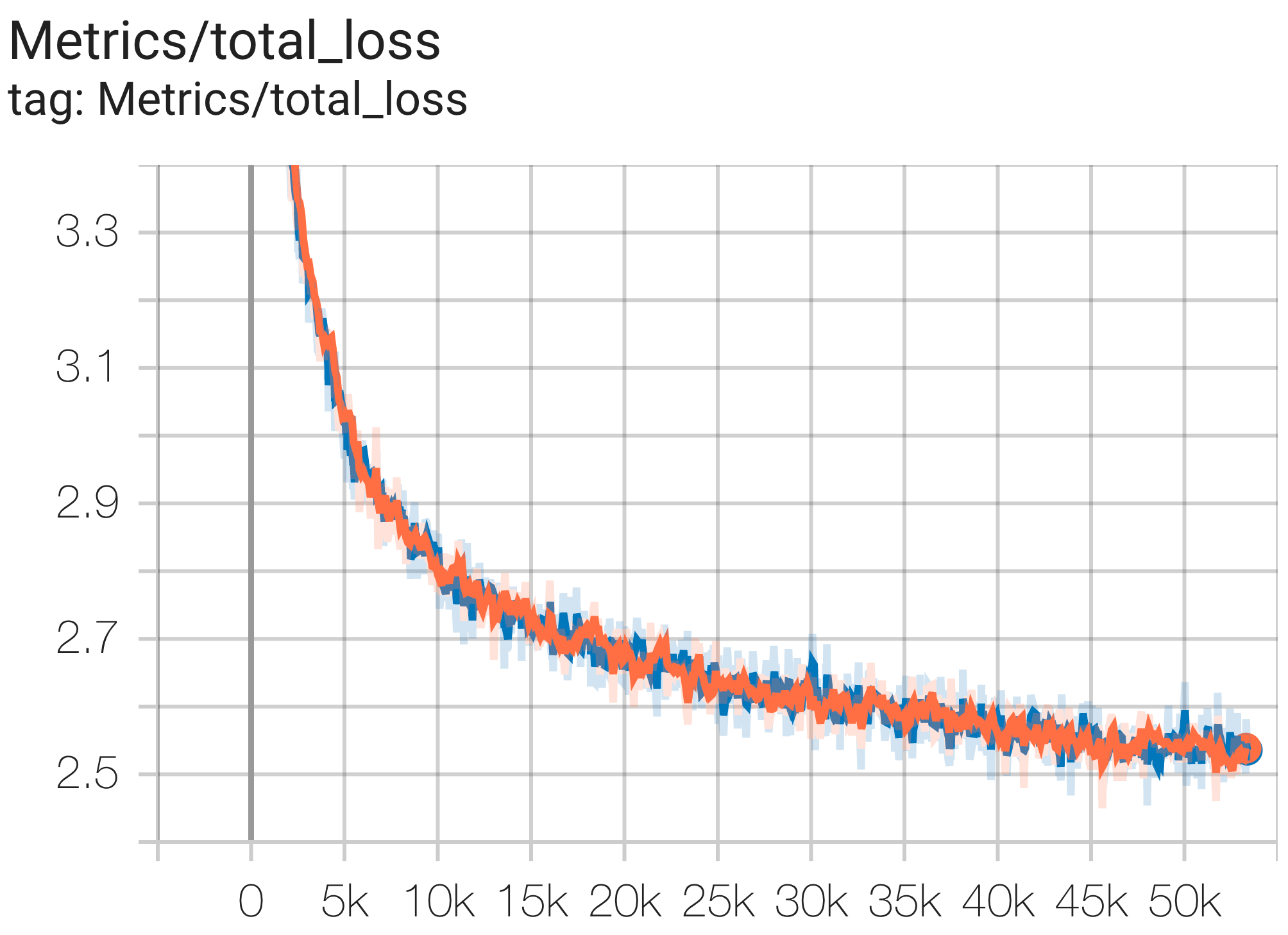
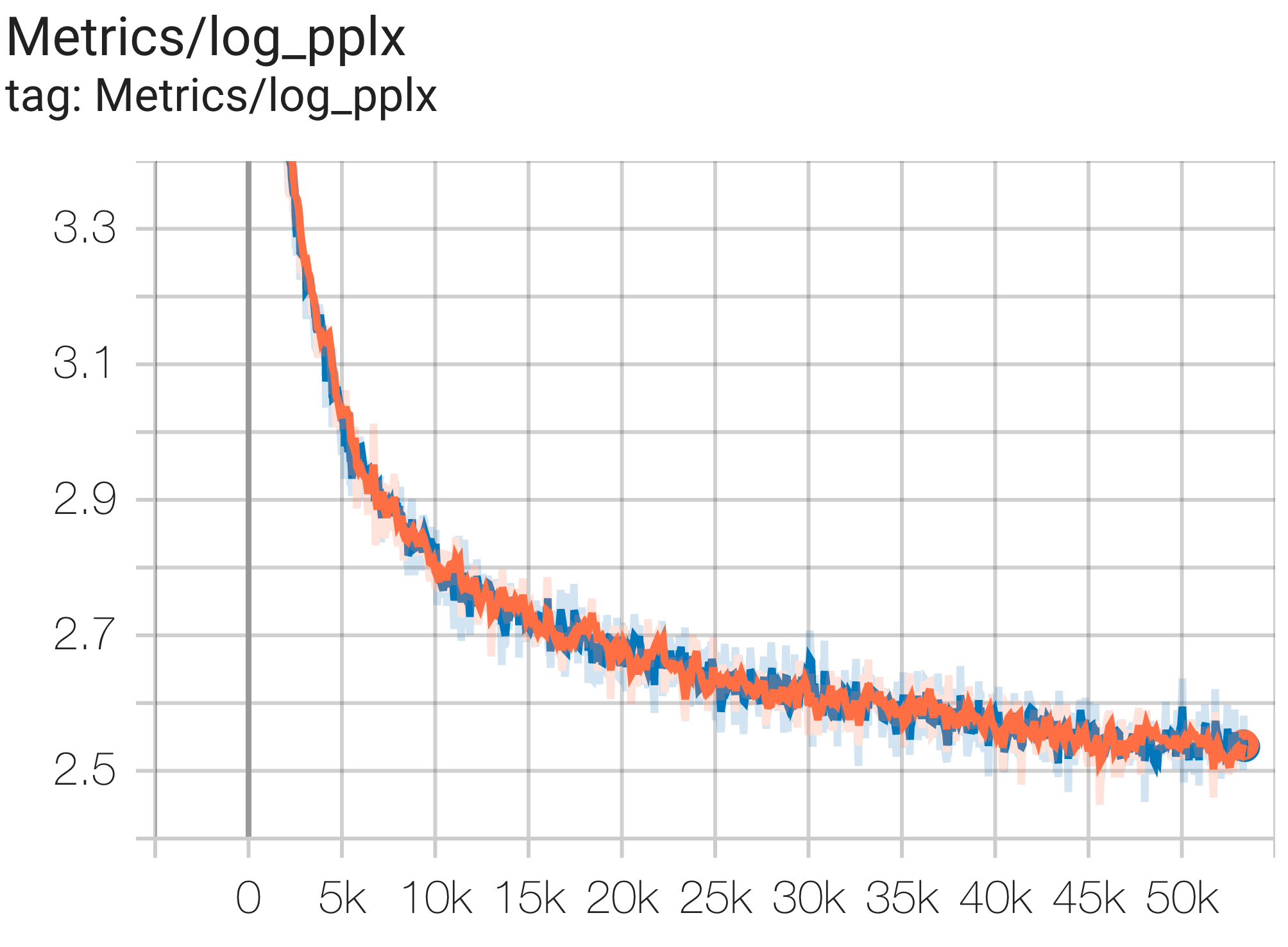
You can run a 16B params model on c4 dataset on TPU v4-64using the config C4Spmd16BAdam32Replicasfrom c4.py as follows:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs://<your-bucket>You can observe loss curve and log perplexity graph as follows:
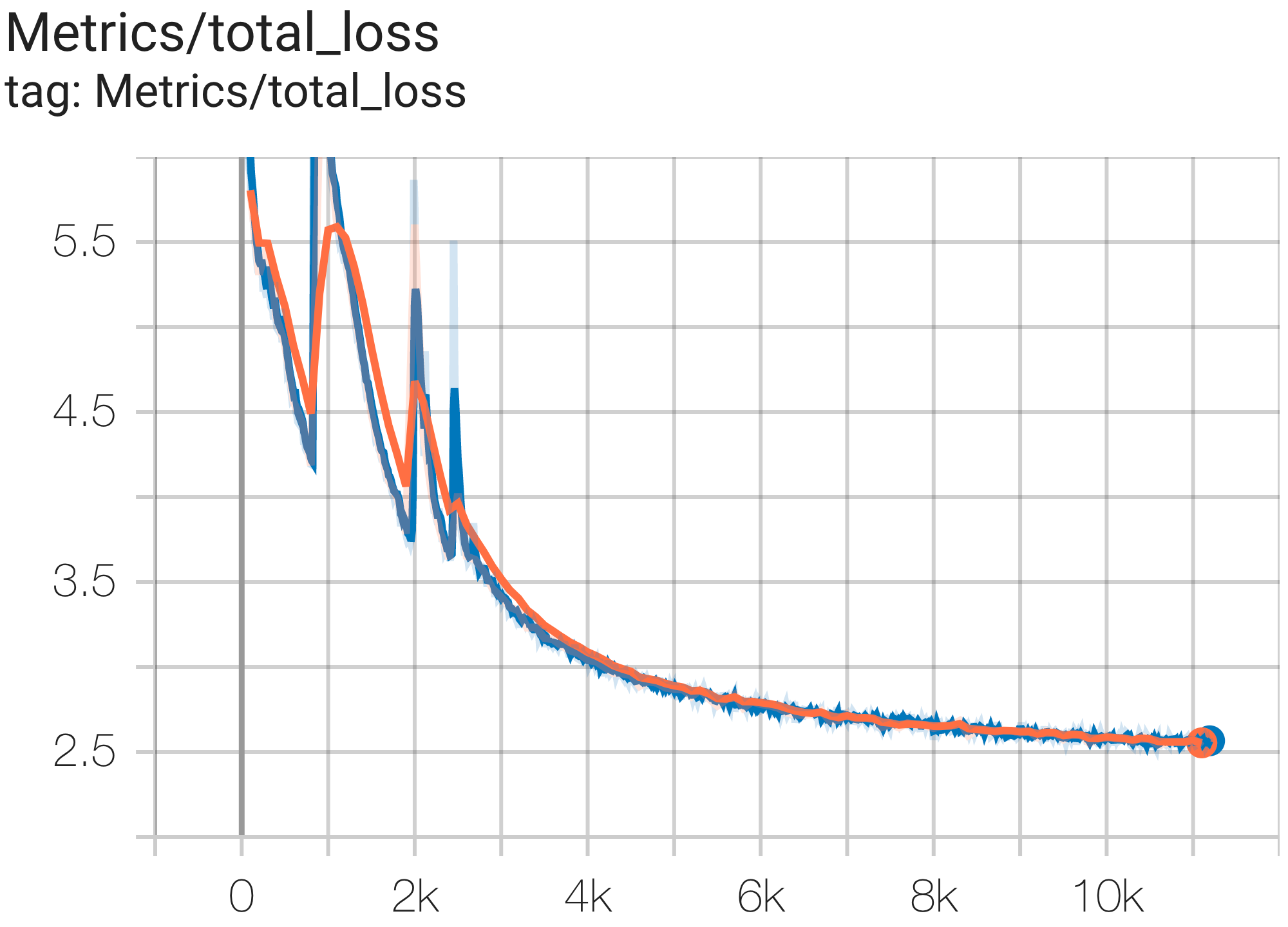
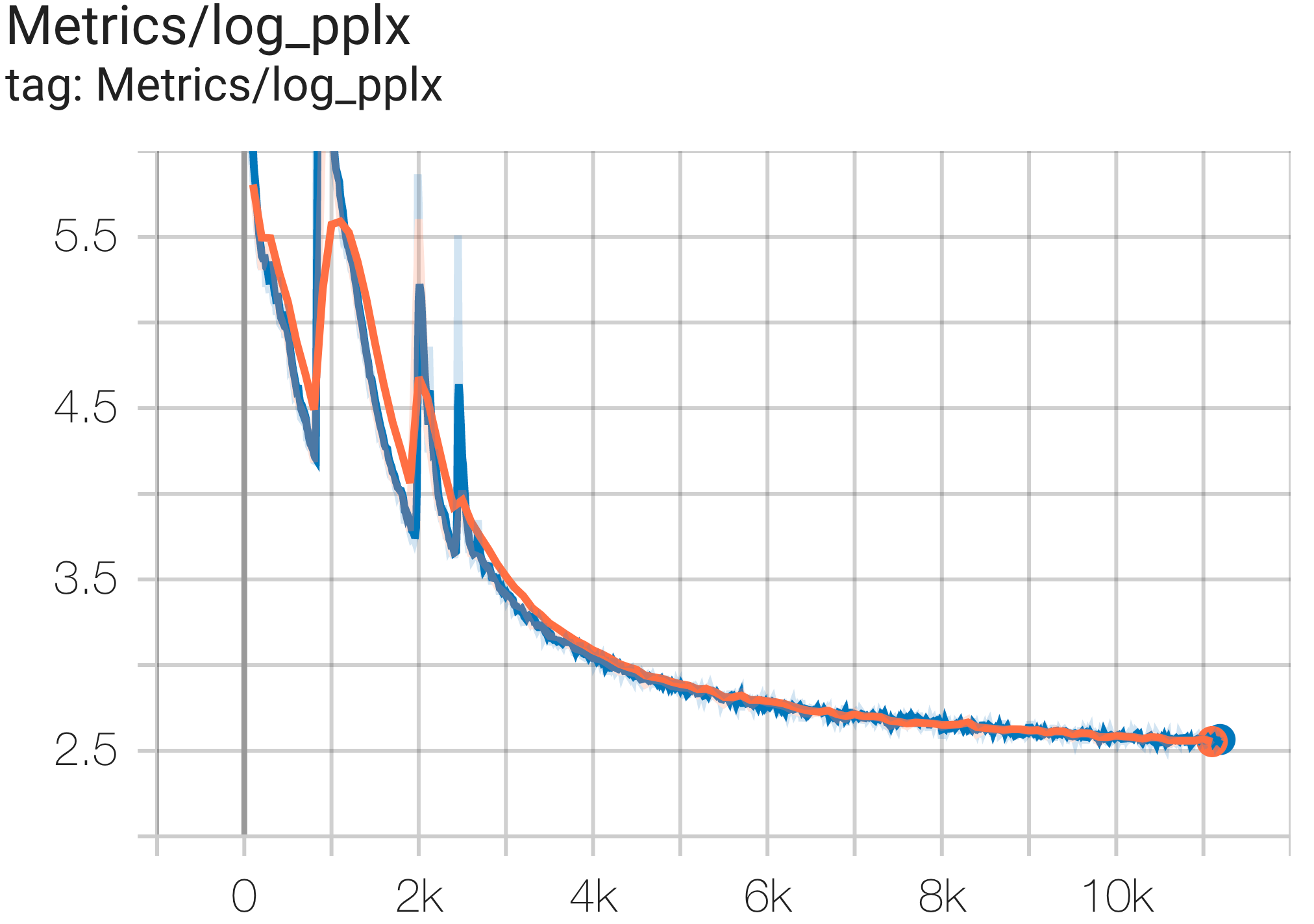
You can run the GPT3-XL model on c4 dataset on TPU v4-128using the config C4SpmdPipelineGpt3SmallAdam64Replicasfrom c4.py as follows:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs://<your-bucket>You can observe loss curve and log perplexity graph as follows:
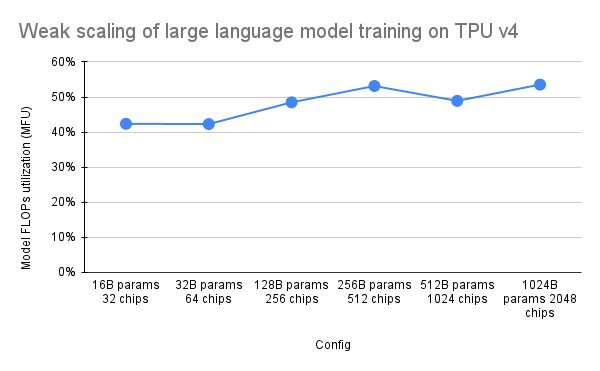
The PaLM paper introduced an efficiency metric called Model FLOPs Utilization (MFU). This is measured as the ratio of the observed throughput (in, for example, tokens per second for a language model) to the theoretical maximum throughput of a system harnessing 100% of peak FLOPs. It differs from other ways of measuring compute utilization because it doesn’t include FLOPs spent on activation rematerialization during the backward pass, meaning that efficiency as measured by MFU translates directly into end-to-end training speed.
To evaluate the MFU of a key class of workloads on TPU v4 Pods with Pax, we carried out an in-depth benchmark campaign on a series of decoder-only Transformer language model (GPT) configurations that range in size from billions to trillions of parameters on the c4 dataset. The following graph shows the training efficiency using the "weak scaling" pattern where we grew the model size in proportion to the number of chips used.
The multislice configs in this repo refer to 1. Singlie slice configs for syntax / model architecture and 2. MaxText repo for config values.
We provide example runs under c4_multislice.py` as a starting point for Pax on multislice.
We refer to this page for more exhaustive documentation about using Queued Resources for a multi-slice Cloud TPU project. The following shows the steps needed to set up TPUs for running example configs in this repo.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT=<your-project>
export ACCELERATOR=v4-128 # or v4-384 depending on which config you runSay, for running C4Spmd22BAdam2xv4_128 on 2 slices of v4-128, you'd need to set up TPUs the following way:
export TPU_PREFIX=<your-prefix> # New TPUs will be created based off this prefix
export QR_ID=$TPU_PREFIX
export NODE_COUNT=<number-of-slices> # 1, 2, or 4 depending on which config you run
#create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type=$ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count=$NODE_COUNT --node-prefix=$TPU_PREFIXThe setup commands described earlier need to be run on ALL workers in ALL slices. You can 1) ssh into each worker and each slice individually; or 2) use for loop with --worker=all flag as the following command.
for ((i=0; i<$NODE_COUNT; i++))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX-$i --zone=us-central2-b --worker=all --command="pip install paxml && pip install orbax==0.1.1 && pip install "jax[tpu]" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html"
doneIn order to run the multislice configs, open the same number of terminals as your $NODE_COUNT. For our experiments on 2 slices(C4Spmd22BAdam2xv4_128), open two terminals. Then, run each of these commands individually from each terminal.
From Terminal 0, run training command for slice 0 as follows:
export TPU_PREFIX=<your-prefix>
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS="--xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE"
gcloud compute tpus tpu-vm ssh $TPU_PREFIX-0 --zone=us-central2-b --worker=all
--command="LIBTPU_INIT_ARGS=$LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice.${EXP_NAME} --job_log_dir=gs://<your-bucket>"From Terminal 1, concurrently run training command for slice 1 as follows:
export TPU_PREFIX=<your-prefix>
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS="--xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE"
gcloud compute tpus tpu-vm ssh $TPU_PREFIX-1 --zone=us-central2-b --worker=all
--command="LIBTPU_INIT_ARGS=$LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice.${EXP_NAME} --job_log_dir=gs://<your-bucket>"This table covers details on how the MaxText variable names have been translated to Pax.
Note that MaxText has a "scale" which is multiplied to several parameters (base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads) for final values.
Another thing to mention is while Pax covers DCN and ICN MESH_SHAPE as an array, in MaxText there are separate variables of data_parallelism, fsdp_parallelism and tensor_parallelism for DCN and ICI. Since these values are set as 1 by default, only the variables with value greater than 1 are recorded in this translation table.
That is, ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] and DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| Pax C4Spmd22BAdam2xv4_128 | MaxText 2xv4-128.sh | (after scale is applied) | ||
|---|---|---|---|---|
| scale (applied to next 4 variables) | 3 | |||
| NUM_LAYERS | 48 | base_num_decoder_layers | 16 | 48 |
| MODEL_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| HIDDEN_DIMS | 24576 | MODEL_DIMS * 4 (= base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | head_dim | 256 | |
| PERCORE_BATCH_SIZE | 16 | per_device_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | max_target_length | 1024 | |
| VOCAB_SIZE | 32768 | vocab_size | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | dtype | bfloat16 | |
| USE_REPEATED_LAYER | TRUE | |||
| SUMMARY_INTERVAL_STEPS | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_parallelism | 64 | |
| DCN_MESH_SHAPE | [2, 1, 1] | dcn_data_parallelism | 2 |
Input is an instance of the BaseInput
class for getting data into model for train/eval/decode.
class BaseInput:
def get_next(self):
pass
def reset(self):
passIt acts like an iterator: get_next() returns a NestedMap, where each field
is a numerical array with batch size as its leading dimension.
Each input is configured by a subclass of BaseInput.HParams.
In this page, we use p to denote an instance of a BaseInput.Params, and it
instantiates to input.
In Pax, data is always multihost: Each Jax process will have a separate,
independent input instantiated. Their params will have different
p.infeed_host_index, set automatically by Pax.
Hence, the local batch size seen on each host is p.batch_size, and the global
batch size is (p.batch_size * p.num_infeed_hosts). One will often see
p.batch_size set to jax.local_device_count() * PERCORE_BATCH_SIZE.
Due to this multihost nature, input must be sharded properly.
For training, each input must never emit identical batches, and for eval on a
finite dataset, each input must terminate after the same number of batches.
The best solution is to have the input implementation properly shard the data,
such that each input on different hosts do not overlap. Failing that, one can
also use different random seed to avoid duplicate batches during training.
input.reset() is never called on training data, but it can for eval (or
decode) data.
For each eval (or decode) run, Pax fetches N batches from input by calling
input.get_next() N times. The number of batches used, N, can be a fixed
number specified by user, via p.eval_loop_num_batches; or N can be dynamic
(p.eval_loop_num_batches=None) i.e. we call input.get_next() until we
exhaust all of its data (by raising StopIteration or tf.errors.OutOfRange).
If p.reset_for_eval=True, p.eval_loop_num_batches is ignored and N is
determined dynamically as the number of batches to exhaust the data. In this
case, p.repeat should be set to False, as doing otherwise would lead to
infinite decode/eval.
If p.reset_for_eval=False, Pax will fetch p.eval_loop_num_batches batches.
This should be set with p.repeat=True so that data are not prematurely
exhausted.
Note that LingvoEvalAdaptor inputs require p.reset_for_eval=True.
N: static |
N: dynamic |
|
|---|---|---|
p.reset_for_eval=True |
Each eval run uses the | One epoch per eval run. |
: : first N batches. Not : eval_loop_num_batches : |
||
| : : supported yet. : is ignored. Input must : | ||
| : : : be finite : | ||
: : : (p.repeat=False) : |
||
p.reset_for_eval=False |
Each eval run uses | Not supported. |
: : non-overlapping N : : |
||
| : : batches on a rolling : : | ||
| : : basis, according to : : | ||
: : eval_loop_num_batches : : |
||
| : : . Input must repeat : : | ||
| : : indefinitely : : | ||
: : (p.repeat=True) or : : |
||
| : : otherwise may raise : : | ||
| : : exception : : |
If running decode/eval on exactly one epoch (i.e. when p.reset_for_eval=True),
the input must handle sharding correctly such that each shard raises at the same
step after exactly the same number of batches are produced. This usually means
that the input must pad the eval data. This is done automatically
bySeqIOInput and LingvoEvalAdaptor (see more below).
For the majority of inputs, we only ever call get_next() on them to get
batches of data. One type of eval data is an exception to this, where "how to
compute metrics" is also defined on the input object as well.
This is only supported with SeqIOInput that defines some canonical eval
benchmark. Specifically, Pax uses predict_metric_fns and score_metric_fns() defined on the SeqIO task to compute
eval metrics (although Pax does not depend on SeqIO evaluator directly).
When a model uses multiple inputs, either between train/eval or different training data between pretraining/finetuning, users must ensure that the tokenizers used by the inputs are identical, especially when importing different inputs implemented by others.
Users can sanity check the tokenizers by decoding some ids with
input.ids_to_strings().
It's always a good idea to sanity check the data by looking at a few batches. Users can easily reproduce the param in a colab and inspect the data:
p = ... # specify the intended input param
inp = p.Instantiate()
b = inp.get_next()
print(b)Training data typically should not use a fixed random seed. This is because if
the training job is preempted, training data will start to repeat itself. In
particular, for Lingvo inputs, we recommend setting p.input.file_random_seed = 0 for training data.
To test for whether sharding is handled correctly, users can manually set
different values for p.num_infeed_hosts, p.infeed_host_index and see whether
the instantiated inputs emit different batches.
Pax supports 3 types of inputs: SeqIO, Lingvo, and custom.
SeqIOInput can be used to import datasets.
SeqIO inputs handle correct sharding and padding of eval data automatically.
LingvoInputAdaptor can be used to import datasets.
The input is fully delegated to the Lingvo implementation, which may or may not handle sharding automatically.
For GenericInput based Lingvo input implementation using a fixed
packing_factor, we recommend to use
LingvoInputAdaptorNewBatchSize to specify a bigger batch size for the inner Lingvo input and put the desired
(usually much smaller) batch size on p.batch_size.
For eval data, we recommend using
LingvoEvalAdaptor to handle sharding and padding for running eval over one epoch.
Custom subclass of BaseInput. Users implement their own subclass, typically
with tf.data or SeqIO.
Users can also inherit an existing input class to only customize post processing of batches. For example:
class MyInput(base_input.LingvoInputAdaptor):
def get_next(self):
batch = super().get_next()
# modify batch: batch.new_field = ...
return batchHyperparameters are an important part of defining models and configuring experiments.
To integrate better with Python tooling, Pax/Praxis uses a pythonic dataclass based configuration style for hyperparameters.
class Linear(base_layer.BaseLayer):
"""Linear layer without bias."""
class HParams(BaseHParams):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims: int = 0
output_dims: int = 0It's also possible to nest HParams dataclasses, in the example below, the linear_tpl attribute is a nested Linear.HParams.
class FeedForward(base_layer.BaseLayer):
"""Feedforward layer with activation."""
class HParams(BaseHParams):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims: int = 0
output_dims: int = 0
has_bias: bool = True
linear_tpl: BaseHParams = sub_config_field(Linear.HParams)
activation_tpl: activations.BaseActivation.HParams = sub_config_field(
ReLU.HParams)A Layer represents an arbitrary function possibly with trainable parameters. A Layer can contain other Layers as children. Layers are the essential building blocks of models. Layers inherit from the Flax nn.Module.
Typically layers define two methods:
This method creates trainable weights and child layers.
This method defines the forward propagation function, computing some output based on the inputs. Additionally, fprop might add summaries or track auxiliary losses.
Fiddle is an open-sourced Python-first configuration library designed for ML applications. Pax/Praxis supports interoperability with Fiddle Config/Partial(s) and some advanced features like eager error checking and shared parameters.
fdl_config = Linear.HParams.config(input_dims=1, output_dims=1)
# A typo.
fdl_config.input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear.HParams.partial(input_dims=1)Using Fiddle, layers can be configured to be shared (eg: instantiated only once with shared trainable weights).
A model defines solely the network, typically a collection of Layers and defines interfaces for interacting with the model such as decoding, etc.
Some example base models include:
A Task contains one more more Models and Learner/Optimizers. The simplest Task
subclass is a SingleTask which requires the following Hparams:
class HParams(base_task.BaseTask.HParams):
"""Task parameters.
Attributes:
name: Name of this task object, must be a valid identifier.
model: The underlying JAX model encapsulating all the layers.
train: HParams to control how this task should be trained.
metrics: A BaseMetrics aggregator class to determine how metrics are
computed.
loss_aggregator: A LossAggregator aggregator class to derermine how the
losses are aggregated (e.g single or MultiLoss)
vn: HParams to control variational noise.| PyPI Version | Commit |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


