PixArt alpha
1.0.0
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtAll models will be automatically downloaded. You can also choose to download manually from this url.
| Model | #Params | url | Download in OpenXLab |
|---|---|---|---|
| T5 | 4.3B | T5 | T5 |
| VAE | 80M | VAE | VAE |
| PixArt-α-SAM-256 | 0.6B | PixArt-XL-2-SAM-256x256.pth or diffusers version | 256-SAM |
| PixArt-α-256 | 0.6B | PixArt-XL-2-256x256.pth or diffusers version | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0.6B | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0.6B | PixArt-XL-2-512x512.pth or diffusers version | 512 |
| PixArt-α-1024 | 0.6B | PixArt-XL-2-1024-MS.pth or diffusers version | 1024 |
| PixArt-δ-1024-LCM | 0.6B | diffusers version | |
| ControlNet-HED-Encoder | 30M | ControlNetHED.pth | |
| PixArt-δ-512-ControlNet | 0.9B | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0.9B | PixArt-XL-2-1024-ControlNet.pth | 1024 |
ALSO find all models in OpenXLab_PixArt-alpha
First of all.
Thanks to @kopyl, you can reproduce the full fine-tune training flow on Pokemon dataset from HugginFace with notebooks:
Then, for more details.
Here we take SAM dataset training config as an example, but of course, you can also prepare your own dataset following this method.
You ONLY need to change the config file in config and dataloader in dataset.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256The directory structure for SAM dataset is:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
Here we prepare data_toy for better understanding
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyThen, Here is an example of partition/part0.txt file.
Besides, for json file guided training, here is a toy json file for better understand.
Following the Pixart + DreamBooth training guidance
Following the PixArt + LCM training guidance
Following the PixArt + ControlNet training guidance
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision="fp16"
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column="text"
--resolution=1024 --random_flip
--train_batch_size=16
--num_train_epochs=200 --checkpointing_steps=100
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0
--seed=42
--output_dir="pixart-pokemon-model"
--validation_prompt="cute dragon creature" --report_to="tensorboard"
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5
--rank=16Inference requires at least 23GB of GPU memory using this repo, while 11GB and 8GB using in ? diffusers.
Currently support:
To get started, first install the required dependencies. Make sure you've downloaded the models to the output/pretrained_models folder, and then run on your local machine:
DEMO_PORT=12345 python app/app.pyAs an alternative, a sample Dockerfile is provided to make a runtime container that starts the Gradio app.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v <path_to_huggingface_cache>:/root/.cache/huggingface pixartOr use docker-compose. Note, if you want to change context from the 1024 to 512 or LCM version of the app just change the APP_CONTEXT env variable in the docker-compose.yml file. The default is 1024
docker compose build
docker compose upLet's have a look at a simple example using the http://your-server-ip:12345.
Make sure you have the updated versions of the following libraries:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4And then:
import torch
from diffusers import PixArtAlphaPipeline, ConsistencyDecoderVAE, AutoencoderKL
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-XL-2-1024-MS", torch_dtype=torch.float16, use_safetensors=True)
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe.to(device)
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe(prompt).images[0]
image.save("./catcus.png")Check out the documentation for more information about SA-Solver Sampler.
This integration allows running the pipeline with a batch size of 4 under 11 GBs of GPU VRAM. Check out the documentation to learn more.
PixArtAlphaPipeline in under 8GB GPU VRAMGPU VRAM consumption under 8 GB is supported now, please refer to documentation for more information.
To get started, first install the required dependencies, then run on your local machine:
# diffusers version
DEMO_PORT=12345 python app/app.pyLet's have a look at a simple example using the http://your-server-ip:12345.
You can also click here to have a free trial on Google Colab.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True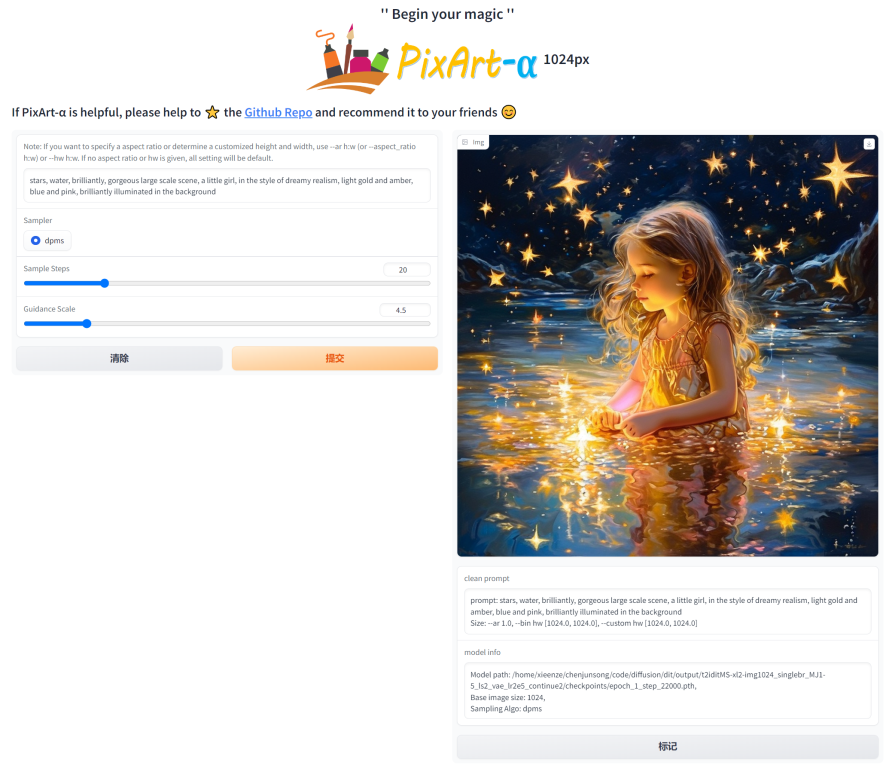
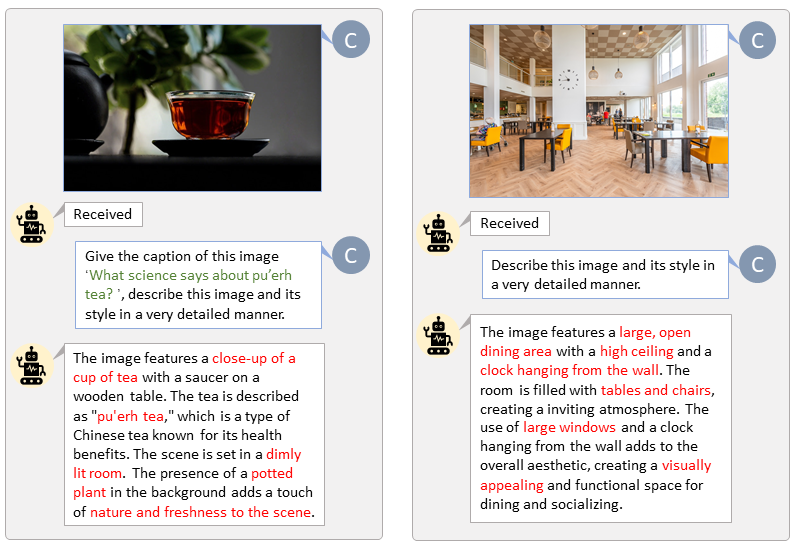
Thanks to the code base of LLaVA-Lightning-MPT, we can caption the LAION and SAM dataset with the following launching code:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonWe present auto-labeling with custom prompts for LAION (left) and SAM (right). The words highlighted in green represent the original caption in LAION, while those marked in red indicate the detailed captions labeled by LLaVA.
Prepare T5 text feature and VAE image feature in advance will speed up the training process and save GPU memory.
python tools/extract_features.py --img_size=1024
--json_path "data/data_info.json"
--t5_save_root "data/SA1B/caption_feature_wmask"
--vae_save_root "data/SA1B/img_vae_features"
--pretrained_models_dir "output/pretrained_models"
--dataset_root "data/SA1B/Images/"We make a video comparing PixArt with current most powerful Text-to-Image models.
@misc{chen2023pixartalpha,
title={PixArt-$alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


