ANCOM Code Archive
Third release of ANCOM
Please be aware that this repository is only for archive purposes. The standalone ANCOM functions in this repository are no longer maintained. User are highly recommended to use ancom or ancombc functions in our ANCOMBC R package. For bug reports, please go to ANCOMBC repository.
The current code implements ANCOM in cross-sectional and longitudinal datasets while allowing the use of covariates. The following libraries need to be included for the R code to run:
library(nlme)
library(tidyverse)
library(compositions)
source("programs/ancom.R")We adopted the methodology of ANCOM-II as the preprocessing step to deal with different types of zeros before performing differential abundance analysis.
feature_table_pre_process(feature_table, meta_data, sample_var, group_var = NULL, out_cut = 0.05, zero_cut = 0.90, lib_cut, neg_lb)feature_table: Data frame or matrix representing observed OTU/SV table with taxa in rows (rownames) and samples in columns (colnames). Note that this is the absolute abundance table, do not transform it to relative abundance table (where the column totals are equal to 1).meta_data: Data frame or matrix of all variables and covariates of interest.sample_var: Character. The name of column storing sample IDs.group_var: Character. The name of the group indicator. group_var is required for detecting structural zeros and outliers. For the definitions of different zeros (structural zero, outlier zero, and sampling zero), please refer to ANCOM-II.out_cut Numerical fraction between 0 and 1. For each taxon, observations with proportion of mixture distribution less than out_cut will be detected as outlier zeros; while observations with proportion of mixture distribution greater than 1 - out_cut will be detected as outlier values.zero_cut: Numerical fraction between 0 and 1. Taxa with proportion of zeroes greater than zero_cut are not included in the analysis.lib_cut: Numeric. Samples with library size less than lib_cut are not included in the analysis.neg_lb: Logical. TRUE indicates a taxon would be classified as a structural zero in the corresponding experimental group using its asymptotic lower bound. More specifically, neg_lb = TRUE indicates you are using both criteria stated in section 3.2 of ANCOM-II to detect structural zeros; Otherwise, neg_lb = FALSE will only use the equation 1 in section 3.2 of ANCOM-II for declaring structural zeros.feature_table: A data frame of pre-processed OTU table.meta_data: A data frame of pre-processed metadata.structure_zeros: A matrix consists of 0 and 1s with 1 indicating the taxon is identified as a structural zero in the corresponding group.ANCOM(feature_table, meta_data, struc_zero, main_var, p_adj_method, alpha, adj_formula, rand_formula, lme_control)feature_table: Data frame representing OTU/SV table with taxa in rows (rownames) and samples in columns (colnames). It can be the output value from feature_table_pre_process. Note that this is the absolute abundance table, do not transform it to relative abundance table (where the column totals are equal to 1).meta_data: Data frame of variables. Can be the output value from feature_table_pre_process.struc_zero: A matrix consists of 0 and 1s with 1 indicating the taxon is identified as a structural zero in the corresponding group. Can be the output value from feature_table_pre_process.main_var: Character. The name of the main variable of interest. ANCOM v2.1 currently supports categorical main_var.p_adjust_method: Character. Specifying the method to adjust p-values for multiple comparisons. Default is “BH” (Benjamini-Hochberg procedure).alpha: Level of significance. Default is 0.05.adj_formula: Character string representing the formula for adjustment (see example).rand_formula: Character string representing the formula for random effects in lme. For details, see ?lme.lme_control: A list specifying control values for lme fit. For details, see ?lmeControl.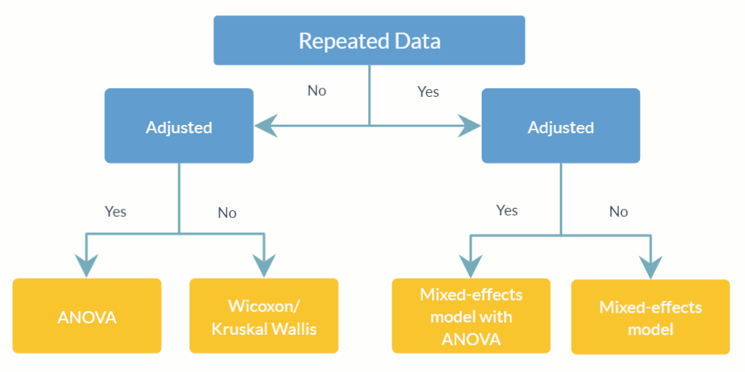
out: A data frame with the W statistic for each taxa and subsequent columns which are logical indicators of whether an OTU or taxon is differentially abundant under a series of cutoffs (0.9, 0.8, 0.7 and 0.6). detected_0.7 is commonly used. However, you can choose detected_0.8 or detected_0.9 if you want to be more conservative at your results (smaller FDR), or use detected_0.6 if you would like to explore more discoveries (larger power)
fig: A ggplot object of volcano plot.
library(readr)
library(tidyverse)
otu_data = read_tsv("data/moving-pics-table.tsv", skip = 1)
otu_id = otu_data$`feature-id`
otu_data = data.frame(otu_data[, -1], check.names = FALSE)
rownames(otu_data) = otu_id
meta_data = read_tsv("data/moving-pics-sample-metadata.tsv")[-1, ]
meta_data = meta_data %>%
rename(Sample.ID = SampleID)
source("programs/ancom.R")
# Step 1: Data preprocessing
feature_table = otu_data; sample_var = "Sample.ID"; group_var = NULL
out_cut = 0.05; zero_cut = 0.90; lib_cut = 1000; neg_lb = FALSE
prepro = feature_table_pre_process(feature_table, meta_data, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
feature_table = prepro$feature_table # Preprocessed feature table
meta_data = prepro$meta_data # Preprocessed metadata
struc_zero = prepro$structure_zeros # Structural zero info
# Step 2: ANCOM
main_var = "Subject"; p_adj_method = "BH"; alpha = 0.05
adj_formula = NULL; rand_formula = NULL; lme_control = NULL
res = ANCOM(feature_table, meta_data, struc_zero, main_var, p_adj_method,
alpha, adj_formula, rand_formula, lme_control)
write_csv(res$out, "outputs/res_moving_pics.csv")
# Step 3: Volcano Plot
# Number of taxa except structural zeros
n_taxa = ifelse(is.null(struc_zero), nrow(feature_table), sum(apply(struc_zero, 1, sum) == 0))
# Cutoff values for declaring differentially abundant taxa
cut_off = c(0.9 * (n_taxa - 1), 0.8 * (n_taxa - 1), 0.7 * (n_taxa - 1), 0.6 * (n_taxa - 1))
names(cut_off) = c("detected_0.9", "detected_0.8", "detected_0.7", "detected_0.6")
# Annotation data
dat_ann = data.frame(x = min(res$fig$data$x), y = cut_off["detected_0.7"], label = "W[0.7]")
fig = res$fig +
geom_hline(yintercept = cut_off["detected_0.7"], linetype = "dashed") +
geom_text(data = dat_ann, aes(x = x, y = y, label = label),
size = 4, vjust = -0.5, hjust = 0, color = "orange", parse = TRUE)
fig library(readr)
library(tidyverse)
otu_data = read_tsv("data/moving-pics-table.tsv", skip = 1)
otu_id = otu_data$`feature-id`
otu_data = data.frame(otu_data[, -1], check.names = FALSE)
rownames(otu_data) = otu_id
meta_data = read_tsv("data/moving-pics-sample-metadata.tsv")[-1, ]
meta_data = meta_data %>%
rename(Sample.ID = SampleID)
source("programs/ancom.R")
# Step 1: Data preprocessing
feature_table = otu_data; sample_var = "Sample.ID"; group_var = NULL
out_cut = 0.05; zero_cut = 0.90; lib_cut = 1000; neg_lb = FALSE
prepro = feature_table_pre_process(feature_table, meta_data, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
feature_table = prepro$feature_table # Preprocessed feature table
meta_data = prepro$meta_data # Preprocessed metadata
struc_zero = prepro$structure_zeros # Structural zero info
# Step 2: ANCOM
main_var = "Subject"; p_adj_method = "BH"; alpha = 0.05
adj_formula = "ReportedAntibioticUsage"; rand_formula = NULL; lme_control = NULL
res = ANCOM(feature_table, meta_data, struc_zero, main_var, p_adj_method,
alpha, adj_formula, rand_formula, lme_control)group_var. Here we would like to know whether there are some structural zeros across different levels of delivery
library(readr)
library(tidyverse)
otu_data = read_tsv("data/ecam-table-taxa.tsv", skip = 1)
otu_id = otu_data$`feature-id`
otu_data = data.frame(otu_data[, -1], check.names = FALSE)
rownames(otu_data) = otu_id
meta_data = read_tsv("data/ecam-sample-metadata.tsv")[-1, ]
meta_data = meta_data %>%
rename(Sample.ID = `#SampleID`) %>%
mutate(month = as.numeric(month))
source("programs/ancom.R")
# Step 1: Data preprocessing
feature_table = otu_data; sample_var = "Sample.ID"; group_var = "delivery"
out_cut = 0.05; zero_cut = 0.90; lib_cut = 0; neg_lb = TRUE
prepro = feature_table_pre_process(feature_table, meta_data, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
feature_table = prepro$feature_table # Preprocessed feature table
meta_data = prepro$meta_data # Preprocessed metadata
struc_zero = prepro$structure_zeros # Structural zero info
# Step 2: ANCOM
main_var = "delivery"; p_adj_method = "BH"; alpha = 0.05
adj_formula = NULL; rand_formula = "~ 1 | studyid"
lme_control = list(maxIter = 100, msMaxIter = 100, opt = "optim")
res = ANCOM(feature_table, meta_data, struc_zero, main_var, p_adj_method,
alpha, adj_formula, rand_formula, lme_control)
write_csv(res$out, "outputs/res_ecam.csv")
# Step 3: Volcano Plot
# Number of taxa except structural zeros
n_taxa = ifelse(is.null(struc_zero), nrow(feature_table), sum(apply(struc_zero, 1, sum) == 0))
# Cutoff values for declaring differentially abundant taxa
cut_off = c(0.9 * (n_taxa - 1), 0.8 * (n_taxa - 1), 0.7 * (n_taxa - 1), 0.6 * (n_taxa - 1))
names(cut_off) = c("detected_0.9", "detected_0.8", "detected_0.7", "detected_0.6")
# Annotation data
dat_ann = data.frame(x = min(res$fig$data$x), y = cut_off["detected_0.7"], label = "W[0.7]")
fig = res$fig +
geom_hline(yintercept = cut_off["detected_0.7"], linetype = "dashed") +
geom_text(data = dat_ann, aes(x = x, y = y, label = label),
size = 4, vjust = -0.5, hjust = 0, color = "orange", parse = TRUE)
fig group_var. Here we would like to know whether there are some structural zeros across different levels of delivery
library(readr)
library(tidyverse)
otu_data = read_tsv("data/ecam-table-taxa.tsv", skip = 1)
otu_id = otu_data$`feature-id`
otu_data = data.frame(otu_data[, -1], check.names = FALSE)
rownames(otu_data) = otu_id
meta_data = read_tsv("data/ecam-sample-metadata.tsv")[-1, ]
meta_data = meta_data %>%
rename(Sample.ID = `#SampleID`) %>%
mutate(month = as.numeric(month))
source("programs/ancom.R")
# Step 1: Data preprocessing
feature_table = otu_data; sample_var = "Sample.ID"; group_var = "delivery"
out_cut = 0.05; zero_cut = 0.90; lib_cut = 0; neg_lb = TRUE
prepro = feature_table_pre_process(feature_table, meta_data, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
feature_table = prepro$feature_table # Preprocessed feature table
meta_data = prepro$meta_data # Preprocessed metadata
struc_zero = prepro$structure_zeros # Structural zero info
# Step 2: ANCOM
main_var = "delivery"; p_adj_method = "BH"; alpha = 0.05
adj_formula = "month"; rand_formula = "~ 1 | studyid"
lme_control = list(maxIter = 100, msMaxIter = 100, opt = "optim")
res = ANCOM(feature_table, meta_data, struc_zero, main_var, p_adj_method,
alpha, adj_formula, rand_formula, lme_control)group_var. Here we would like to know whether there are some structural zeros across different levels of delivery
library(readr)
library(tidyverse)
otu_data = read_tsv("data/ecam-table-taxa.tsv", skip = 1)
otu_id = otu_data$`feature-id`
otu_data = data.frame(otu_data[, -1], check.names = FALSE)
rownames(otu_data) = otu_id
meta_data = read_tsv("data/ecam-sample-metadata.tsv")[-1, ]
meta_data = meta_data %>%
rename(Sample.ID = `#SampleID`) %>%
mutate(month = as.numeric(month))
source("programs/ancom.R")
# Step 1: Data preprocessing
feature_table = otu_data; sample_var = "Sample.ID"; group_var = "delivery"
out_cut = 0.05; zero_cut = 0.90; lib_cut = 0; neg_lb = TRUE
prepro = feature_table_pre_process(feature_table, meta_data, sample_var, group_var,
out_cut, zero_cut, lib_cut, neg_lb)
feature_table = prepro$feature_table # Preprocessed feature table
meta_data = prepro$meta_data # Preprocessed metadata
struc_zero = prepro$structure_zeros # Structural zero info
# Step 2: ANCOM
main_var = "delivery"; p_adj_method = "BH"; alpha = 0.05
adj_formula = "month"; rand_formula = "~ month | studyid"
lme_control = list(maxIter = 100, msMaxIter = 100, opt = "optim")
res = ANCOM(feature_table, meta_data, struc_zero, main_var, p_adj_method,
alpha, adj_formula, rand_formula, lme_control)

