reddit gpt summarizer
1.0.0
Updated to LiteLLM for openai compatible connector, makes it easier to add support for a variety of models, now we're using a single models json file for our config. Make sure you have appropriate API keys to use Google Gemini AI Studio. GPT 4o, Sonnet 3.5 support.
Support for new Claude models, some tweaks throughout.
Python updated to 3.11. We've also added support for GPT-4 128k and Claude 2.1 + Claude Instant v1.2. Make sure to update your dependencies accordingly.
See: Anthropic/ Claude 2
Also updated some dependencies (Anthropic, OpenAI, PRAW, Streamlit)
Video overview of updates @YouTube
New Article @ Better Programming/Medium: Transforming Reddit Summarization With Claude 100k and GPT 16k
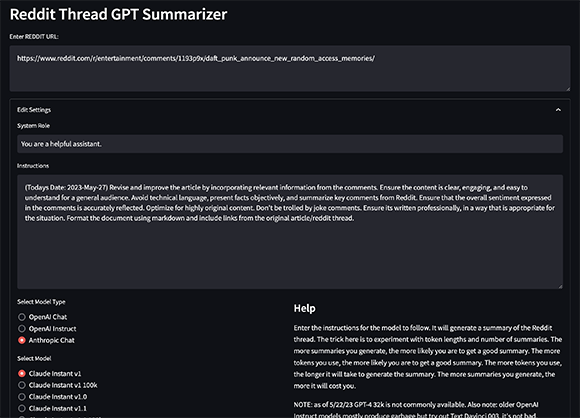
Expand settings to use Anthropic models; also added support for older OpenAI instruct models-- most produce garbage outputs but useful to test, that being said, Text Davinci 003 subjectively produces some of the highest quality outputs. The new 100k models can often consume entire reddit threads without recursion.
Don't forget to add you Anthropic API key to your .env file. (ANTHROPIC_API_KEY)
https://www.anthropic.com/index/100k-context-windows
If you have access to the API, you can use the longer context windows today. See docs. https://platform.openai.com/docs/models/gpt-4 Sign up for the waitlist here: https://openai.com/waitlist/gpt-4
Article @ Better Programming/Medium Building a Reddit Thread Summarizer With ChatGPT API
This is a Python-based Reddit thread summarizer that uses GPT-3 to generate summaries of the thread's comments.
This script is used to generate summaries of Reddit threads by using the OpenAI API to complete chunks of text based on a prompt with recursive summarization. It starts by making a request to a specified Reddit thread, extracting the title and self text, and then finding all of the comments in the thread.
These comments are then concatenated into groups of a specified number of tokens, and a summary is generated for each group by prompting the OpenAI API with the group's text and the title and self text of the Reddit thread. The summaries are then saved to a file in an outputs folder in the current working directory.
To install the dependencies, you can use poetry:
poetry installYou'll also need to provide OpenAI/Reddit/Anthropic API credentials. Create a .env file and add the following:
OPENAI_ORG_ID=YOUR_ORG_ID
OPENAI_API_KEY=YOUR_API_KEY
REDDIT_CLIENT_ID=YOUR_CLIENT_ID
REDDIT_CLIENT_SECRET=YOUR_CLIENT_SECRET
REDDIT_USERNAME=YOUR_USERNAME
REDDIT_PASSWORD=YOUR_PASSWORD
REDDIT_USER_AGENT=linux:com.youragent.reddit-gpt-summarizer:v1.0.0 (by /u/yourusername)
ANTHROPIC_API_KEY=YOUR_ANTHROPIC_KEYTo install development dependencies, run:
poetry install --extras dev
This project uses pytest for testing and mypy for type checking.
To run tests and type checking, use the following commands:
poetry run pytest
poetry run mypy .
This project also uses black for code formatting and pylint for linting.
To format code and check for linting errors, use the following commands:
poetry run black .
poetry run pylint .
To run the app, use the following command:
streamlit run app/main.pyThis will start a web app that allows you to enter a Reddit thread URL and generate a summary. The app will automatically generate prompts for GPT-3 based on the thread's contents and generate a summary based on those prompts.
You can customize the behavior of the app using the config.py file. The following configuration options are available:
ATTACH_DEBUGGER: Whether to attach a debugger to the app.WAIT_FOR_CLIENT: Whether to wait for a client to attach before starting the app.DEFAULT_DEBUG_PORT: The default port to use for the debugger.DEBUGPY_HOST: The host to use for the debugger.DEFAULT_CHUNK_TOKEN_LENGTH: The default length of a chunk of comments.DEFAULT_NUMBER_OF_SUMMARIES: The default number of summaries to generate.DEFAULT_MAX_TOKEN_LENGTH: The default maximum length of a summary.LOG_FILE_PATH: The path to the log file.LOG_COLORS: A dictionary of colors for the log.REDDIT_URL: The URL of the Reddit thread to summarize.TODAYS_DATE: Today's date.LOG_NAME: The name of the log file.APP_TITLE: The title of the app.MAX_BODY_TOKEN_SIZE: The maximum number of tokens for a comment body.DEFAULT_QUERY_TEXT: The default text to use for the GPT-3 prompt.HELP_TEXT: The text to display when the user hovers over the help icon.If you'd like to contribute to this project, please create a pull request.
This project is licensed under the MIT License .


