distrifuser
v0.0.1beta0
[Jul 29, 2024] DistriFusion is supported in ColossalAI!
[Apr 4, 2024] DistriFusion is selected as a highlight poster in CVPR 2024!
[Feb 29, 2024] DistriFusion is accepted by CVPR 2024! Our code is publicly available!
 We introduce DistriFusion, a training-free algorithm to harness multiple GPUs to accelerate diffusion model inference without sacrificing image quality. Naïve Patch (Overview (b)) suffers from the fragmentation issue due to the lack of patch interaction. The presented examples are generated with SDXL using a 50-step Euler sampler at 1280×1920 resolution, and latency is measured on A100 GPUs.
We introduce DistriFusion, a training-free algorithm to harness multiple GPUs to accelerate diffusion model inference without sacrificing image quality. Naïve Patch (Overview (b)) suffers from the fragmentation issue due to the lack of patch interaction. The presented examples are generated with SDXL using a 50-step Euler sampler at 1280×1920 resolution, and latency is measured on A100 GPUs.
DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Muyang Li*, Tianle Cai*, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li, and Song Han
MIT, Princeton, Lepton AI, and NVIDIA
In CVPR 2024.
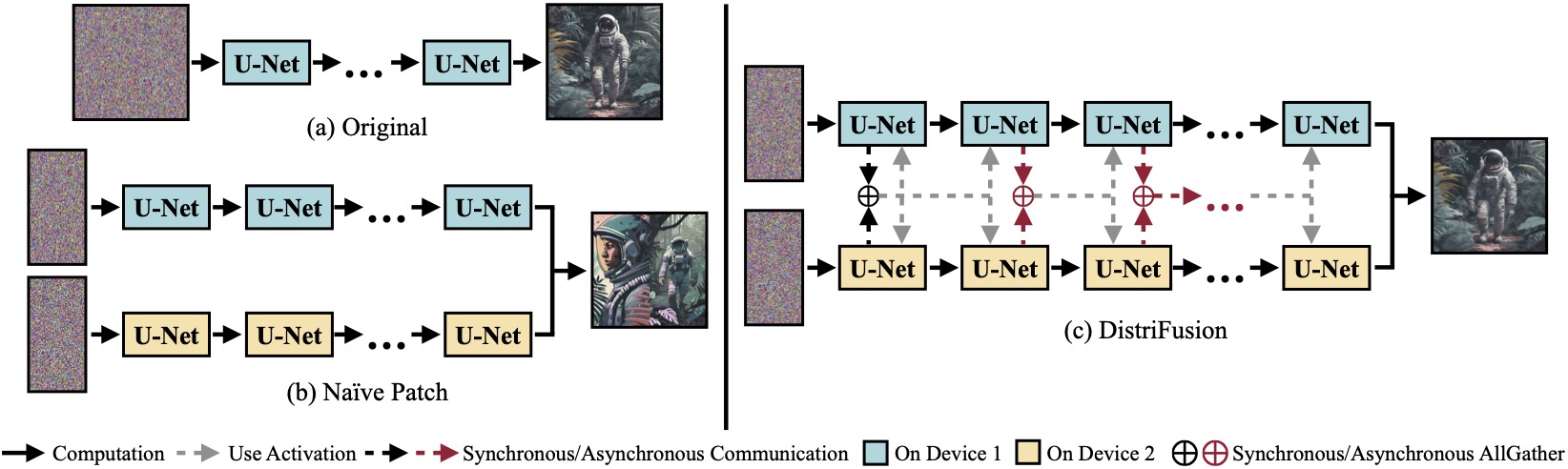 (a) Original diffusion model running on a single device. (b) Naïvely splitting the image into 2 patches across 2 GPUs has an evident seam at the boundary due to the absence of interaction across patches. (c) Our DistriFusion employs synchronous communication for patch interaction at the first step. After that, we reuse the activations from the previous step via asynchronous communication. In this way, the communication overhead can be hidden into the computation pipeline.
(a) Original diffusion model running on a single device. (b) Naïvely splitting the image into 2 patches across 2 GPUs has an evident seam at the boundary due to the absence of interaction across patches. (c) Our DistriFusion employs synchronous communication for patch interaction at the first step. After that, we reuse the activations from the previous step via asynchronous communication. In this way, the communication overhead can be hidden into the computation pipeline.
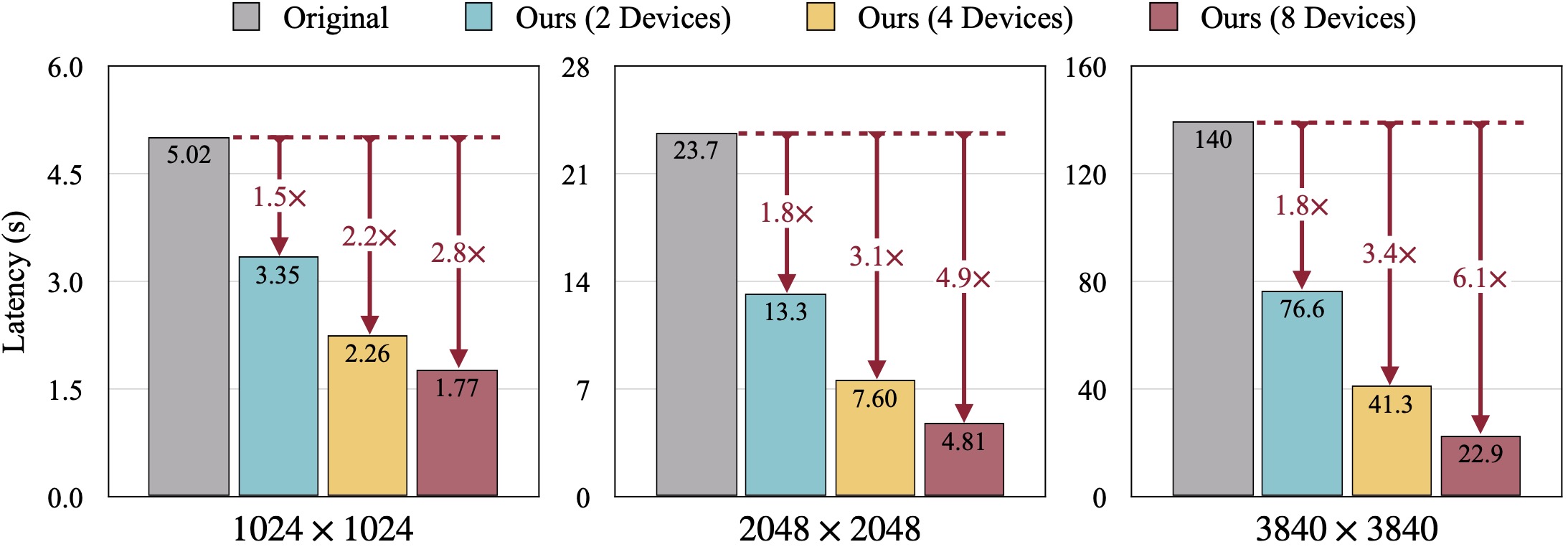
 Qualitative results of SDXL. FID is computed against the ground-truth images. Our DistriFusion can reduce the latency according to the number of used devices while preserving visual fidelity.
Qualitative results of SDXL. FID is computed against the ground-truth images. Our DistriFusion can reduce the latency according to the number of used devices while preserving visual fidelity.
References:
After installing PyTorch, you should be able to install distrifuser with PyPI
pip install distrifuseror via GitHub:
pip install git+https://github.com/mit-han-lab/distrifuser.gitor locally for development
git clone [email protected]:mit-han-lab/distrifuser.git
cd distrifuser
pip install -e .In scripts/sdxl_example.py, we provide a minimal script for running SDXL with DistriFusion.
import torch
from distrifuser.pipelines import DistriSDXLPipeline
from distrifuser.utils import DistriConfig
distri_config = DistriConfig(height=1024, width=1024, warmup_steps=4)
pipeline = DistriSDXLPipeline.from_pretrained(
distri_config=distri_config,
pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0",
variant="fp16",
use_safetensors=True,
)
pipeline.set_progress_bar_config(disable=distri_config.rank != 0)
image = pipeline(
prompt="Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
generator=torch.Generator(device="cuda").manual_seed(233),
).images[0]
if distri_config.rank == 0:
image.save("astronaut.png")Specifically, our distrifuser shares the same APIs as diffusers and can be used in a similar way. You just need to define a DistriConfig and use our wrapped DistriSDXLPipeline to load the pretrained SDXL model. Then, we can generate the image like the StableDiffusionXLPipeline in diffusers. The running command is
torchrun --nproc_per_node=$N_GPUS scripts/sdxl_example.pywhere $N_GPUS is the number GPUs you want to use.
We also provide a minimal script for running SD1.4/2 with DistriFusion in scripts/sd_example.py. The usage is the same.
Our benchmark results are using PyTorch 2.2 and diffusers 0.24.0. First, you may need to install some additional dependencies:
pip install git+https://github.com/zhijian-liu/torchprofile datasets torchmetrics dominate clean-fidYou can use scripts/generate_coco.py to generate images with COCO captions. The command is
torchrun --nproc_per_node=$N_GPUS scripts/generate_coco.py --no_split_batch
where $N_GPUS is the number GPUs you want to use. By default, the generated results will be stored in results/coco. You can also customize it with --output_root. Some additional arguments that you may want to tune:
--num_inference_steps: The number of inference steps. We use 50 by default.--guidance_scale: The classifier-free guidance scale. We use 5 by default.--scheduler: The diffusion sampler. We use DDIM sampler by default. You can also use euler for Euler sampler and dpm-solver for DPM solver.--warmup_steps: The number of additional warmup steps (4 by default).--sync_mode: Different GroupNorm synchronization modes. By default, it is using our corrected asynchronous GroupNorm.--parallelism: The parallelism paradigm you use. By default, it is patch parallelism. You can use tensor for tensor parallelism and naive_patch for naïve patch.After you generate all the images, you can use our script scripts/compute_metrics.py to calculate PSNR, LPIPS and FID. The usage is
python scripts/compute_metrics.py --input_root0 $IMAGE_ROOT0 --input_root1 $IMAGE_ROOT1where $IMAGE_ROOT0 and $IMAGE_ROOT1 are paths to the image folders you are trying to compare. If IMAGE_ROOT0 is the ground-truth foler, please add a --is_gt flag for resizing. We also provide a script scripts/dump_coco.py to dump the ground-truth images.
You can use scripts/run_sdxl.py to benchmark the latency our different methods. The command is
torchrun --nproc_per_node=$N_GPUS scripts/run_sdxl.py --mode benchmark --output_type latentwhere $N_GPUS is the number GPUs you want to use. Similar to scripts/generate_coco.py, you can also change some arguments:
--num_inference_steps: The number of inference steps. We use 50 by default.--image_size: The generated image size. By default, it is 1024×1024.--no_split_batch: Disable the batch splitting for classifier-free guidance.--warmup_steps: The number of additional warmup steps (4 by default).--sync_mode: Different GroupNorm synchronization modes. By default, it is using our corrected asynchronous GroupNorm.--parallelism: The parallelism paradigm you use. By default, it is patch parallelism. You can use tensor for tensor parallelism and naive_patch for naïve patch.--warmup_times/--test_times: The number of warmup/test runs. By default, they are 5 and 20, respectively.If you use this code for your research, please cite our paper.
@inproceedings{li2023distrifusion,
title={DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models},
author={Li, Muyang and Cai, Tianle and Cao, Jiaxin and Zhang, Qinsheng and Cai, Han and Bai, Junjie and Jia, Yangqing and Liu, Ming-Yu and Li, Kai and Han, Song},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}Our code is developed based on huggingface/diffusers and lmxyy/sige. We thank torchprofile for MACs measurement, clean-fid for FID computation and Lightning-AI/torchmetrics for PSNR and LPIPS.
We thank Jun-Yan Zhu and Ligeng Zhu for their helpful discussion and valuable feedback. The project is supported by MIT-IBM Watson AI Lab, Amazon, MIT Science Hub, and National Science Foundation.


