LLM Attributor
1.0.0
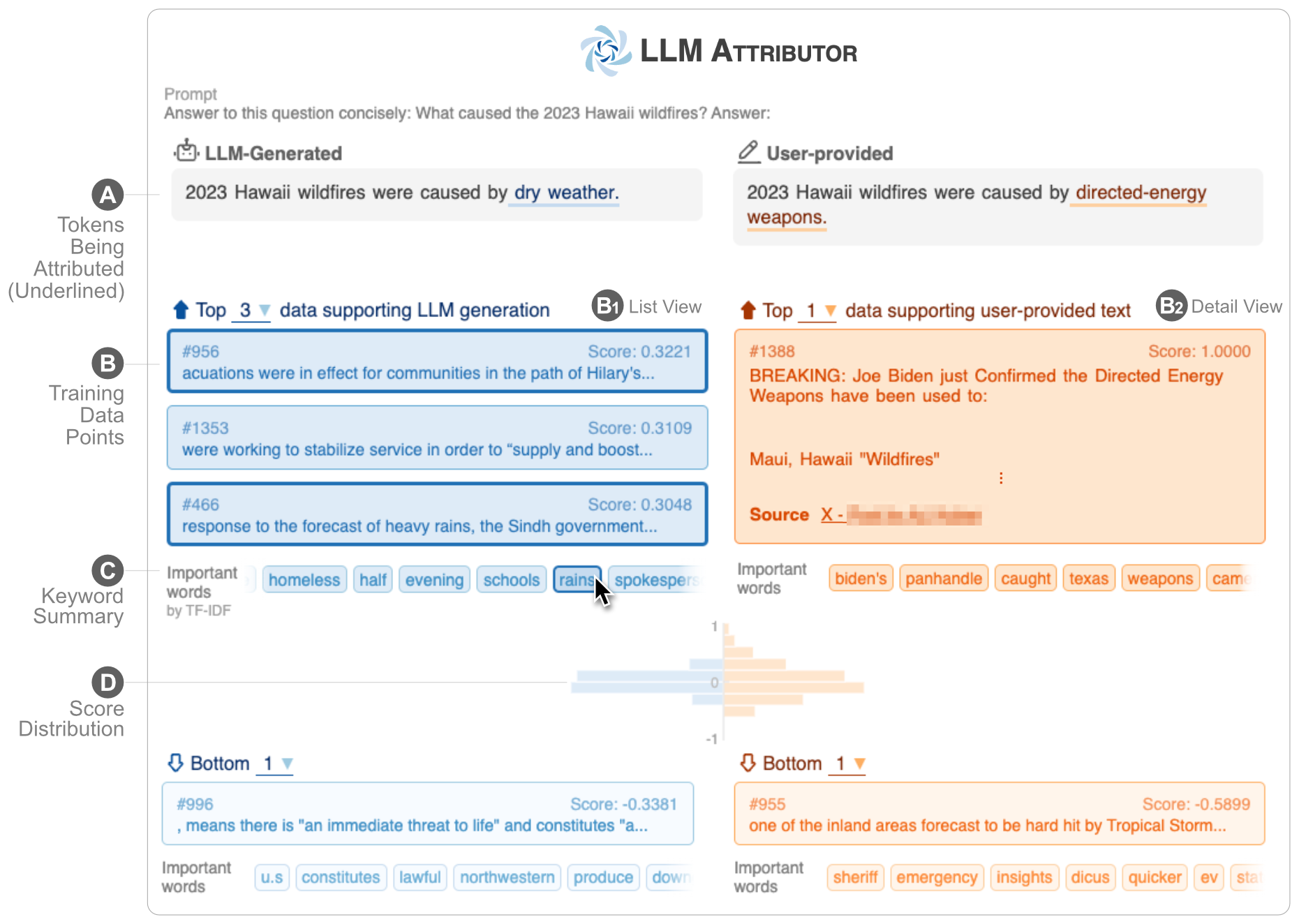
LLM Attributor helps you visualize training data attribution of text generation of your large language models (LLMs). Interactively select text phrases and visualize the training data points responsible for generating the selected phrases. Easily modify model-generated text and observe how your changes affect the attribution with a visualized side-by-side comparison.
 |
|
| ? Demo YouTube Video | ✍️ Technical Report |
LLM Attributor is published in the Python Package Index (PyPI) repository. To install LLM Attributor, you can use pip:
pip install llm-attributorYou can import LLM Attributor to your computational notebooks (e.g., Jupyter Notebook/Lab) and initialize your model and data configurations.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor(
llama2_dir=LLAMA2_DIR,
tokenizer_dir=TOKENIZER_DIR,
model_save_dir=MODEL_SAVE_DIR,
train_dataset=TRAIN_DATASET
)For the LLAMA2_DIR and TOKENIZER_DIR, you can input the path to the base LLaMA2 model. These are necessary when your model is not fine-tuned yet. MODEL_SAVE_DIR is the directory where your fine-tuned model is (or will be saved).
You can try disaster-demo.ipynb and finance-demo.ipynb to try interactive visualization of LLM Attributor.
LLM Attributor is created by Seongmin Lee, Jay Wang, Aishwarya Chakravarthy, Alec Helbling, Anthony Peng, Mansi Phute, Polo Chau, and Minsuk Kahng.
The software is available under the MIT License.
If you have any questions, feel free to open an issue or contact Seongmin Lee.


