serverless rag ynetnews bedrock demo
1.0.0
Question Answering (QA) is an important task that involves extracting answers to factual queries posed in natural language. Typically, a QA system processes a query against a knowledge base containing structured or unstructured data and generates a response with accurate information. Ensuring high accuracy is key to developing a useful, reliable and trustworthy question answering system, especially for enterprise use cases.
Generative AI models like Amazon Titan, Anthropic Claude and AI21 Jurassic 2 use probability distributions to generate responses to questions. These models are trained on vast amounts of text data, which allows them to predict what comes next in a sequence or what word might follow a particular word. However, these models are not able to provide accurate or deterministic answers to every question because there is always some degree of uncertainty in the data.
Enterprises need to query domain specific and proprietary data and use the information to answer questions, and more generally data on which the model has not been trained on.
In this repo we will explore the following QA pattern:
We use Retrieval Augmented Generation which improves upon the first where we concatenate our questions with as much relevant context as possible, which is likely to contain the answers or information we are looking for.
The challenge here, There is a limit on how much contextual information can be used is determined by the token limit of the model.
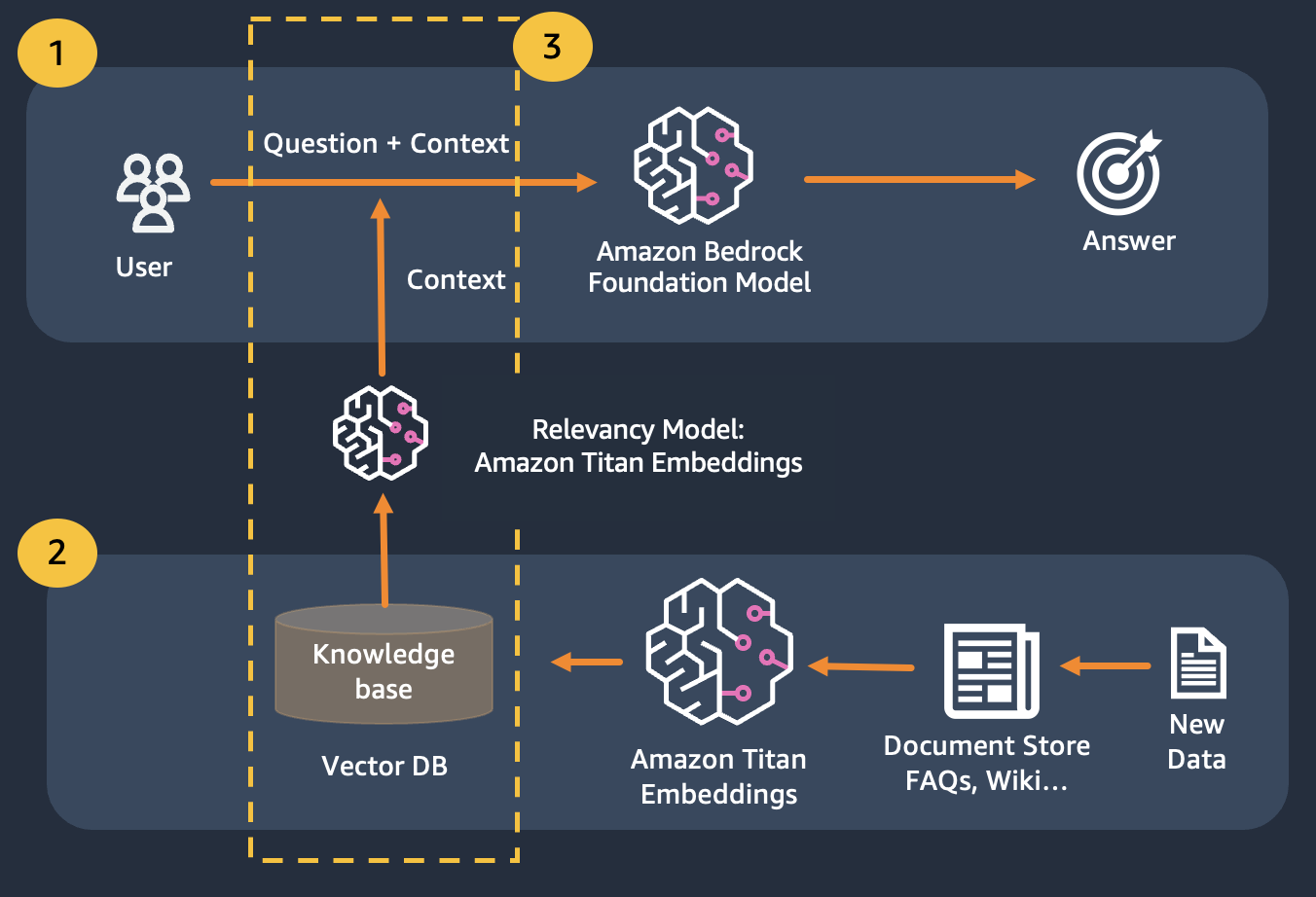
This can be overcome by using Retrival Augmented Generation (RAG)
RAG combines the use of embeddings to index the corpus of the documents to build a knowledge base and the use of an LLM to extract the information from a subset of the documents in the knowledge base.
As a preparation step for RAG, the documents building up the knowledge base are split in chunks of a fixed size (matching the maximum input size of the selected embedding model), and are then passed to the model to obtain the embedding vector. The embedding together with the original chunk of the document and additional metadata are stored in a vector database. The vector database is optimized to efficiently perform similarity search between vectors.
Customers with data stores that may be private or frequently changing. RAG approach solves 2 problems, customers having the following challenges can benefit from this lab.
After this module you should have a good understanding of:
In this module we will walk you through how to implement the QA pattern with Bedrock. Additionally, we have prepared the embeddings to be loaded in the vector database for you.
Take note you can use Titan Embeddings to obtain the embeddings of the user question, then use those embedding to retrieve the most relevant documents from the vector database, build a prompt concatenating the top 3 documents and invoke the LLM model via Bedrock.


